Who Holds the Token? Credential Ownership Across Agent Tool-Calling Patterns


TL;DR
- The integration pattern you choose - direct function calling, MCP server, or managed connector - determines where access_token and refresh_token physically live. That decision happens before you write a single line of auth code.
- Pattern 1 (agent owns the token): The full OAuth lifecycle - proactive refresh, concurrent refresh locking, revocation detection, per-tenant isolation, audit attribution - belongs to the agent developer. Every failure class in that list will eventually hit production.
- Pattern 2 (MCP server owns the token): Credential problems relocate to the MCP server process. They do not disappear. Additionally, MCP introduces a second auth boundary - agent → MCP server - that is frequently left unsecured. The outbound boundary (MCP → downstream API) is almost always Pattern 1 with a different owner.
- Pattern 3 (vault owns the token): The access_token and refresh_token never exist in agent runtime memory or LLM context. The vault owns refresh, rotation, revocation, and audit attribution as infrastructure primitives. The agent calls a tool and receives a result.
- Microsoft Entra Agent ID, Microsoft Foundry Agent Service, and Google ADK authentication guidance converge independently on the same principle: credentials must not reside in agent operating memory.
- Choosing an integration pattern without understanding credential ownership means discovering your auth architecture in your first production incident.

Three parallel agent threads. One shared refresh_token. Token rotation enabled on Slack.
At 2:47am, all three threads detect an expired access_token simultaneously. All three call the OAuth token endpoint with the same refresh_token. OAuth refresh tokens are single-use per the spec (RFC 6749 §6). The first thread succeeds and receives a new access_token + refresh_token. Threads two and three receive invalid_grant. They fail silently - no exception bubbled, no alert fired. The workflow continues. Half the downstream tool calls are dropped.
The investigation takes four days. The logs show 401 Unauthorized on a handful of Slack API calls. They don't show why - because the authentication layer lived inside the agent process, and the agent process had no structured way to record which thread held which credential at which moment.
This isn't a rare edge case. It's the documented failure mode of any architecture where the agent process owns the refresh_token. And the decision that put the token there was made weeks earlier - when an engineer chose a tool-calling integration pattern and treated it as a developer experience decision rather than an auth architecture decision.
The Decision Agent Developers Don't Realize They're Making
When AI/ML engineers evaluate how to connect an AI agent to external tools, the comparison usually looks like this:
- Direct function calling: Low setup cost, full control, fits any LLM SDK
- MCP server: Standardized tool registry, multi-client support, framework-agnostic
- Managed connector layer: Prebuilt integrations, abstracted auth, faster time-to-tool
None of those framings are wrong. But they omit the most consequential dimension: where does the OAuth credential live, and who is responsible for everything that can go wrong with it?
The integration pattern is a credential ownership decision. Most teams treat it as a developer experience decision.
Every agent that calls an external API needs credentials. Those credentials have a lifecycle: they are issued, they expire, they rotate, they get revoked, they need to be audited. Somebody has to own that lifecycle. The integration pattern decides who.
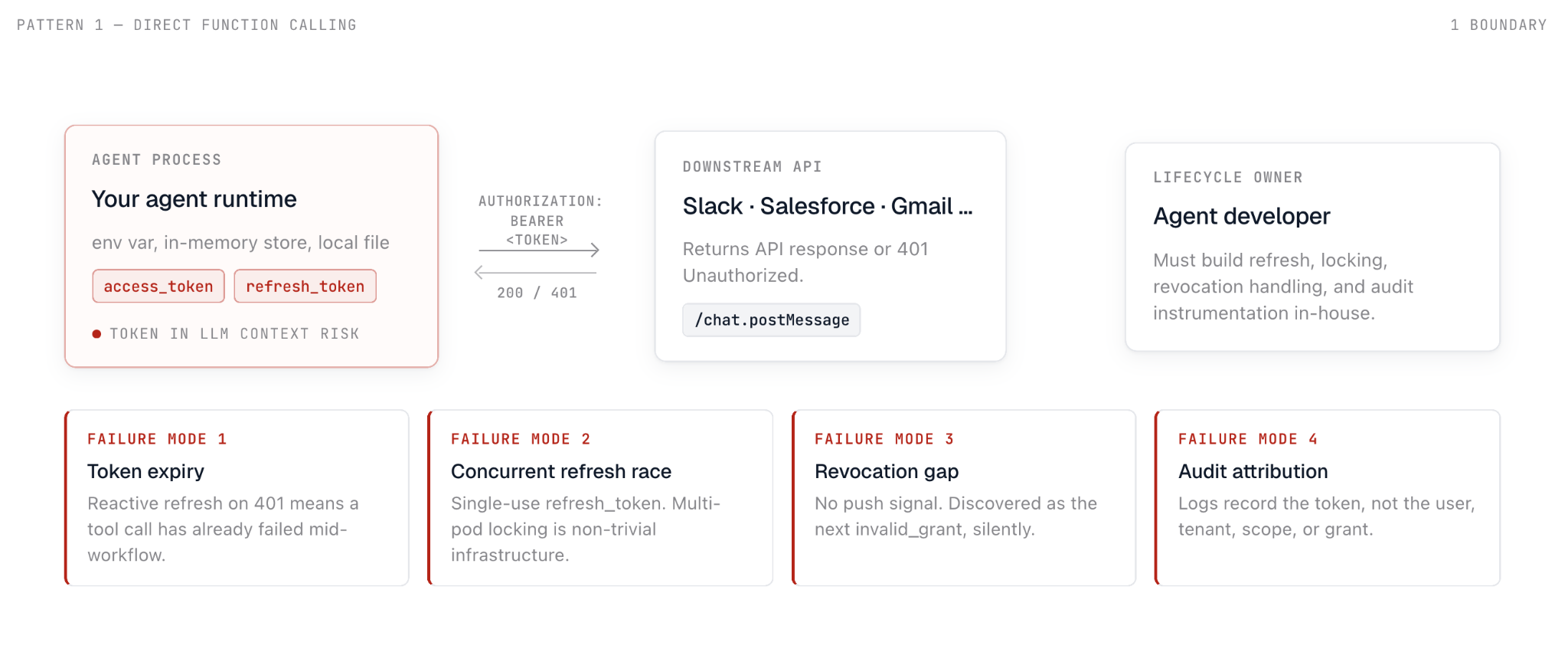
access_token livesrefresh_token livesPattern 1: Agent Process Owns the Credential
What this looks like in code
The access_token is a string in a variable. It gets attached to an Authorization: Bearer header on every outbound API call. The refresh_token is stored somewhere the agent can reach - an environment variable, an in-memory store, a local file.
This is the fastest path to a working demo. It is also the pattern that accumulates the most hidden engineering debt.
Failure mode 1: Token expiry and proactive refresh
OAuth access_token values are short-lived by design. Provider-specific TTLs:
access_token TTLrefresh_token issued on every refresh; old one immediately invalidatedWaiting for a 401 to trigger refresh is the wrong architecture. By the time a 401 arrives, a tool call has already failed. In a multi-step agent workflow, a failed tool call mid-execution leaves state partially committed. Refresh must be proactive - scheduled based on expires_in from the token issuance response, not reactive to API failures.
The correct pattern:
This is the minimum. It does not yet handle concurrency.
Failure mode 2: Concurrent refresh race conditions
This is where Pattern 1 breaks under real production load.
Multiple agent threads or processes sharing a credential will eventually hit token expiry simultaneously. When they do, all threads attempt to call the OAuth token endpoint with the same refresh_token at the same millisecond. The sequence:
- Thread A detects expired token → calls
/oauth/tokenwith refresh_token=abc123 - Thread B detects expired token → calls
/oauth/tokenwith refresh_token=abc123 - Thread A succeeds → receives access_token=new1, refresh_token=def456
- Thread B fails →
{"error": "invalid_grant", "error_description": "refresh_token_reused"}- because abc123 was already consumed by Thread A
Thread B now has no valid credential. It cannot recover without user re-authorization. If Thread B is running background work for a production tenant, that tenant's automation is silently broken until the next time a human notices.
The fix requires distributed locking at the credential level:
This handles in-process concurrency. Across multiple server processes - multiple pods, multiple workers - this lock does nothing. You need a distributed lock: Redis SETNX, a database advisory lock, or similar. That is a non-trivial piece of infrastructure to build, test, and operate.
And this only addresses expiry-based refresh. It does not address revocation.
Failure mode 3: Revocation is a different failure class than expiry
When an access_token expires, you call the OAuth token endpoint with the refresh_token and receive a new access_token. Automated. Recoverable.
When a refresh_token is revoked, the token endpoint returns invalid_grant or token_revoked. There is no automated recovery. The user must re-initiate the OAuth authorization flow - open a browser, click through consent, grant access again. This cannot happen inside a background agent at 2am.
Common revocation triggers:
- User opens the provider's security settings and disconnects your app
- Admin rotates credentials during a security audit
- Provider detects suspicious activity and invalidates the grant
- Employee offboarding scripts revoke connected OAuth tokens
- Provider enforces periodic re-consent (some enterprise IdPs require this annually)
RFC 7009 (OAuth 2.0 Token Revocation) defines a server-side revocation endpoint. But it does not define a push notification mechanism for when your tokens are revoked by an external actor. The only way Pattern 1 discovers a revoked refresh_token is when the next refresh attempt fails with invalid_grant.
At that point, the agent has been silently failing for however long it took to reach the next refresh cycle.
Failure mode 4: Audit attribution
Every API call your agent makes with a direct token is attributed to the token, not to a user, not to a tenant, not to the specific agent action that triggered it.
Your audit log records:
An enterprise security audit asks: Under whose authorization did this agent call chat.postMessage at 2:47am? Which tenant? Which OAuth grant? Which scope? Was that scope still valid at that moment?
Pattern 1 cannot answer any of those questions from standard application logs. The information was never captured because the credential was managed outside any observability layer.
This is not a compliance edge case. SOC 2 CC6.1 requires evidence that credentials were valid at the time of each action. GDPR Article 6 requires that every data access be tied to a lawful basis - for delegated agents, that basis is the user's OAuth consent, which must be traceable per action.
Pattern 2: MCP Server Owns the Credential
What changed - and what didn't
In Pattern 2, the agent no longer holds the access_token. The agent sends a tool invocation to an MCP server; the MCP server holds the credential and calls the downstream API.

This is strictly better than Pattern 1 from one perspective: the access_token is no longer in the agent process, which means it cannot appear in agent logs, LLM context, or stack traces from the agent layer.
A real-world incident class prevents this: security researchers discovered that certain agentic development tool configurations could exfiltrate credentials stored in agent process memory or environment variables through malicious repository configurations. Tokens in the MCP server process are not immune to all attack vectors, but they are outside the blast radius of prompt injection attacks that exfiltrate from agent memory.
However: every auth failure class from Pattern 1 has relocated to the MCP server process. The MCP server now needs proactive refresh, distributed locking, revocation handling, and audit instrumentation. The engineering burden is identical. Only the owner changed.
The two auth boundaries MCP introduces
This is the structural problem that Pattern 2 creates beyond what Pattern 1 had.
Pattern 1 has one auth boundary: agent → downstream API.
Pattern 2 has two:
Boundary 1 (inbound): Agent → MCP server
Who is allowed to call this MCP server? Without auth on this boundary, any process that can reach the MCP server endpoint can invoke its tools using its stored credentials. This boundary requires:
- OAuth 2.1 on the MCP server endpoint
- PKCE (Proof Key for Code Exchange) - RFC 7636
- Dynamic Client Registration (DCR) - RFC 7591 - so agents can register without manual client provisioning
- Scoped tokens per tool invocation (not blanket access to everything the MCP server can do)
Boundary 2 (outbound): MCP server → downstream API
This is Pattern 1's entire problem set, now owned by the MCP server. The MCP server holds Slack credentials, GitHub credentials, Salesforce credentials. It needs to handle expiry, concurrent refresh, revocation, and per-tenant isolation for each of them.
Most MCP deployments secure Boundary 1 and treat Boundary 2 as an implementation detail. Boundary 2 is where production incidents happen.
Token bleed across tenants
MCP servers deployed as shared infrastructure face an additional risk: cross-tenant token bleed.
An MCP server caches a connected_account → access_token mapping in memory for performance. An organization changes their Slack workspace configuration. The mapping goes stale. The next tool call from Tenant A uses Tenant B's cached token - and the call succeeds, writing data to the wrong workspace.
There is no error. The wrong tenant's data is modified. The only signal is a user noticing an update they didn't trigger.
This requires explicit per-tenant credential isolation at every layer of the MCP server's credential management - not just at the endpoint level, but in the token storage, retrieval, and caching layers. Teams building MCP servers rarely instrument for this failure mode until it has already happened.
Recommended Reading: Build Production-Ready Agent Workflows with Remote MCP Servers - covers the FastMCP + authorization server pattern for securing both MCP boundaries.
Pattern 3: Vault Owns the Credential
The structural guarantee
In Pattern 3, no process in your application stack has the access_token or refresh_token in memory. The vault is the only system that holds, decrypts, and uses credentials. The agent calls a tool interface and receives a result. The credential never transits agent memory.

The agent receives the API result. It never received the token. The access_token was decrypted inside vault infrastructure, used for one HTTP call, and released from memory. It is not in the execute_tool response. It is not in application logs. It is not accessible via the agent's memory at any point in the call chain.
How the vault handles what Pattern 1 required you to build
Proactive refresh: The vault maintains a background scheduler per connected_account. When expires_at - now < threshold (configurable per provider - typically 5–10 minutes), the vault initiates a refresh before any agent thread requests the token. No agent code is involved. No 401 is required to trigger it.
Concurrent refresh safety: The vault applies a distributed lock keyed on connected_account_id. When the background scheduler initiates a refresh, any concurrent request for the same credential waits on the lock. One HTTP call to the OAuth token endpoint. One write to the credential store. All waiting threads receive the updated token after the lock releases. Zero refresh_token_reused errors.
Revocation handling: The vault subscribes to provider webhook events for connected_account lifecycle changes. When a user disconnects an app in Slack's security settings, Slack fires a webhook to the vault's event endpoint. The vault marks the connected_account as disconnected and fires a structured event to your application:
Your application receives this event before the next tool call attempts to use the credential. The agent can handle it gracefully - pause the workflow, notify the user, request re-authorization - rather than discovering it as a silent invalid_grant mid-execution.
Audit attribution: Every execute_tool call is logged at the vault layer with full identity context:
This answers every question a SOC 2 auditor or enterprise security team will ask.
Industry convergence on vault-backed architecture
This architecture is not a Scalekit-specific design choice. It is where the industry has independently converged.
Microsoft Foundry Agent Service (Azure AI): "When an agent invokes a tool, Agent Service requests an access token for the downstream service and uses that token to authenticate the tool call... Developers don't manage tokens directly - Agent Service handles the entire exchange." The token exchange chain is: Blueprint credentials → Agent identity token → Scoped downstream token. The agent code sees none of this.
Microsoft Entra Agent ID best practices: "Store certificate private keys in Azure Key Vault or an HSM... Use the on-behalf-of (OBO) flow for interactive agents acting on behalf of a user." The explicit recommendation is that agents authenticate via token exchange, not by holding raw credentials.
Google ADK authentication guidance: "Use an authentication manager service that manages both [storage and acquisition] for you. This service should handle the storage of keys and secrets, as well as the acquisition, management, and storage of OAuth access or refresh tokens... credentials stored in a dedicated secret manager service to protect that data... credentials should not be resident in the agent's operating memory."
Three major agent platforms. Three independent implementations. The same architectural conclusion: the agent does not hold the credential.
The OAuth flows that make Pattern 3 work
Pattern 3 typically combines three OAuth flows depending on context:
Authorization Code Flow (RFC 6749): Used for user-delegated access. The user authorizes once via browser redirect; the vault stores the resulting access_token + refresh_token tied to a connected_account (user + tenant + provider). Every subsequent agent action on behalf of that user draws on this grant without re-authorization.
Client Credentials Flow (RFC 6749): Used for org-level service accounts - background pipelines, scheduled syncs, system-to-system calls where no specific user is in the loop. The vault stores client credentials scoped to the organization, not to a user.
Token Exchange (RFC 8693): Used in MCP chains or multi-agent workflows where one service needs to delegate authority to a downstream service. The vault issues a short-lived, scoped token derived from the original grant - constrained to the specific downstream resource, expiring within minutes. The downstream service never sees the original refresh_token.
For delegated access with full audit traceability, the token payload carries the delegation chain:
sub identifies the agent. act.sub identifies the user on whose behalf it acts. Every log entry, every audit record, every API call carries this chain. RFC 8693 §4.1 defines this structure for nested delegation, enabling multi-hop agent workflows to maintain a traceable authorization chain across every hop.
The Production Incident That Confirms the Wrong Pattern
The failure that reveals credential ownership issues rarely surfaces in development. The conditions required to trigger it - multiple tenants, concurrent threads, token rotation enabled - almost never exist in staging.
In staging: one tenant, freshly issued tokens, single-threaded execution. Everything works.
In production, three months later: 40 enterprise tenants, three to five concurrent agent threads per tenant, Slack token rotation enabled. At the token rotation boundary, multiple threads hit expiry simultaneously. The race condition triggers. The losing threads receive invalid_grant. The agent continues executing. Tool calls using the invalidated tokens fail silently. Downstream workflows complete with structural gaps - records not updated, messages not posted, tickets not created - without a single exception surfacing.
In one documented case of this exact pattern, an agent sharing a credential file across concurrent processes entered a state where refresh races caused a stale token to be stored as a fallback credential. When the stale token was used for subsequent calls, all calls returned persistent 403 token_revoked errors. The agent silently dropped all incoming messages for approximately 10 minutes. No error was surfaced to the operator. The only detection signal was a user noticing that the automation had stopped responding.
The detection problem: Race condition failures are timing-dependent. They require real concurrency, real token rotation intervals, and real multi-tenant load to reproduce. They do not appear in unit tests against OAuth mocks. They do not appear in staging with a single test tenant. By the time the first incident fires in production, the audit trail shows 401 Unauthorized against several API calls - without indicating which thread, which tenant's credential, or which workflow stage triggered the cascade.
Recommended Reading: How to Handle Token Refresh for AI Agents - covers proactive refresh, distributed locking, and the revocation vs. expiry distinction in detail.
Choosing Based on What You're Willing to Own
This is not a feature matrix. It is an operational ownership decision.
access_token in agent runtimeaccess_token in LLM context riskrefresh_token in agent runtimeinvalid_grantinvalid_grantconnected_account levelWhen Pattern 1 is defensible
Single tenant. Single-threaded execution. Internal tooling with no compliance requirements. A team that will actively maintain refresh, rotation, and revocation logic. The credential surface is bounded and the team can own it directly.
The moment you add a second tenant, a second concurrent worker, or an enterprise compliance requirement, the bounds change. What was manageable at one tenant is operationally unsustainable at forty.
When Pattern 2 (MCP) is appropriate
MCP is the right transport and discovery protocol for multi-agent systems and tool registries. It is not, by itself, a credential management solution. Pattern 2 becomes viable when:
- Boundary 1 (agent → MCP server) is secured with OAuth 2.1 + PKCE + DCR
- Boundary 2 (MCP server → downstream API) is backed by a vault - not ad-hoc in-process credential management
MCP transport + vault-backed outbound credentials is a sound architecture. MCP transport + Pattern 1 credentials inside the MCP server is Pattern 1 with extra deployment complexity.
Recommended Reading: MCP Auth - Drop-in OAuth for MCP Servers - covers OAuth 2.1, PKCE, DCR, and token scoping for both MCP boundaries.
When Pattern 3 is required
Multi-tenant B2B. More than two or three external tools. Delegated user access (agent acting on behalf of a specific user, not a service account). Enterprise compliance requirements - SOC 2, GDPR, HIPAA, ISO 27001. Any agent running background workflows where revocation events need a proactive signal rather than silent failure discovery.
The operational question: When this refresh_token is revoked at 2am during a background workflow - by a user, by an admin, by a provider security event - whose runbook handles it? If the answer is "the agent developer's," Pattern 3 is the appropriate architecture.
How Scalekit AgentKit Implements Pattern 3
Scalekit AgentKit is a credential ownership layer for agents - it is the infrastructure that implements Pattern 3 in production.
Three primitives underpin the architecture:
Connection: One OAuth configuration per service (Slack, Salesforce, GitHub, etc.). Configured once, shared across all users. Holds the OAuth client_id, client_secret, scopes, and provider-specific refresh behavior. One connection per app in your Scalekit environment.
Connected Account: Per-user auth state derived from the connection. When a user completes the OAuth authorization flow, Scalekit creates a connected_account that stores their access_token and refresh_token encrypted at rest, isolated by tenant_id. The agent never accesses this record directly - it passes a user_id and Scalekit resolves the connected_account internally.
execute_tool: The agent-facing interface. The agent calls execute_tool with a tool name, parameters, and a user_id. Scalekit resolves the correct connected_account, validates token state, refreshes under distributed lock if needed, executes the downstream API call, and returns the result. No token is returned to the caller.
Three concurrent calls to execute_tool for the same user_id + tenant_id + Slack combination will not produce a refresh race condition. Scalekit's vault layer applies a distributed lock at the connected_account level before any refresh is initiated.
Agent Webhooks handle revocation proactively. When a user disconnects a connected account, Scalekit fires a structured event before the next tool call discovers the failure:
- connected_account.disconnected → pause workflow, notify user, request re-auth
- token.refresh_failed → halt background execution, surface to operator
- connected_account.created → trigger onboarding flow
No polling. No stale state. Identity signals arrive when they happen, not when the next tool call fails.
100+ prebuilt connectors - Slack, Salesforce, GitHub, Linear, Notion, Gmail, HubSpot, and more - with connector-specific OAuth scope handling and provider-specific refresh logic encoded per connector. Slack's single-use refresh_token rotation, Google's 1-hour access token, Salesforce's 2-hour TTL, GitHub PAT behavior - each is handled by the connector, not by agent code.
For custom or internal APIs, the Bring Your Own Connector path lets you register your own OAuth config and use the same execute_tool interface with the same vault-backed credential management.
The Auth Terminology Agents Require
For 301-level completeness, the vocabulary that appears in production agent auth systems:
connected_accountconnectionclient_id, client_secret, scopes, redirect URIs.access_tokenAuthorization: Bearer to downstream API calls. Never returned to agent code in Pattern 3.refresh_tokenaccess_token values. Single-use in many providers (Slack, some Google flows). Never returned to agent code in Pattern 3.sub (agent identity) and act.sub (user identity) per RFC 8693 §4.1.invalid_grantrefresh_token is expired, revoked, or already used (single-use rotation). Not recoverable by automated retry. Requires user re-authorization.expires_inaccess_token expiry, returned in token issuance response. The correct trigger for proactive refresh scheduling. Not 401.connected_account credentials for Tenant A can never be resolved for Tenant B. Enforced at the credential storage and resolution layers.Conclusion
The integration pattern is an auth architecture decision. The token has to live somewhere. Wherever it lives, every auth failure class that token can generate - expiry races, concurrent refresh conflicts, revocation signal gaps, audit attribution holes, tenant bleed - belongs to that layer's operator.
Pattern 1 ships fastest. It accumulates the most operational debt at production scale. Pattern 3 is what multi-tenant B2B agents require. Pattern 2 with vault-backed outbound credentials is the path for teams that need MCP as their tool protocol.
Most teams discover which pattern they chose when the first concurrent refresh race surfaces in production - not in staging, not in a test, but under real tenant load, at real token rotation intervals, with a customer asking why the pipeline stopped.
The credential ownership question deserves an answer before the first line of agent code is written.
Explore Scalekit AgentKit: OAuth for AI Agents · Token Vault architecture · What Is Agent Authentication?







