


AI agents have moved beyond assistance and now operate autonomously inside modern SaaS systems. They can summarize conversations, update CRM records, sync documents, open tickets, and orchestrate workflows across multiple APIs without continuous human supervision. Unlike traditional web applications, these agents continue acting long after the initiating user session ends.
This shift changes how authentication must be designed. Traditional OAuth assumes an interactive user flow: a redirect, a consent screen, and a short-lived session. AI agents require delegated access that continues after the initiating user session ends, background refresh handling, service identities for non-user workflows, and strict tenant isolation in multi-tenant environments. A simple “redirect and store the token” model works in demos, but it does not survive production scale or enterprise security review.
This guide examines how OAuth for AI agents must be structured in real systems. We will walk through the three OAuth flows agents use, explore secure token storage and refresh orchestration, design least-privilege scope boundaries, and define the controls required for production-ready, multi-tenant AI SaaS platforms.
AI agents operate across external systems; they read Slack messages, create tickets, update CRM records, and trigger workflows in tools such as Google Drive and GitHub. These actions require access to APIs owned by a specific user or organization. Because agents continue operating beyond a single session, this access cannot rely on shared credentials or static API keys.
Delegated authority must be explicit and bounded. Each tenant must grant permission that reflects its own scope boundaries. Tokens must be stored securely, isolated per tenant, and designed to expire and refresh safely over time. When agents run autonomously, that delegated access becomes long-lived infrastructure rather than a short-lived login artifact.
OAuth provides the control framework for this model. It standardizes how authority is granted, constrained through scopes, issued as tokens, refreshed in the background, and revoked when necessary. The remaining design question is which OAuth authority pattern best matches the agent’s behavior, a decision that directly maps to the three OAuth flows used in AI SaaS systems.
Recommended Reading: ScaleKit Auth Stack for AI Apps is now GA
Recommended Reading: How Hubbl added enterprise SSO without refactoring?
AI agents operate under three distinct identity models. Each model corresponds to a different authority boundary: delegated user access, service-level automation, or scoped delegation across services. These flows are defined within the OAuth 2.0 framework specified in RFC 6749 and its extensions. OAuth 2.1 consolidates RFC 6749 with the OAuth 2.0 Security Best Current Practices (BCP) and mandates PKCE while removing implicit and password grant flows. Token Exchange (RFC 8693) remains an extension to the core framework. Selecting the correct flow determines how permissions are granted, how tokens are managed, and how lifecycle controls are enforced.
In OAuth-based AI SaaS systems, these patterns recur across integrations. A Slack summarization agent uses delegated user access. A compliance scanner relies on service credentials. A workflow orchestrator exchanges tokens when invoking downstream APIs. Understanding these flows is foundational before designing token storage or refresh orchestration.

This diagram highlights how authority originates and propagates through an AI system. Authority may originate with a user, be issued by a service identity, or be exchanged between services to preserve least privilege.
The Authorization Code flow allows an AI agent to act on behalf of an authenticated end user within your SaaS application. The end user initiates the integration (for example, by connecting Slack), is redirected to the provider’s authorization server, and explicitly grants your application permission. Your backend then exchanges the authorization code for access and refresh tokens tied to that user’s identity.
This pattern is common for:
The defining property is delegated authority. The agent’s permissions are bound by the scopes granted during consent. Because agents operate beyond the initial session, token lifecycle management becomes critical.
Recommended Reading: Wise brings enterprise SSO and SCIM to Firebase without the rewrite
The Client Credentials flow allows a backend AI service within your SaaS platform to authenticate as a service identity rather than as an individual end user. No user redirect or interactive consent occurs during execution. Instead, your backend service authenticates directly with the provider’s authorization server using its client credentials and receives an access token that represents the application’s own authority.
This pattern is used when the agent performs operations that are not tied to a specific user identity, such as:
The defining property of this flow is non-delegated authority. The token does not represent a user. It represents the application or service itself. Scope configuration becomes the primary control boundary, since the service operates with application-level authority defined by the provider and your internal tenant model.
The Token Exchange flow enables one service to exchange an existing token for another token with reduced or modified scopes. This pattern preserves least privilege when authority must propagate across service boundaries. It is defined in RFC 8693.
This model is used when:
The defining property is controlled delegation between services.
In practice, these flows are not mutually exclusive. A single AI SaaS platform may use delegated access when acting on behalf of users, service credentials for tenant-level automation, and token exchange to propagate identity across internal services. The architectural challenge is not understanding them in isolation, but knowing when each authority model should be applied.
Among these patterns, the user-delegated Authorization Code flow is the most common starting point. It introduces refresh handling, tenant isolation, and concerns about long-lived delegated authority that shape the rest of the system design. Implementing it correctly establishes the foundation on which the other flows can safely operate.
Recommended Reading: Should you build MCPs before APIs?
Consider a Slack summarization agent inside your SaaS platform. A user connects their Slack workspace so the agent can read selected channels and post summaries on their behalf. The initial integration requires explicit consent, but the agent must continue operating on a schedule even when the user is offline.
The Authorization Code flow enables this model of delegation. The user authorizes your application through Slack’s authorization server, and your backend exchanges the authorization code for access and refresh tokens tied to that user’s identity. The agent can then call Slack APIs within the granted scope.
In production, the complexity lies beyond the code exchange. Tokens expire, refresh tokens rotate, and users may revoke access or leave the organization. Because the agent runs autonomously, managing delegated authority over time becomes infrastructure rather than just a redirect flow.
The flow begins when an authenticated user in your system initiates the Slack integration. Your backend constructs a redirect to Slack’s authorization endpoint, specifying the required scopes and a CSRF-protected state parameter.
This redirect defines the authority boundary. The scopes requested at this stage determine exactly what the agent will be permitted to do on behalf of the user. Any permission not requested here cannot be exercised later by the agent.
Production considerations include:
Consent is not merely a redirect step. It establishes the maximum privilege envelope within which the agent can operate.
After the user grants consent in Slack, Slack redirects back to your application’s configured callback endpoint. This endpoint belongs to your SaaS backend. It is responsible for exchanging the short-lived authorization code for long-lived credentials tied to that specific user and tenant.
In the Slack summarization example, this callback is triggered when a user connects their workspace. The backend must securely exchange the code for an access token and a refresh token and associate them with the correct tenant and user record in your system.
This code runs inside your SaaS backend service. It performs three critical responsibilities:
Production safeguards during this exchange include:
At this stage, OAuth transitions from a user-driven redirect flow to a long-lived delegated authority model. The AI agent will later retrieve these stored tokens to perform scheduled summaries, event-driven processing, or other background tasks on behalf of that user.
Recommended Reading: How Napkin AI became enterprise ready on Firebase with Scalekit?
Once tokens are stored, the AI agent begins calling APIs autonomously. In the Slack summarization example, the agent may run every hour to generate summaries, respond to Slack events in real time, or trigger follow-up workflows in other systems. These operations occur without the user having to actively re-authenticate.
At this stage, the architecture shifts from handling a redirect flow to sustaining long-lived delegated authority. Access tokens expire. Refresh tokens rotate. Users may revoke access or leave the organization. Background workers may execute concurrently across tenants. What was initially a simple integration becomes an ongoing identity lifecycle problem.
Three infrastructure concerns now determine system reliability:
Storage becomes the foundation for all three. If tokens are improperly modeled, insufficiently isolated, or inconsistently encrypted, refresh coordination and tenant enforcement will inherit those weaknesses. The next architectural layer to examine is, therefore, token storage.
After the code exchange, access and refresh tokens become long-lived credentials used by background workers and scheduled jobs. In AI SaaS systems, these tokens are accessed repeatedly and across tenants, which makes the storage model part of the runtime security boundary.
Each token must be explicitly associated with a tenant and identity context. Weak isolation, shared caches, or ambiguous ownership can lead to cross-tenant access in distributed environments. In addition, storing tokens without lifecycle metadata such as expiration, scope snapshots, or status creates technical debt that complicates refresh handling, revocation, and auditing later.
A production-ready design should:
Token storage is the layer where delegated authority is persisted and consistently enforced across background execution.
A production-ready design separates logical ownership, encryption boundaries, and operational access.
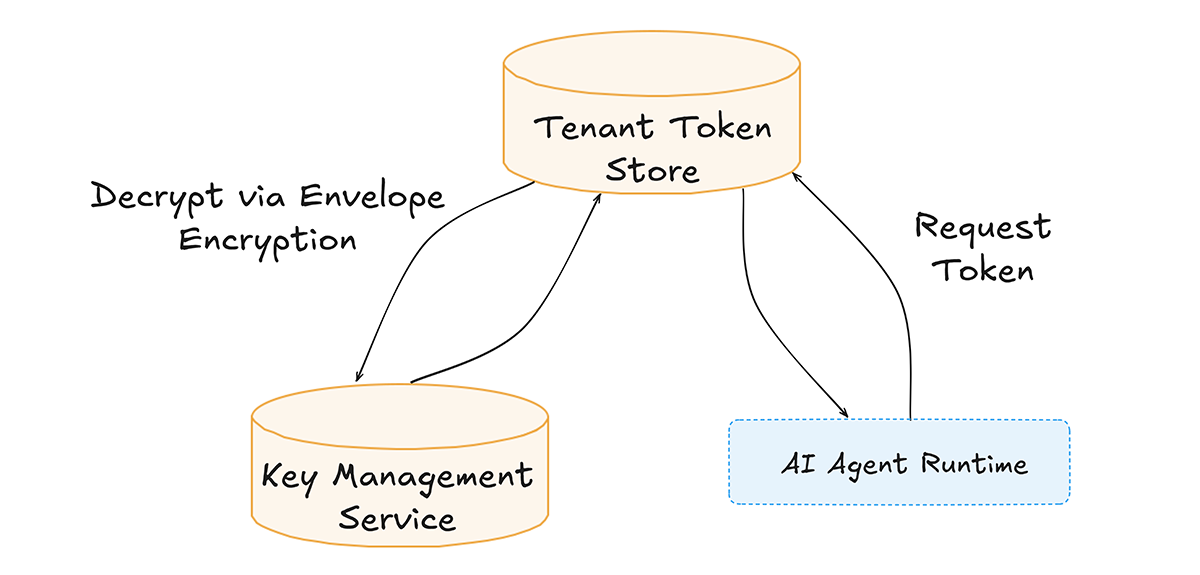
In this model:
This approach ensures tenant-level blast radius control.
These fields are not OAuth request parameters. They represent the minimum schema required in your backend database to safely persist delegated credentials in a multi-tenant environment.
A token record must explicitly model identity boundaries. Storing tokens without a clear tenant and authority association introduces systemic risk. Shared token pools or mixing service-level and user-delegated tokens in the same schema without explicit separation can lead to accidental privilege escalation.
Each stored token record should include:
This schema ensures that delegated authority is explicitly bound to identity, scope, and lifecycle state. Without these fields, enforcing tenant isolation, revocation, and refresh coordination becomes difficult and error-prone.
Encryption must be treated as an architectural control, not a checkbox.
Production requirements typically include:
In addition, internal services that access tokens should authenticate through service identity rather than database-level credentials. That separation reduces the risk of lateral movement if a single service is compromised.
Proper storage design enables safe refresh handling and automated lifecycle management. Without strong isolation and encryption, refresh logic simply prolongs insecure access. The next section explains how to design refresh handling correctly so AI agents maintain access without introducing instability or security gaps.
Consider a Slack summarization agent that runs hourly across tenants. It retrieves channel history and posts summaries even when users are offline. Once the initial consent is complete, the agent depends entirely on access and refresh tokens to continue operating. When those tokens expire or are revoked, refresh handling determines whether the system degrades gracefully or fails unpredictably.
Access tokens expire routinely. Refresh tokens may rotate, expire due to inactivity, or be invalidated after password changes or administrative revocation. Some providers enforce absolute refresh token lifetimes or inactivity windows. If the token is not used within a defined period, it expires regardless of rotation. Production systems must account for these provider-specific policies and explicitly surface re-authentication requirements. In unattended AI systems, these events occur during background execution, often under concurrency.
Refresh handling typically breaks in production due to reactive or uncoordinated implementation. Common issues include:
Because agents may execute parallel jobs across tenants, multiple workers can attempt to refresh the same token simultaneously unless coordinated.
A stable implementation schedules a refresh slightly before expiration rather than waiting for API failure. For example:
Production safeguards should include:
When the entire credential chain is invalidated, the system should stop retrying and mark the identity as requiring re-authentication. Agent workflows should degrade gracefully rather than cascade into retry storms.
User-delegated access must reflect organizational changes. If a user leaves a company or an admin revokes access, the delegated authority must be explicitly terminated.
Strong implementations include:
Refresh handling extends delegated authority safely, but only if revocation is treated as a first-class state.
Scopes define the maximum authority granted during consent. In OAuth for AI agents, scope modeling directly controls blast radius because tokens persist beyond user sessions and execute autonomously.
Most providers (Slack, Google, GitHub) define fixed scope models. Applications cannot subdivide provider scopes arbitrarily. For example, GitHub’s repo scope cannot be broken into repo.read and repo.write unless the provider exposes them separately.
Instead of inventing new scopes, applications should:
For example, a Slack summarization agent typically requires:
It does not require workspace-level administrative access.
Scopes evolve over time as workflows expand or providers change permissions. Without visibility, scope creep becomes invisible.
Production systems should:
Scope boundaries define the ceiling of delegated authority. Strong scope governance limits systemic risk even when other controls fail.
Consider a SaaS platform where multiple companies connect their Slack workspaces to an AI agent that summarizes conversations and creates tickets. Each company represents a separate tenant. If the system mistakenly retrieves the wrong token during background execution, the agent could read or post messages in another company’s workspace. In multi-tenant systems, isolation failures are not theoretical; they result in cross-customer data exposure.
Multi-tenancy fundamentally changes the OAuth risk model. In single-tenant systems, a token leak affects one organization. In AI SaaS platforms, weak isolation can allow lateral access across tenants. Because agents operate autonomously and at scale, improper separation amplifies quickly under concurrency.
Tenant boundaries must therefore be treated as hard identity partitions. Tokens, encryption keys, refresh workflows, and runtime access must all be scoped to a tenant context. Even well-designed scopes and refresh handling cannot compensate for flawed tenant isolation.
Each tenant should be treated as a separate trust domain, enforced at multiple layers:
Isolation should be explicit, not assumed. Every token lookup, refresh operation, and outbound API call must validate tenant context rather than rely on implicit application state.
In this architecture:
Even if one tenant’s key is compromised, others remain protected.
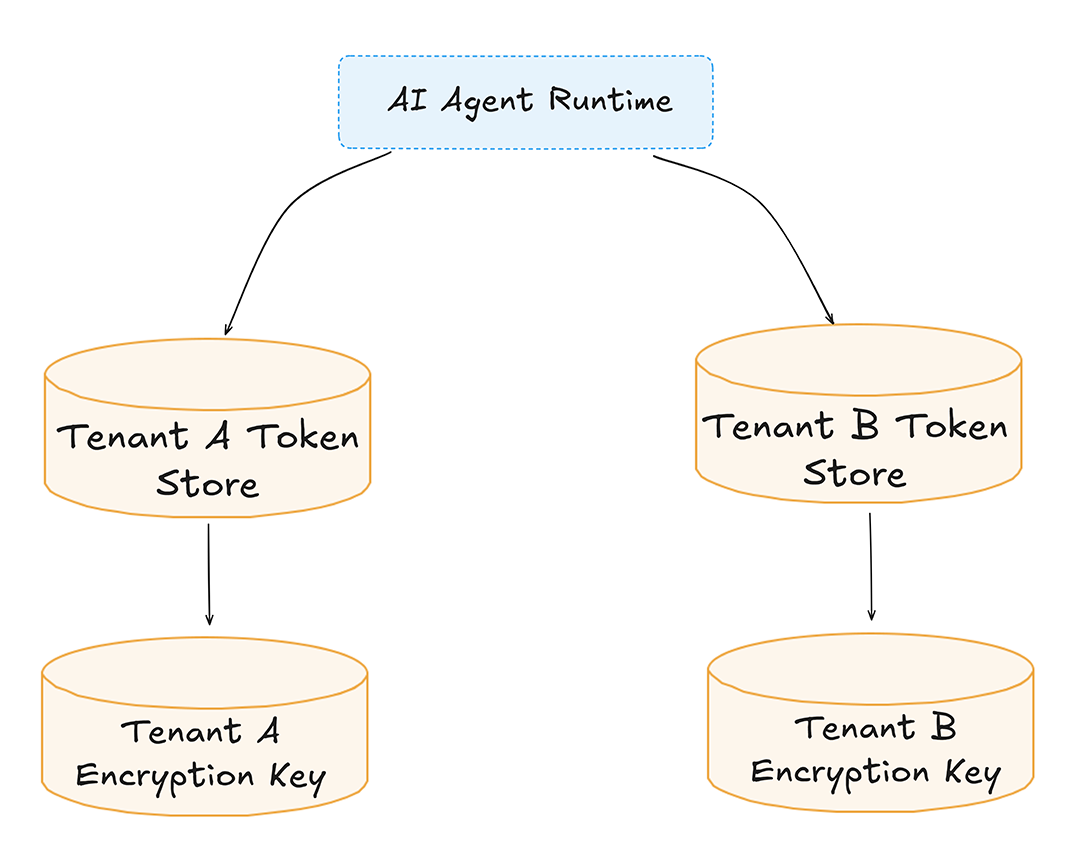
Multi-tenancy must also be in place at execution time. When an AI agent processes a job, the job should carry a tenant context that controls:
This prevents scenarios where background workers accidentally reuse cached tokens across tenants.
Context leakage is a common but preventable failure mode in distributed AI systems.
In a multi-tenant Slack integration, background workers may process jobs for multiple companies in parallel. If a token lookup or cache retrieval does not validate the tenant context, an API call could execute using another tenant’s credentials. These issues typically surface under concurrency, not during simple request flows.
To enforce tenant boundaries at runtime:
Isolation must be observable. Every outbound API call should be traceable to a specific tenant and delegated identity.
With runtime enforcement in place, the remaining task is to validate that flows, storage, refresh, and isolation controls behave correctly under load, which leads to the production-readiness checklist.
Consider a Slack summarization agent running hourly across multiple tenants. It refreshes tokens automatically and posts summaries without user interaction. In production, however, additional realities emerge: refresh tokens expire after inactivity, administrators revoke access, background workers restart mid-refresh, or providers degrade partially.
Production readiness determines whether your OAuth architecture behaves predictably under these conditions. A working redirect flow is not sufficient. The system must tolerate credential rotation, revocation, concurrency, and provider instability without widening privilege boundaries.
The controls below outline the requirements for stable, production-grade OAuth for AI agents.
Authority boundaries are defined at flow selection time. Incorrect flow usage or missing safeguards introduce risk before tokens are ever stored.
A production implementation should ensure:
These controls prevent authority from being misapplied at the protocol boundary.
In multi-tenant AI SaaS systems, tokens represent long-lived delegated authority. Storage architecture determines the blast radius of compromise.
A resilient model should include:
Because bearer tokens are transferable by design, higher-security deployments may require token binding strategies.
Autonomous agents depend on stable refresh handling. Access tokens expire predictably, but refresh tokens may rotate or be invalidated due to password changes or administrative revocation.
A robust implementation should provide:
When the entire credential chain fails, the system must transition cleanly to a state requiring re-authentication rather than retrying indefinitely.
Provider-defined scopes (Slack, Google, GitHub) cannot be subdivided by consuming applications. Internal capability models must map cleanly onto provider scopes rather than inventing new ones.
Effective governance includes:
Least privilege is enforced at consent time and validated continuously.
Autonomous agents must produce traceable identity behavior across tenants.
Operational visibility should include:
Every outbound call should be traceable to a tenant and delegated identity context.
These controls are not arbitrary best practices. They are derived directly from the OAuth core specifications and security extensions that define how delegated authority, token exchange, and bearer security must behave in production systems.
The following references anchor the implementation guidance discussed throughout this guide.
Production OAuth design depends on standards that extend beyond the high-level flow diagrams. The specifications below define the normative behavior for authorization grants, token exchange, security hardening, and proof-of-possession mechanisms. Reviewing these documents helps clarify edge cases around refresh handling, delegation semantics, and bearer token security.
The following RFCs are most relevant when designing OAuth for autonomous AI agents:
For teams implementing multi-tenant AI agents, RFC 8693 and RFC 9449 are often overlooked but become increasingly relevant as systems introduce service-to-service delegation and distributed execution.
Building and operating these controls internally means taking ownership of token encryption, refresh coordination, tenant isolation, and audit visibility. Some teams choose to manage that complexity themselves, while others prefer to centralize it in a dedicated OAuth control plane that handles lifecycle management behind the scenes.
The next section walks through how to implement OAuth for AI agents using Scalekit’s connection model, where agents execute actions using scoped identifiers rather than managing raw tokens directly.
Scalekit implements OAuth for AI agents using a connection and connected account abstraction. A connection defines the provider integration boundary (Slack, Gmail, GitHub). A connected account represents an authenticated identity under that connection.
Instead of storing and refreshing tokens directly in your application, your agent executes actions using an identifier mapped to a connected account. Scalekit manages token exchange, encryption, refresh handling, and tenant isolation internally.
The execution flow below reflects the real end-to-end implementation using Scalekit Agent Auth.

With this model, OAuth becomes an execution infrastructure layer rather than a distributed integration logic.
Before any user authenticates, you must configure how your application integrates with a provider. In OAuth terms, this step registers the client credentials, redirect configuration, and allowed scope bundle that define the upper boundary of delegated authority.
In the Scalekit dashboard:
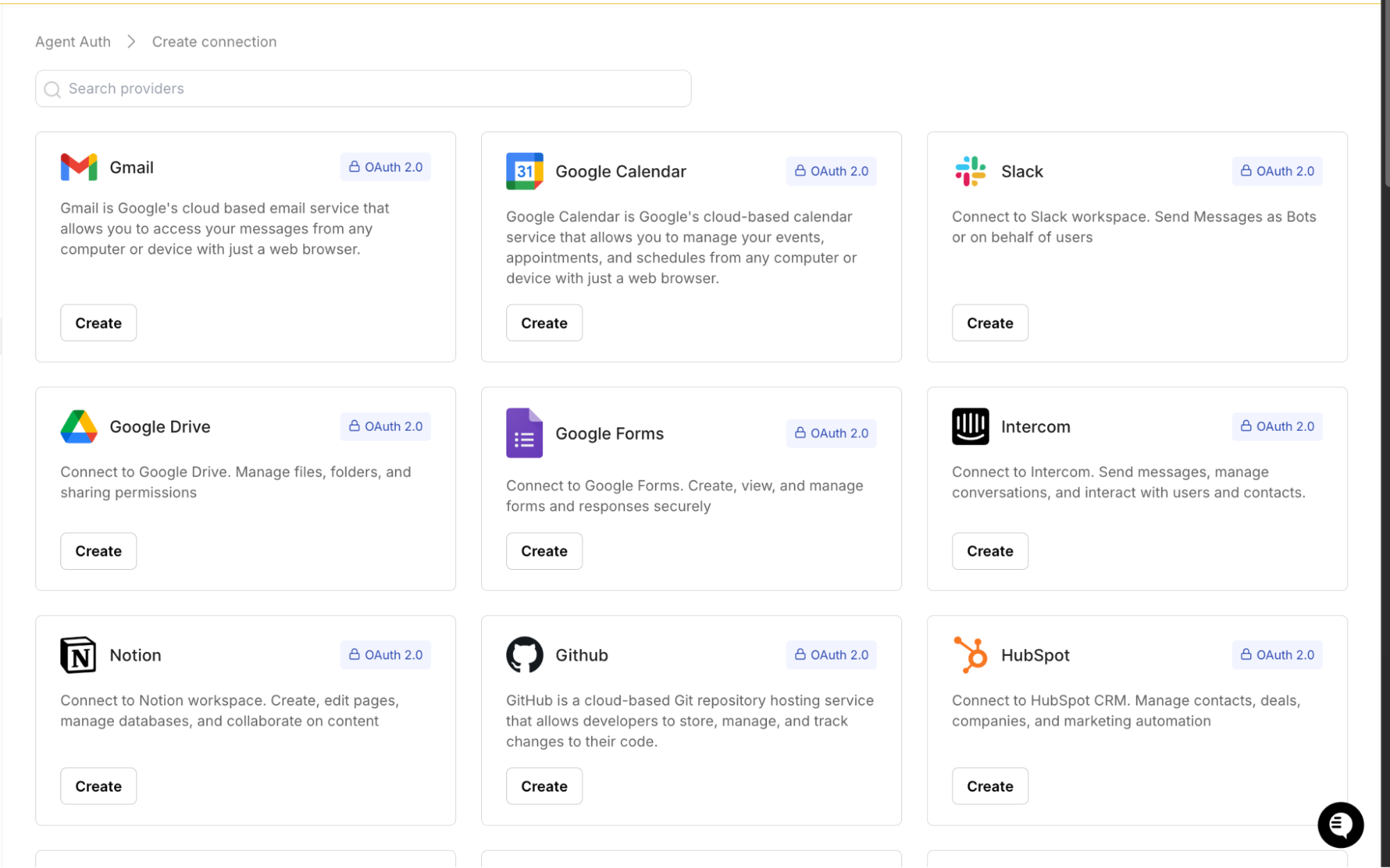
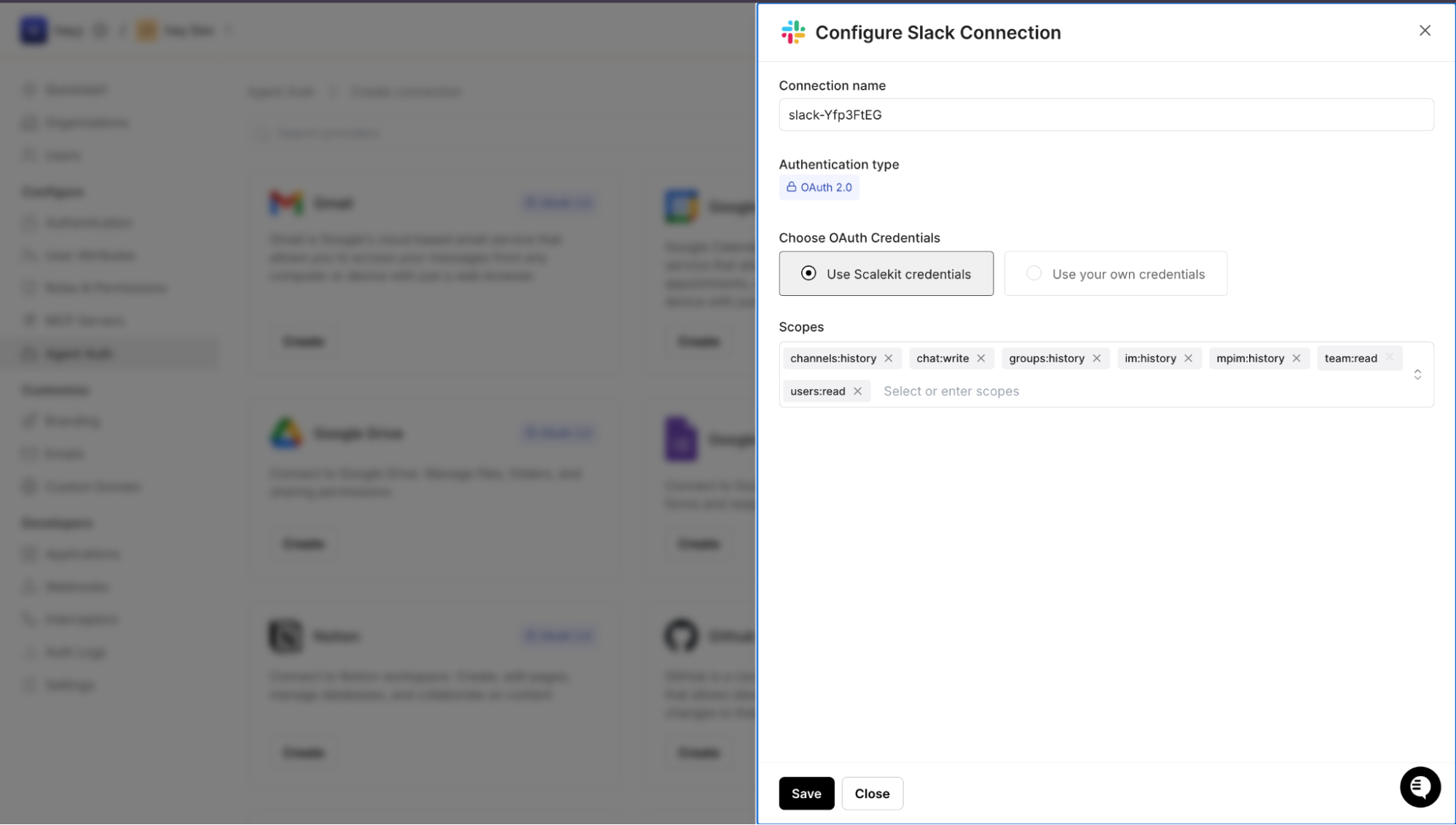
At this stage:
This mirrors the OAuth client registration phase but centralizes it within the connection abstraction.
Once the integration boundary is defined, individual users can authenticate under that connection. A connected account represents a specific delegated identity tied to your internal identifier (such as a user ID or email).
Your backend creates or retrieves this connected account:
If the user has not authenticated yet, Scalekit generates the OAuth authorization URL and handles:
When redirected, the user reviews the requested scopes and grants access. Slack issues an authorization code, which Scalekit exchanges on the server side. Access and refresh tokens are stored securely and associated with the connected account.
Once consent is completed, the connected account status in the Scalekit dashboard changes to Authenticated. This confirms that OAuth tokens are securely stored and ready for agent execution.
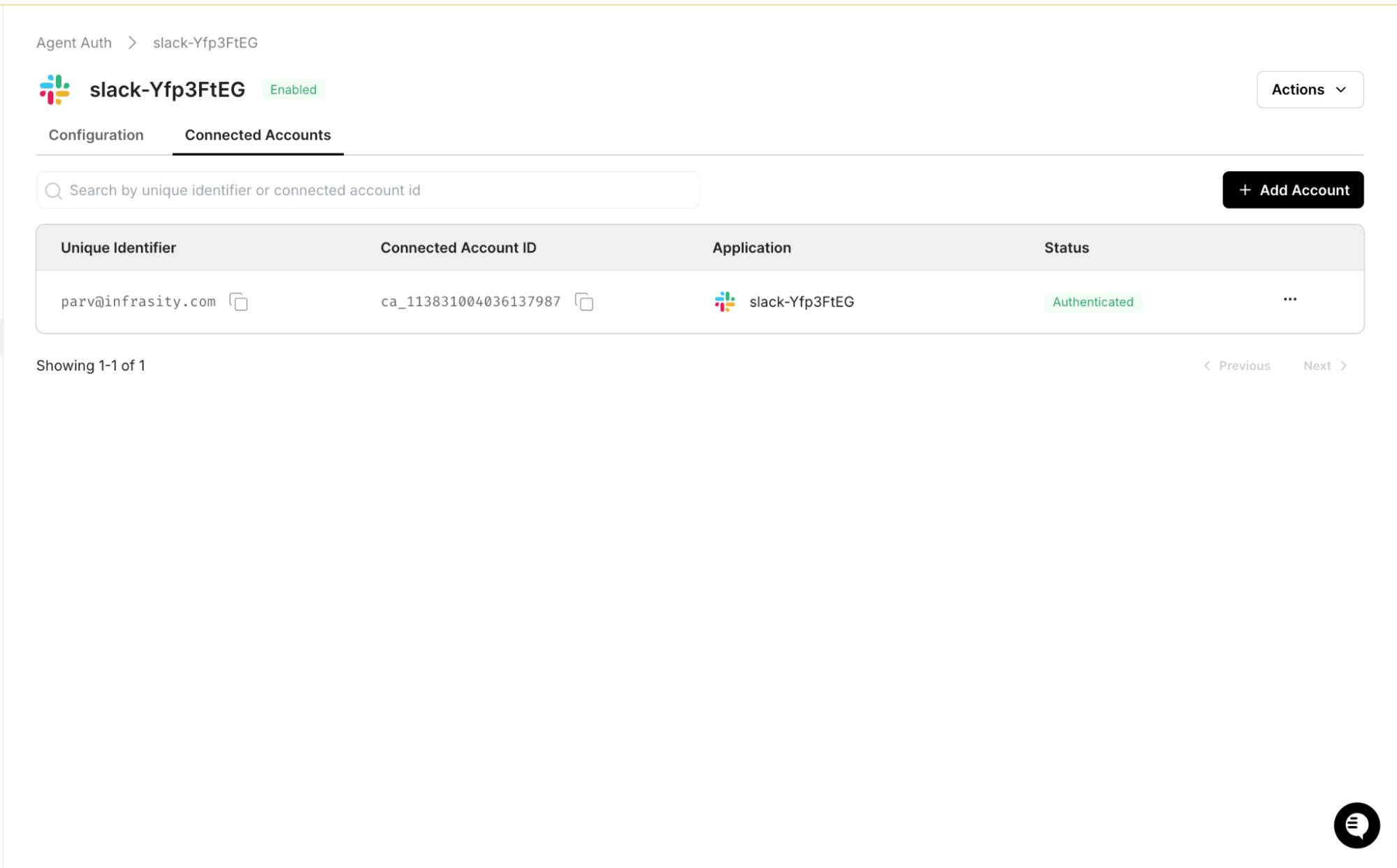
The identifier now maps to an authenticated Slack account.
After authentication, your AI agent executes Slack actions using the same identifier.
At runtime, Scalekit:
The agent never handles refresh tokens or expiration logic.
If the access token expires during execution, Scalekit automatically uses the stored refresh token, retrieves a new access token from the provider, updates encrypted storage, and continues the API call without interruption.
All refresh orchestration, token validation, rotation handling, and secure persistence occur inside the connection and connected account layer. Your application does not implement background schedulers, distributed locking, or custom token storage. OAuth lifecycle management remains centralized, allowing the agent to focus purely on executing authorized actions.
Scalekit enforces strict authority boundaries at multiple layers of the connection model. Delegated access is never global. It is always scoped by provider consent, connection configuration, and identifier mapping. This layered isolation prevents privilege expansion and cross-tenant leakage.
Authority is constrained by:
If two users authenticate Slack under the same connection:
If multiple providers are configured (e.g., Slack and Gmail):
This layered isolation ensures least-privilege enforcement without requiring custom token partitioning or access control logic in your application code.
OAuth for AI agents must operate safely across tenants and beyond user sessions. In this guide, we covered the three OAuth flows used in AI SaaS systems and examined how token storage, refresh handling, scope design, and tenant isolation determine real production stability.
The key takeaway is that OAuth in autonomous systems is infrastructure. Correct flow selection, encrypted and tenant-scoped token storage, coordinated refresh (including re-consent handling), and disciplined scope governance are not optional. Without them, small configuration gaps can scale into cross-tenant risk.
As a next step, review your current integrations against these controls. Identify how tokens are stored, refreshed, and isolated. If lifecycle and isolation logic are fragmented across services, consider centralizing them behind a dedicated identity layer, whether built internally or implemented through a platform such as Scalekit’s Agent Auth.
Traditional OAuth assumes short-lived user sessions and request-response interactions. AI agents operate autonomously after the session ends. This requires long-lived delegated authority, coordinated refresh handling, and strict tenant isolation rather than simple token storage.
Use the Authorization Code when the agent acts on behalf of a user. Use Client Credentials when the agent acts as a service identity. Use Token Exchange when propagating scoped authority across internal services. Many AI SaaS platforms use all three.
If the agent performs background or long-running operations, yes. Access tokens expire. Without refresh handling, autonomous workflows will fail unpredictably.
Improper token storage and tenant isolation. In multi-tenant systems, tokens must be encrypted, explicitly associated with a tenant, and never mixed across authority boundaries.
Reactive refresh waits for a 401 error before renewing tokens, which can cause race conditions and retry storms in distributed systems. Proactive refresh renews tokens before expiration, improving stability for autonomous agents.
Scopes should align with workflow roles rather than provider defaults. Separate read, write, and administrative capabilities. Avoid broad scopes such as full admin unless strictly required.
Scalekit abstracts OAuth using a connection and connected account model. It handles secure token storage, encryption, refresh orchestration, and internal isolation, allowing agents to execute actions using scoped identifiers rather than managing raw tokens.
No. Tokens are securely stored and managed within Scalekit. Your application interacts through identifiers and tool execution APIs, not raw token values.
Yes. A single connection (e.g., Slack) can have multiple connected accounts under it. Each connected account represents a separate authenticated identity with isolated tokens.
If your system supports multiple tenants, multiple providers, background agents, or service-to-service delegation, OAuth becomes infrastructure. Centralizing lifecycle management reduces operational complexity and limits security risk.



.png)




