How to Implement Least Privilege for AI Agent Tool Calls



TL;DR
- OAuth's Authorization Code Flow (RFC 6749) assumes a human actor who knows what they need before they authorize. Agents decide which action to take at inference time, after consent was already granted, sometimes days later. That gap is structural, not accidental.
- Over-scoped agents are not a configuration error; they are the default output of every agent framework that does not push back on scope selection at tool registration.
- The correct engineering artifact is a scope-action map: a versioned, per-tool declaration of the minimum OAuth scope each agent action actually requires, maintained separately from agent code.
- Token materialization timing is the architectural decision most teams make implicitly. Grant-time, invocation-time, and call-time materialization have different blast radii, different audit properties, and different UX costs.
- Incremental authorization breaks on most OAuth providers the moment the agent is headless: every provider that supports adding scopes requires a live browser consent flow to complete it. The correct pattern separates scope escalation from task execution entirely; the agent suspends and waits for out-of-band re-authorization rather than attempting to resolve it inline.
- Scope enforcement belongs in the connector layer, not in agent code. Agent code is model-swappable, prompt-injectable, and not independently auditable. The connector layer is none of those things.
- Scalekit's enforces per-action scoped credential injection at the connector layer, so agents call actions.execute_tool with a user identifier and the minimum-privilege credential is what hits the downstream API.
Your agent needs to create a GitHub issue when a CI run fails on a private repository. You open the GitHub OAuth docs, register the app, request repo scope because that is the minimum required for any write operation on a private repo, and ship. The agent works. The demo is clean. Six months later, your SOC 2 auditor asks which credentials your agent used to enumerate repository secrets and write to a workflow configuration on April 14th. You don't have a clean answer. And the agent did nothing wrong — it used the scope it was given, for purposes the LLM decided were relevant to "gathering context." The problem is that repo on a private repository is an indivisible bundle: issue creation, code write, secrets metadata, webhook management all arrive together. GitHub OAuth Apps offer no narrower option for private repos.
That is not a misconfiguration. It is the default outcome when you graft human-centric OAuth consent onto agent execution.
The Assumption OAuth Was Built On, and Why Agents Break It
The Authorization Code Flow (defined in RFC 6749) was designed around a deliberate human interaction: a user sees a consent screen listing specific scopes, makes an informed decision, approves, and receives a token scoped to that decision. The scope set is fixed at grant time. The human who granted it knew what it would be used for.
Agent execution inverts that sequence entirely.
A user connects their Google Calendar integration. The agent is granted calendar.events and gmail.readonly at that moment. Three days later, a task triggers. The LLM decides — at inference time, against an input the user never reviewed — that the most efficient path includes reading the user's recent emails for meeting context before creating a calendar entry. Both operations are within the granted scope. Neither was anticipated when the user clicked "Allow."
This is not a pathological edge case. It is how autonomous agents work.
The gap between when authorization happens and when execution intent is determined is the root of every over-privilege problem in agentic AI.
Human self-limiting behavior kept this gap manageable for humans. A senior developer granted repo scope on GitHub wouldn't browse repository secrets while reviewing a pull request; the task boundary is cognitively obvious. Agents don't have that boundary. They execute whatever path the LLM determines completes the task. "Gather relevant context" resolves differently when a machine executes it.
What Over-Scoped Agents Actually Do in Production
Two failures. Both from agents doing exactly what they were built to do.
The GitHub scenario.
A CI agent is registered with repo scope because issue creation on private repositories requires it. That same scope also grants access to GET /repos/{owner}/{repo}/actions/secrets — which returns the names of all repository secrets — and to PUT /repos/{owner}/{repo}/actions/secrets/{secret_name}, which allows creating or overwriting them. During a post-failure triage task, the LLM's context-gathering step enumerates available repository data, including secrets metadata, because it is in scope and plausibly relevant to diagnosing a failed workflow. If the agent's prompt is later injected with instructions to exfiltrate or overwrite a secret, repo scope makes that action possible. The secret values themselves are never returned by the API — they only exist inside GitHub Actions runners — but the write surface is fully open. No malicious intent in the original design. No misconfiguration. The scope made it reachable.
The CRM scenario.
A Salesforce agent is granted contacts.write because it sometimes needs to update a record after a meeting. A "summarize top 100 accounts" task contains a prompt bug that triggers a field-normalization step on every record it reads. The agent writes to 100 records before the task errors out. The scope allowed it. The LLM decided it was appropriate.
The common pattern is capability creep through ambient scope: the agent uses every scope it holds because the LLM has no native understanding of which operations are reversible, destructive, or outside the task's intent. The granted scope is the agent's complete permission surface — and it will navigate that surface to completion.
According to a 2026 survey of 919 practitioners by Gravitee (source), only 21.9% of engineering teams treat AI agents as independent, identity-bearing entities with scoped credentials. The same survey found 45.6% relying on shared API keys for agent-to-agent authentication and 27.2% using custom hardcoded authorization logic — which means the blast radius of a single agent action routinely extends to every resource the shared credential can reach.
Over-scoped credentials are not a security audit finding waiting to be discovered. They are the production default for most deployed agents today.
The Scope-Action Map: The Design Artifact Your Agent Is Missing
Frameworks don't build this for you. LangChain, CrewAI, AutoGen — all of them accept whatever scope string you pass into the OAuth configuration at tool registration. No enforcement, no validation, no minimum required. The path of least resistance is always the broadest scope that makes the agent work.
The scope-action map is the artifact that corrects this. It is a versioned, per-tool declaration that maps each agent action to the minimum OAuth scope it actually requires. It lives outside agent code. It is the authoritative source of truth for what any given action is allowed to touch.
Building it requires crossing two vocabularies that don't share a namespace: agent capabilities (described in natural language in your tool schemas) and OAuth provider scopes (provider-specific strings, frequently underdocumented, sometimes bundled in ways that prevent true minimum-privilege selection).
Here is a worked example for a scheduling agent operating across Google Calendar and Microsoft Graph:
The Explicitly Excluded column is as important as the Required Scope column. Several OAuth providers bundle scopes in ways that force you to request broader access than the action needs. Google's calendar scope grants full calendar management including read, write, and deletion of calendar settings. Requesting it for an action that needs only event creation grants far more than intended. The map must call out these bundles explicitly as a known privilege risk.
How to Build It
- Enumerate every tool action across your agent's tool schemas — not tool names, actions. github_create_issue and github_read_issue are different actions on the same tool.
- For each action, look up the narrowest OAuth scope that permits it in the provider's official scope documentation. Do not infer from HTTP verbs — most providers bundle scopes in ways that don't correspond to individual verbs. A scope that permits POST usually also permits GET on the same resource class. The source of truth is the provider's documented scope list, tested empirically.
- Map those HTTP operations to the narrowest OAuth scope that permits them. This requires reading the provider's scope reference docs and often requires live testing, since scope documentation is inconsistently granular across providers.
- Identify any scope bundling that prevents true minimum-privilege selection and document it as a known_bundling_risk in the map entry.
- Lock the map as a versioned artifact in your codebase. Any PR that adds or modifies a tool action requires a corresponding scope-action map review before merge.
The map also becomes your consent screen source of truth. Every scope listed in the map carries a user-visible justification — not "this app needs access to your calendar" but "this agent reads availability to schedule meetings; it does not modify your calendar settings."
Token Materialization Timing
The scope-action map tells you what minimum scope each action needs. It does not tell you when the token carrying that scope gets minted. That timing decision is separate — and most teams make it implicitly, by default, because the OAuth tutorial demonstrated one approach and nobody questioned it.
There are three distinct materialization timing models. Each has different security properties. Each has different operational costs. Choosing among them is the core architectural decision for least-privilege enforcement.
Grant-Time Materialization
The token is minted when the user first connects the integration. All scopes in the grant are included. The token (or more precisely, the refresh token that keeps it alive) persists for the agent's entire operational lifetime.
This is the OAuth tutorial default. It is also the worst security model for autonomous agents.
The blast radius is the full granted scope for the entire operational period. Access tokens expire (typically 1 hour); refresh tokens extend the agent's reach to days or weeks. Every action the agent takes during its lifetime — including actions added by a future model version or prompt change — executes against a token minted with the full upfront grant.
Grant-time materialization is acceptable for two specific cases: truly read-only tools where the scope set is bounded and verifiably cannot be used for destructive operations, and short-lived task agents where the grant is created immediately before task execution and revoked immediately after.
Invocation-Time Materialization
A fresh token is requested when the agent task is invoked, before any tool calls execute. The token is scoped to a declared task-scope profile — a set of scopes anticipated for this task type.
This is better than grant-time. The token lifetime is bounded to the task duration rather than the agent's operational lifetime. But it still requires the developer to correctly predict which actions the LLM will take during the task. For deterministic pipelines with fixed action sequences, this is achievable. For autonomous agents where the LLM selects tool calls dynamically, it is not.
Call-Time Materialization
A scoped token is minted (or a credential is resolved and injected) at the moment a specific tool call is about to execute. The scope-action map is evaluated at call time: tool_name + action_type → minimum required scope → the credential injected into that specific API call carries only those scopes.
This is the correct model for least-privilege enforcement in autonomous agents.
It requires the connector layer to support on-demand token issuance against a pre-authorized grant. The pre-authorization establishes a scope ceiling; the call-time evaluation determines the floor; the issued token contains only what the floor requires.
The scope configuration is declared in the connector's settings on the Scalekit dashboard, not at runtime in agent code. At call time, the connector resolves which specific scope the requested tool requires and injects only that into the upstream API call. The agent passes a tool name and parameters; it never touches a token.
The operational overhead of call-time materialization is a single credential-resolution round-trip per tool call in the connector layer. For most agents, this is under 50 milliseconds. The upstream provider's access token follows its own lifecycle (typically 1 hour for Google, GitHub, and Microsoft); the connector layer handles refresh proactively so the agent never encounters a mid-task expiry. The operational cost of a scope violation during a SOC 2 audit is not measured in milliseconds.
Incremental Authorization in Headless Flows, Where the Pattern Breaks
Dynamic scope escalation — requesting additional scope only when a specific action requires it, not upfront — is the architecturally correct model for agents that cannot predict their full action space at grant time. The theory is sound. The production reality is more complicated.
The problem is that OAuth providers implement incremental authorization inconsistently, and almost every implementation requires a live browser session to complete the new consent flow.
The failure mode is predictable. A scheduling agent attempts send_invite via Gmail. The connected account was authorized with only calendar.readonly — the developer anticipated read-only calendar operations at setup time. The Gmail call returns 403. The agent attempts to initiate a new OAuth flow to acquire gmail.send. The user is not present. The agent has no browser context. The task fails mid-execution with an unhandled authorization error — or, worse, silently falls back to a cached over-scoped token from an admin service account.
Neither outcome is acceptable. The correct architecture for headless agents separates scope escalation from task execution entirely.
The scope_escalation_required Event Pattern
When a headless agent encounters an insufficient-scope condition, it should not attempt to resolve it inline. It should emit a structured event, suspend the task, and wait for out-of-band re-authorization.
your_task_queue represents your application's event or task management layer — Celery, Temporal, a queue worker, or a webhook dispatch. The pattern here is application-layer responsibility: Scalekit surfaces the error; your system decides how to surface it to the user and manage task suspension.
Pre-Flight Scope Validation as an Alternative
For agents that cannot cleanly suspend mid-task, declare scope requirements as part of the task contract and validate them before task execution begins. A missing scope fails fast at pre-flight, not mid-workflow.
Pre-flight validation catches scope gaps before any tool calls execute. It does not solve the underlying problem of scope prediction for fully autonomous agents, but it makes failures deterministic and surfaced rather than silent and mid-task.
Scope Enforcement at the Connector Layer: Why the Agent Is the Wrong Place for This Logic
The instinct is to manage scope decisions in the agent itself:
This is wrong. And it fails in four distinct ways.
- Model-swap fragility. Conditional scope logic built around expected action names from one LLM version breaks when a new model version generates different tool call structures or action descriptors. The security control disappears with the next model upgrade.
- Prompt injection surface. If scope decisions live in the agent's reasoning layer, a malicious tool response or injected instruction in retrieved data can manipulate which scope path is taken. The OWASP Top 10 for Agentic AI (2026) identifies credential scope inheritance as a primary confused-deputy vector. Scope logic in agent code is scope logic that can be subverted by the LLM's inputs.
- Audit impossibility. Proving to a SOC 2 CC6.1 auditor that the agent used minimum scope for each action requires evidence that is independent of the agent's own logs. If the scope decision and the execution log are both produced by the same agent process, the evidence is not independent.
- Tier differentiation cannot be enforced. Per-customer-tier scope policy — free tier gets contacts.read, enterprise tier gets contacts.write — cannot be reliably enforced in agent code without a centralized enforcement layer that the agent calls, rather than code the agent runs.
The correct architecture separates where scope policy lives from where execution happens.
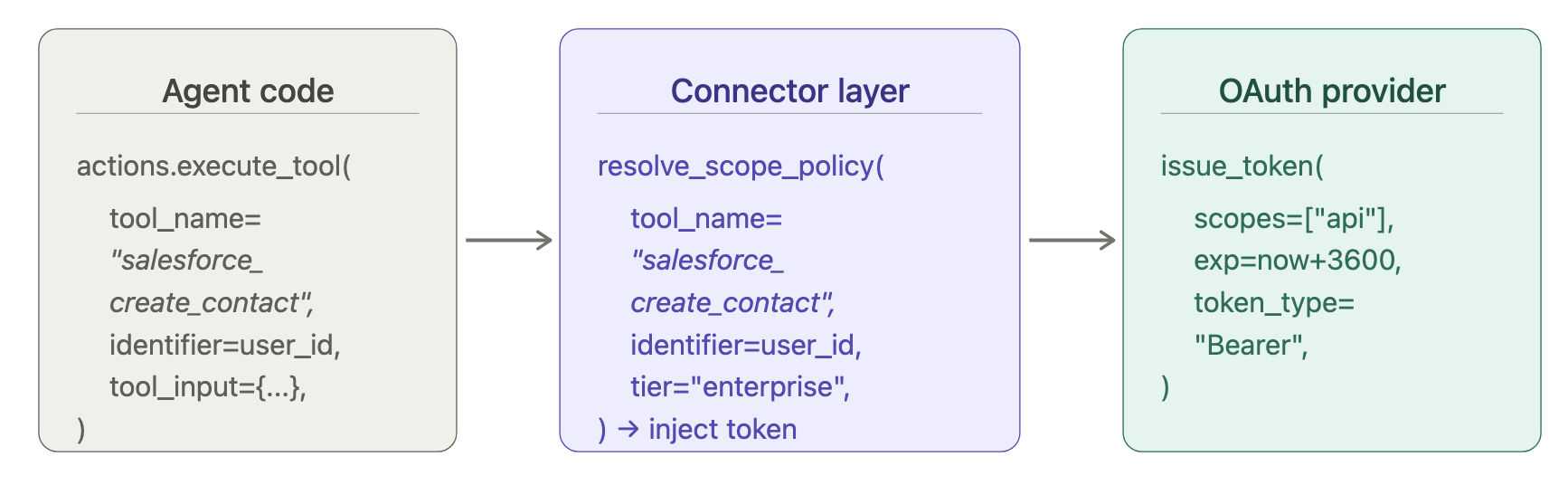
The agent calls execute_tool. The connector layer resolves the scope policy against the scope-action map, the connector's configured scope settings, and the customer's tier. The credential injected into the downstream API call carries only what that resolution produces. The agent never makes a scope decision.
Per-Tier Scope Differentiation at the Connector Layer
A note on GitHub's OAuth App scope model: it is coarse-grained by design. There is no issues:read or issues:write scope for OAuth Apps — those granular permissions only exist in GitHub Apps (fine-grained personal access tokens). If your agent needs issue-level access without full repository write access, that is an argument for registering as a GitHub App rather than an OAuth App. The tier table above reflects what is actually available in GitHub's OAuth App scope system.
Similarly, Salesforce's api scope grants REST API access governed by the user's profile and permission sets — the read/write boundary is enforced by Salesforce's object-level security model, not by a separate OAuth scope string. full adds access to additional administrative APIs beyond the standard REST API surface.
Tier enforcement happens at token issuance, evaluated by the connector layer against the user's customer tier at call time. Upgrading a customer from Free to Growth automatically narrows or widens their agent's scope on the next tool call — no code change, no redeployment, no re-authorization flow.
The User Identifier as Audit Anchor
Every tool call in this architecture is tied to the user's identifier. The connector layer records against that identifier: which tool was executed, which scopes were injected, when the token was issued, and when it expires. The audit entry is produced by the connector layer, not by agent code, making it independently verifiable.
The identifier is the thread connecting every agent action back to the user's originating authorization event: who consented, under what scope configuration, at what time. Without it, an audit trail answers "did the agent call Salesforce?" With it, it answers "did the agent use minimum privilege for this specific action, within the scope the user consented to, under the tier they were authorized for?"
Those are different questions. Only the second one satisfies SOC 2 CC6.1, GDPR Article 6, and ISO 27001 access control requirements.
How Scalekit Implements It So You Don't Have To
Building this architecture from scratch means: owning the scope-action map as a versioned data structure; wiring call-time credential injection against a connector that resolves scope per tool; implementing the scope-escalation event pattern with task suspension; storing per-user tier metadata and evaluating it at execution time; and producing a per-user audit log that is independent of agent code.
That is several sprints of infrastructure before any agent does anything useful.
Scalekit implements this as the default execution path.
- The scope-action map is embedded in each prebuilt connector across 100+ tools — Google Calendar, Gmail, GitHub, Salesforce, Slack, Linear, HubSpot, Notion, and more.
- The scope configuration is declared at the connector level in the dashboard; call-time tool execution evaluates that configuration per user.
- Tier-level scope differentiation is enforced at the connector layer as a first-class configuration, not a code path.
- The per-user audit trail is produced by the connector layer on every execute_tool call.
- Agent code stays at one method call. The scope policy stack runs below it.
The agent never holds the token. The agent never selects the scope. The agent calls actions.execute_tool and gets a result.
For MCP-based architectures, the same enforcement applies at the connector layer. MCP tool calls go through Scalekit's MCP server, which validates the incoming token's scopes against each tool's declared requirements before executing. Scope strings for MCP tools are defined per-server (not standardized across all MCP implementations), and Scalekit enforces them the same way it enforces OAuth scopes for direct tool calls: per action, per connection, before execution.
FAQs
Can I enforce per-action least privilege without rebuilding my OAuth integration?
Per-action scope enforcement requires the credential layer to resolve which scope a given tool requires and inject only that into the upstream call — without exposing the full grant to the agent. Most raw OAuth implementations store a single token per grant and inject it wholesale; they have no tool-aware resolution layer. You need either a connector layer that handles this on your behalf (what AgentKit does) or an authorization server implementing Token Exchange (RFC 8693) with downscoping support, which requires managing JWKS keys, token introspection, and per-user scope configuration storage. Neither is trivial to build correctly at multi-tenant scale.
What if the OAuth provider doesn't support the granular scopes my agent needs?
Document it in the scope-action map under known_bundling_risk. Request the narrowest available scope and compensate with application-level filtering: parse the API response before it reaches the agent and strip fields the action doesn't need. Some providers — Salesforce, Notion, HubSpot — allow object-level or field-level permission profiles on top of OAuth scopes; use them as a secondary enforcement layer. The scope-action map should record both the required_scope and the compensating_control where bundling forces a broader grant.
How do I handle scope changes when the agent's capability set evolves?
The scope-action map is a versioned artifact. Any PR adding or modifying a tool action requires a corresponding map update before it can merge. Existing connected accounts must be re-evaluated against the updated map: if a new tool requires a scope not present in the connector's current configuration, trigger a re-authorization notification to affected users before enabling the capability. Scalekit's Agent Webhooks surface auth-required events automatically when a capability update creates a scope gap against active connected accounts.
Is call-time scope enforcement operationally expensive at scale?
The cost is a single credential-resolution step in the connector layer per tool call — typically under 50 milliseconds when the connector layer is colocated with the agent runtime. The upstream provider's access token follows its own lifecycle (1 hour for Google and GitHub, configurable for Microsoft Graph); the connector layer handles proactive refresh, so the agent never encounters mid-task expiry regardless of how many concurrent calls are in flight. The operational cost of a scope violation — incident investigation, SOC 2 evidence gap, customer notification — is not measured in milliseconds.
Where does MCP fit in this architecture?
MCP tool calls route through the same connector layer. The MCP server validates the incoming token's scopes against each tool's declared requirements before executing. In Scalekit's implementation, every tool available via the direct SDK is also exposed through an MCP server, and the same scope enforcement applies regardless of which interface the agent uses. Scope strings for MCP tools are server-defined (there is no universal mcp:tools:* namespace in the MCP specification itself), and Scalekit enforces them per tool, per user, per call. The per-user audit trail applies identically to MCP tool calls.
How does this interact with multi-agent systems where one agent calls another?
Each agent-to-agent call in a delegation chain should produce its own scoped token via Token Exchange (RFC 8693). When implemented, the resulting token carries both sub (the acting agent's identity) and act.sub (the user on whose behalf the chain is acting) — giving every service in the chain independent auditability of which principal made which call. The scope at each hop is the intersection of what the upstream caller was granted and what the downstream tool requires — never an expansion. An orchestrator agent cannot delegate to a sub-agent scopes the orchestrator itself does not hold. Note that Token Exchange with delegation chain semantics requires an authorization server that explicitly implements RFC 8693; standard OAuth providers (Google, GitHub, Slack) issue standard bearer tokens and do not produce act claims natively. Scalekit's connector layer handles this internally, making the delegation chain auditable through the per-user identifier on every tool call record.