.webp)


AI agents are rapidly moving from experimental tools into production workflows in enterprises. Teams are deploying agents that monitor repositories, automatically create tickets, post structured updates to collaboration platforms, and coordinate operational processes across multiple SaaS systems. As these systems move into production, the evaluation criteria shift from feature capability to security architecture.
In multi-tenant B2B environments, AI agents do more than automate API calls. They hold authority across systems such as GitHub, Slack, and project management platforms. That authority represents real access to repositories, internal conversations, and operational workflows. Enterprise security teams evaluate this authority in the same way they evaluate human users and service accounts.
This guide explains what agent authentication is, how inbound and outbound identity differ, why multi-tenant complexity amplifies risk, and how B2B AI platforms can design identity infrastructure that satisfies enterprise security expectations.
AI agents introduce a new class of identity risk when deployed inside enterprise systems. Unlike short-lived user sessions, agents operate continuously and often hold long-lived credentials, allowing them to perform actions without direct human supervision. This persistence increases the impact of misconfiguration or excessive permissions.
Consider a DevOps assistant that monitors GitHub pull requests, creates Linear issues, and posts deployment updates into Slack channels. This pattern is explored in more detail in our DevOps assistant walkthrough. In early beta deployments, enabling the assistant appears straightforward: connect OAuth providers, store tokens, and automate workflows. Once deployed to an enterprise customer, however, the evaluation criteria expand beyond functionality.
Security teams begin asking structured identity questions. Under whose credentials does the agent access GitHub repositories? Are Slack bot tokens scoped per workspace? How are API credentials stored and rotated? Can one tenant’s configuration accidentally expose another tenant’s data? These questions reveal that agent authentication is fundamentally about identity governance within multi-tenant boundaries.
AI agents operating inside enterprise SaaS platforms must be treated as identity actors rather than background automation. An identity actor is any entity that holds credentials, exercises permissions, and performs actions across security boundaries. In a multi-tenant B2B system, that definition applies directly to AI agents that read data, write records, and trigger workflows across external platforms.
The DevOps assistant illustrates this clearly. When it reads a private GitHub repository, creates an issue in Linear, or posts to a Slack channel, it is exercising authenticated access within those systems. That authority may be delegated from a specific engineer or granted through an organization-level bot identity. In either case, the assistant is not merely executing logic; it is operating under credentials that represent real access within enterprise environments.
AI agents also differ from human users in ways that affect identity design. They often operate continuously, hold long-lived tokens, automatically refresh credentials, and perform actions without an active session. These characteristics increase the importance of scoping, isolation, revocation, and auditability. Recognizing AI agents as first-class identity actors is the foundation for understanding why agent authentication requires architectural thinking rather than simple integration patterns.
Agent authentication in B2B systems spans two independent but interconnected trust boundaries: inbound authentication, which governs who controls the agent within your platform, and outbound authentication, which governs what the agent can access across external systems. In multi-tenant SaaS, these layers must be designed separately because they answer different security questions and are evaluated independently during enterprise reviews.
Inbound authentication establishes organizational ownership and administrative control. Enterprise users authenticate through SAML or OIDC, are mapped to a tenant, and receive role-based permissions. This process determines who can enable integrations, grant scopes, configure connections, or disable the agent entirely.
In the DevOps assistant scenario, inbound authentication ensures that:
Without strong inbound identity resolution, tenant boundaries cannot be enforced consistently. Inbound authentication governs who is allowed to configure the agent. Outbound authentication governs what the agent is allowed to access once configured.
Outbound authentication defines the credentials the agent uses to interact with GitHub, Linear, and Slack. These credentials may be issued via delegated OAuth flows or service-level identities, but in all cases, they represent real authority within external systems.
For the DevOps assistant, outbound authentication enables:
Each token must be tenant-bound, securely stored, minimally scoped, refreshable, and revocable. If outbound credentials are shared or misbound, cross-tenant data exposure becomes possible.
The flow below illustrates how inbound control and outbound capability operate as separate but coordinated boundaries.

The DevOps assistant sits at the intersection of these boundaries. Inbound identity determines who can configure the agent, while outbound credentials determine what the agent can access. Designing agent authentication correctly requires enforcing tenant isolation at both layers simultaneously.
Multi-tenant SaaS fundamentally changes the risk profile of agent authentication. In a single-organization system, misconfigured credentials may expose data within one boundary. In a multi-tenant B2B platform, the same mistake can expose data across customers. When an AI agent, such as a DevOps assistant, operates across GitHub, Linear, and Slack for multiple enterprises, tenant isolation becomes a hard security requirement rather than a best practice.
In the DevOps assistant scenario, each enterprise customer connects its own GitHub organization, Slack workspace, and Linear team. That means each tenant must have independently scoped credentials, stored separately, and never reused across organizations. If a GitHub refresh token from Tenant A is stored in a shared table without strict tenant binding, or if Slack bot credentials are cached globally rather than per workspace, the agent may accidentally execute actions in the wrong customer environment. These failures do not require malicious intent; they often emerge from subtle architectural shortcuts.
Multi-tenant amplification introduces three critical architectural requirements:
Without these controls, the DevOps assistant becomes a shared automation layer operating across customer boundaries, which is unacceptable in enterprise environments.
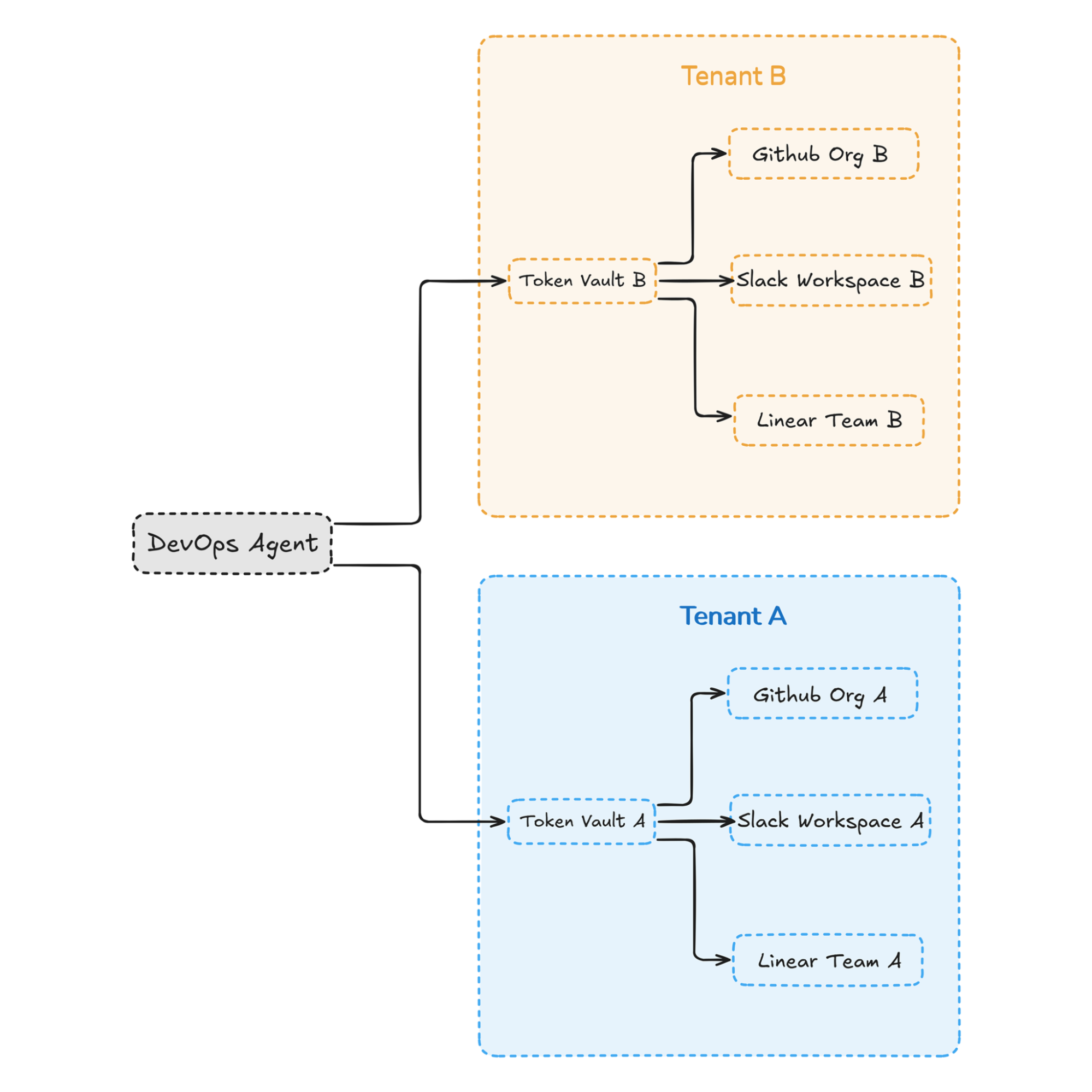
This model illustrates that the DevOps agent is logically shared as application code, but its credentials and connections must remain strictly tenant-isolated. The vault layer acts as the enforcement boundary that prevents cross-customer data exposure.
Once tenant isolation is enforced, the next architectural decision is how the agent will receive authorization within external systems. AI agents typically operate using either delegated user credentials or service-level identities. The choice affects auditability, lifecycle complexity, and enterprise risk posture.
In the DevOps assistant example, delegation occurs when an engineer authorizes GitHub access via OAuth. The assistant then reads pull requests and creates Linear issues under that engineer’s permission scope. This aligns with the principle of least privilege and provides clear user-level attribution. However, it tightly couples the agent’s authority to the engineer’s lifecycle. If the engineer leaves, changes roles, or revokes consent, the agent’s capabilities change immediately.
Service account models operate differently. The DevOps assistant may use a GitHub App installation, a Slack bot token, or an organization-level Linear API key. This improves operational stability because automation is not dependent on individual users. However, service credentials often carry broader permissions and therefore require stronger governance controls.
Most enterprise DevOps agents use a hybrid approach. User-attributable actions may rely on delegation, while background automation runs under service identities. The key requirement is explicitly modeling which actions require user-level attribution and which can safely operate under organizational credentials, rather than allowing the distinction to emerge implicitly.
Recommended Reading: Why Your Enterprise AI Investments Are Underperforming?
AI agents operate continuously and often hold long-lived credentials. Unlike short browser sessions, these tokens persist across workflows, refresh automatically, and execute actions without human supervision. This persistence increases both operational complexity and security risk.
In the DevOps assistant scenario, outbound tokens for GitHub, Slack, and Linear must be encrypted, tenant-bound, and lifecycle-managed. If refresh fails, consent is revoked, or scopes change, the agent must fail safely rather than silently continuing with stale access. Enterprise security teams evaluate how tokens are rotated, revoked, and audited.
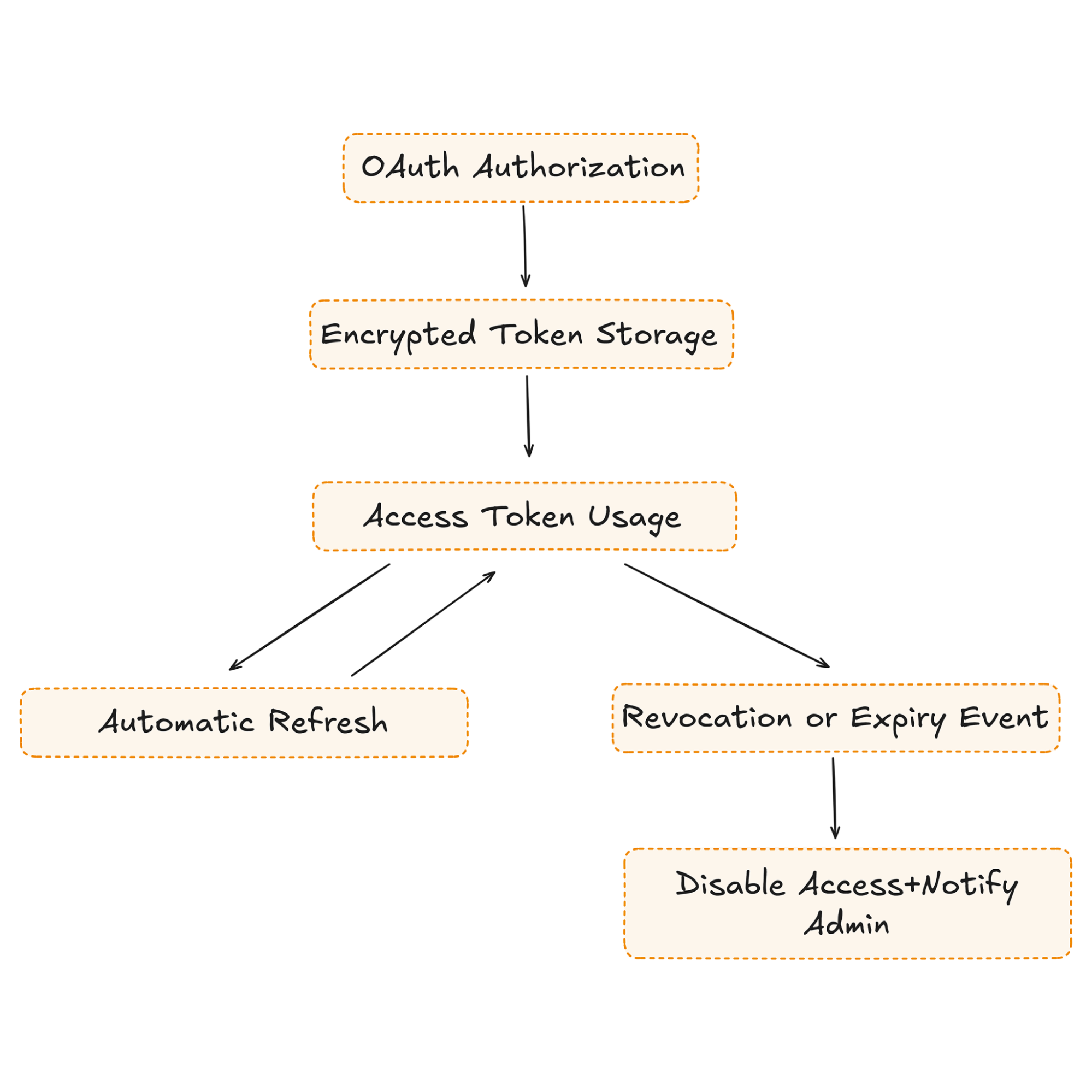
Credential governance for long-running agents requires encrypted storage, automatic refresh handling, revocation detection, audit logging, and administrative rotation controls. In enterprise environments, token management is a governance requirement, not an implementation detail.
In enterprise environments, the scopes granted to an AI agent define its effective blast radius. When a DevOps assistant requests access to GitHub repositories, Slack channels, or Linear projects, it is not merely enabling functionality; it is requesting specific permissions that determine what data can be read, modified, or transmitted. Security teams carefully evaluate these scopes because overly broad permissions can turn automation into systemic risk.
In the DevOps assistant scenario, GitHub scopes might include repository read access, pull request write permissions, or issue management rights. Slack scopes may allow posting to channels, reading message history, or accessing workspace metadata. Linear access may include creating and updating issues. Enterprises expect these permissions to be explicit, minimal, and justified. Granting blanket access, such as organization-wide write permissions, when only read access is required raises immediate concerns during security review.
Effective scope governance typically includes:
In multi-tenant SaaS systems, scope governance must operate on a per-tenant basis rather than globally. The DevOps assistant connected to Tenant A’s GitHub organization must not inherit broader scopes because Tenant B requires additional permissions. Designing per-tenant scope control ensures that each enterprise retains ownership over the authority granted to its agent instance.
By this point, the DevOps assistant has forced us to address inbound authentication, outbound credential management, tenant isolation, delegation models, token lifecycle governance, and scope control. None of these concerns resembles a simple API integration. They form a layered identity system that determines who controls the agent, what authority it holds, and how that authority is constrained across tenants.
Traditional integration thinking focuses on connectivity: connect GitHub, connect Slack, store tokens, and invoke APIs. Identity infrastructure thinking focuses on boundaries: establishing tenant ownership, enforcing role-based control, binding credentials to organizations, isolating tokens, governing scopes, and managing lifecycle events. The DevOps assistant operates across multiple identity systems, so authentication must be designed as a core platform capability rather than an integration detail.
The distinction becomes clearer when comparing the two approaches:
When AI agents operate continuously across customer environments, authentication becomes a structural component of the platform. Treating it as infrastructure ensures that tenant isolation, credential governance, and consent enforcement are built into the architecture rather than layered on later.
Correctly designing agent authentication requires separating application logic from credential orchestration. In the DevOps assistant scenario, the complexity does not lie in calling GitHub or Slack APIs. It lies in securely handling OAuth exchanges, safely storing issued credentials, and ensuring that agents retrieve valid tokens at runtime without embedding secrets in application code.
Scalekit Agent Auth focuses specifically on outbound authentication. It manages connector configuration, orchestrates OAuth flows with providers such as GitHub, Slack, and Linear, stores access and refresh tokens in an encrypted vault, and refreshes them automatically when needed. Your application maps internal tenant context to connectors and connected accounts, while Scalekit governs credential lifecycle and secure retrieval.
The flow below illustrates how outbound credential orchestration works in practice.
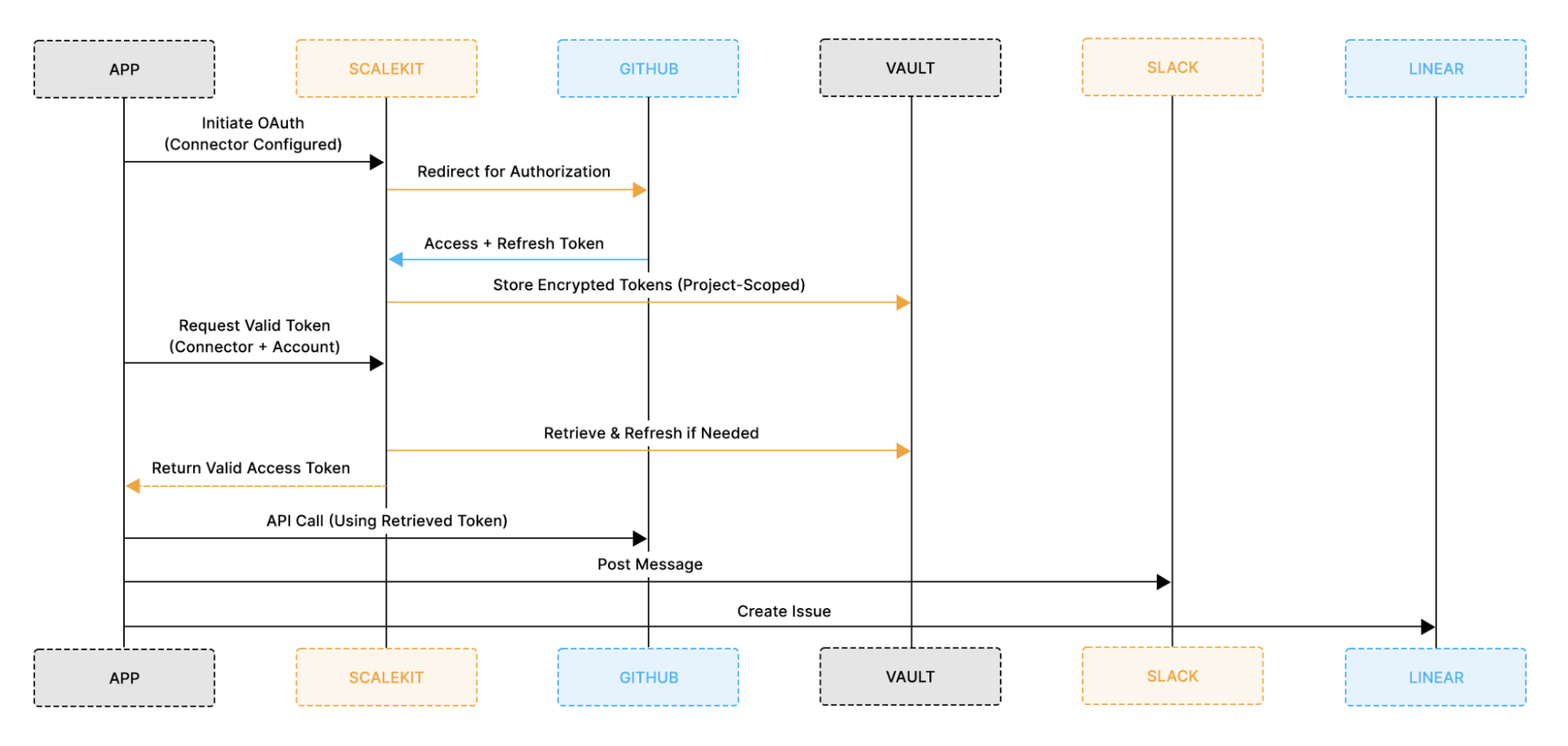
The diagram separates outbound authentication into two phases:
1. OAuth Setup Phase
2. Agent Runtime Phase
This model ensures that:
Outbound authentication governs the capability outside your platform. It determines what the agent can access in external systems and how credentials are issued, scoped, stored, and refreshed. Without proper outbound governance, tokens can become long-lived, over-privileged, or misbound across tenants. However, outbound capability alone is not sufficient. Every external integration must originate from a properly authorized, tenant-scoped control boundary within your platform.
Secure agent architecture, therefore, requires enforcing two independent boundaries: control and capability. Inbound identity ensures that only authorized administrators can configure integrations. Outbound identity ensures that agents use scoped, governed credentials when interacting with external systems. Both layers must operate independently but consistently.
Outbound authentication is more than an OAuth redirect. In production systems, it requires structured connector configuration, tenant-bound account binding, and governed credential lifecycle management. The UI below demonstrates how Scalekit models outbound authentication as connectors and connected accounts, separating provider configuration from credential state.
Connectors represent external systems such as GitHub, Slack, or Linear. Each connector encapsulates provider configuration, OAuth settings, and operational status.
This standardizes how your application initiates authorization flows while keeping provider-specific logic abstracted.
When an administrator authorizes a provider, the OAuth exchange produces a connected account. Connected accounts bind issued credentials to a unique identifier, such as a tenant or user context.
This ensures that tokens are not global. They are scoped, identifiable, and independently manageable.
Each connected account maintains authentication state, unique identifiers, and revocation controls. This allows administrators to audit, rotate, or disable credentials without impacting unrelated tenants.
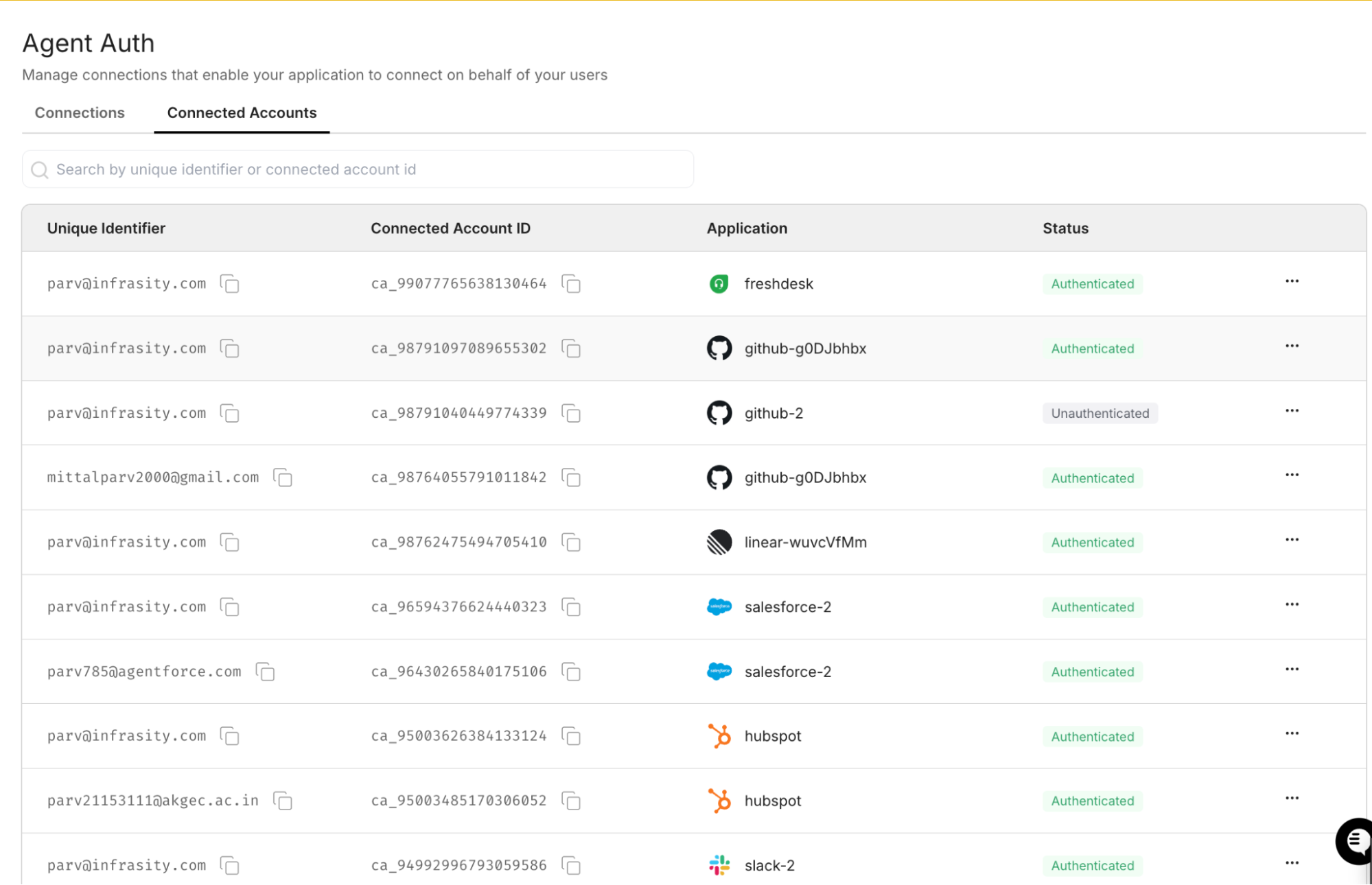
Separating connectors from connected accounts enforces tenant isolation and precise lifecycle management.
Outbound authentication is not just an OAuth redirect. In multi-tenant AI systems, the lifecycle consists of connector configuration, account binding, token issuance, secure storage, and runtime retrieval.
The example below demonstrates how outbound OAuth orchestration works using Gmail, but the same pattern applies to GitHub, Slack, Linear, and other providers.
A connected account binds an external provider to an identifier in your system.
This step establishes a tenant-scoped credential container. It does not yet grant access.
If the account is not active, generate an authorization link:
Scalekit handles:
When the agent needs to act:
Scalekit ensures the returned token is:
The agent can then call external APIs using the scoped credential. For a complete step-by-step implementation guide, refer to the Scalekit Agent Auth Quickstart documentation.
While Scalekit Agent Auth focuses on outbound OAuth orchestration and credential governance, inbound identity remains the foundation of control for multi-tenant SaaS systems. Inbound authentication determines who is allowed to configure connectors, approve scopes, revoke integrations, and manage agent behavior within a tenant. Without this layer, external access could be granted without clear ownership or administrative accountability.
Inbound identity typically involves enterprise SSO using SAML or OIDC, deterministic tenant resolution, and role-based authorization. When an enterprise user authenticates, the platform resolves the tenant context and applies administrative roles before allowing integration setup. This ensures that the authority to grant outbound access is tenant-scoped, auditable, and tied to an authenticated enterprise identity.
Scalekit provides enterprise SSO capabilities as a separate identity layer. When combined with Agent Auth, inbound identity governs control within your application, while Agent Auth governs capability outside it. This separation preserves clear trust boundaries: enterprise users authenticate into your platform under tenant-bound roles, and agents retrieve external credentials only after those roles authorize integration setup.
AI agents are becoming persistent digital workers inside enterprise environments. They monitor repositories, coordinate workflows, generate tickets, and act across SaaS platforms using credentials that represent real authority. As their capabilities expand, they accumulate access across identity systems originally designed for human users and service accounts. Governing that authority requires architectural discipline rather than shortcuts to integration.
The DevOps assistant example illustrates how quickly automation evolves into identity infrastructure. What begins as a workflow enhancement becomes a system that reads private repositories, writes to project management tools, and posts into internal communication channels. Supporting this safely requires tenant-bound identity resolution, delegated flow orchestration, secure credential vaulting, scope governance, and lifecycle enforcement. These controls determine whether the system can withstand enterprise security review.
Agent authentication is not a feature layer or an OAuth configuration detail. It is the foundation of secure multi-tenant AI systems. B2B platforms that design identity boundaries intentionally will scale safely across enterprises. Platforms that treat authentication as plumbing will encounter security friction as adoption grows.
Agent authentication governs how AI agents are identified and authorized across systems. It ensures credentials are tenant-scoped, minimally privileged, auditable, and revocable in multi-tenant environments.
Inbound authentication governs who controls the agent inside your platform (SSO, tenant resolution, roles).
Outbound authentication governs what the agent can access in external systems (e.g., OAuth, scoped tokens, and lifecycle management).
Inbound defines control. Outbound defines capability.
In multi-tenant SaaS, a misbound or shared token can expose data across customers. Each tenant must have isolated connectors, encrypted token storage, and strict tenant resolution at execution time.
Delegated credentials provide user-level attribution but depend on the user lifecycle. Service accounts provide stability but may carry broader permissions. Most enterprise systems use a hybrid model.
Long-lived tokens require encrypted storage, automatic refresh handling, revocation detection, audit logging, and administrative rotation controls. Lifecycle governance is mandatory for enterprise deployments.
No. OAuth connects APIs. Agent authentication governs identity boundaries, scope control, tenant isolation, and credential lifecycle across systems.
No. Enterprise SSO governs inbound identity and tenant control. Scalekit Agent Auth governs outbound OAuth orchestration and credential lifecycle management.
Scalekit manages connector configuration, OAuth flow orchestration, encrypted token vaulting, automatic refresh, and runtime-scoped credential retrieval. Your application maps tenants; Scalekit governs the credential lifecycle.
Revoked or deprovisioned credentials must be invalidated immediately. Agents should fail safely and require reauthorization rather than continuing with stale access.
AI agents are becoming persistent digital workers with cross-system authority. As their scope grows, identity governance becomes essential for secure enterprise deployment.




.webp)


