Granola MCP vs Granola API for AI Agents (2026)


TL;DR
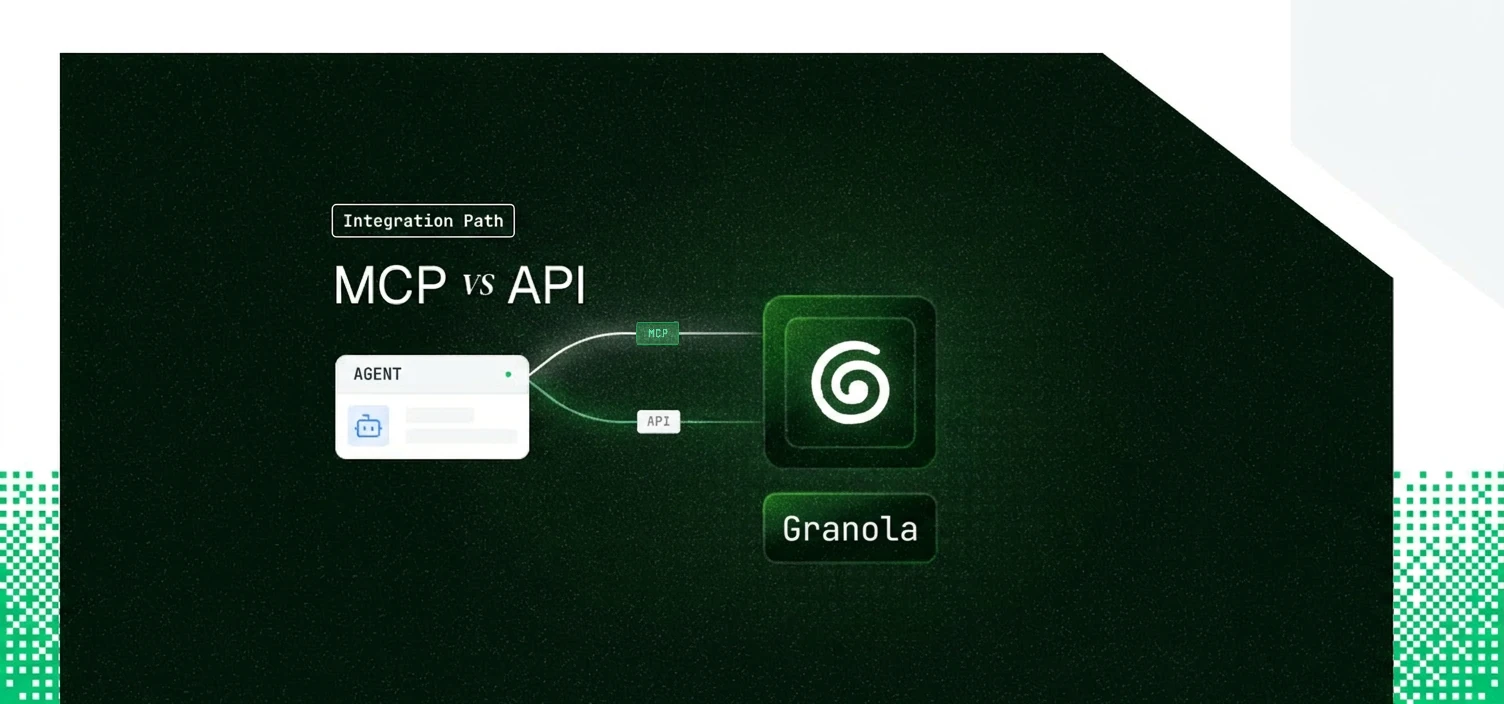
- Granola MCP and the Granola API are both read-only and cover overlapping meeting data, but the tool surfaces differ. MCP adds a natural-language query tool (query_granola_meetings) the API has no equivalent for; the API adds a discrete folder endpoint and reaches Team space content that MCP cannot.
- The auth models are inverted. Granola MCP is browser-based OAuth 2.0 with Dynamic Client Registration (DCR) only, with no API key or service account. The Granola API is API key only (Bearer grn_), with no OAuth flow at all. Your credential model changes completely depending on which you pick.
- Neither path writes data, fires webhooks, or exposes a native audit trail. If your agent needs to act on Granola rather than read it, neither surface does that today.
- MCP is the path for interactive, user-present agents. The API's static key is the path for headless, scheduled, multi-tenant backends.
- For multi-tenant B2B agents, both paths leave per-user credential isolation to you. Scalekit's Granola and Granola MCP connectors vault the credential, scope it per user, and log every call, so the MCP vs API choice does not change your auth infrastructure.
Your agent needs to work with Granola meeting notes. It has to pull last week's customer call, lift out the action items, and feed them into the rest of your stack. Granola now ships two ways in: a hosted MCP server at mcp.granola.ai and a public REST API at public-api.granola.ai. They are not the same thing, and the difference is sharper than with most tools: the two paths force opposite authentication models. Here is how to pick.
What Granola MCP and Granola API actually are
Granola MCP
The Granola MCP server is Granola's official hosted endpoint at https://mcp.granola.ai/mcp, launched April 1, 2026, and currently generally available to test. Transport is Streamable HTTP. Authentication is browser-based OAuth 2.0 with Dynamic Client Registration, so credentials are negotiated automatically; you never register a client ID or secret. Each user signs in to their own Granola account through the browser flow. There is no API key or service account method for MCP. Official pages: the launch post and the MCP docs.
Granola API
The Granola API is a RESTful interface at https://public-api.granola.ai/v1, first released in February 2026 and at version 1.2.0 as of May 2026. It gives programmatic, read-only access to meeting notes, transcripts, summaries, and folders. Authentication is a Bearer API key prefixed grn_, generated by a workspace member from the Granola desktop app. Business-plan members can create keys; on Enterprise plans, admins gate which access scopes a key may carry. Official reference: the Granola API docs.
Comparing them where it matters for agents
What your agent can actually do
Both surfaces read meeting data. Neither writes it. The table covers the actions that matter for an agent.
Where the gaps actually are
Two differences decide most builds. MCP carries query_granola_meetings, which runs Granola Chat server-side and returns a cited answer; the API has nothing like it and expects you to fetch notes and reason over them yourself. The API, in turn, reaches Team space content through its Public notes scope, while MCP is confined to a user's private "My notes" space and can never see Team space folders. Everything else is close to parity on read.
Tool-by-tool: the official MCP surface
From Granola's MCP documentation, the server exposes six tools:
Tool-by-tool: the official API surface
The API reference lists exactly three read endpoints:
What neither path can do
No create, update, or delete. No webhooks or change events. No native audit log of who read what. The API only returns notes that already have a generated AI summary and transcript; notes still processing are excluded from List Notes and return a 404 on Get Note. MCP cannot see Team space folders at all. If your workflow depends on writing back to Granola or reacting to changes in real time, neither surface supports it today.
The auth path each one puts you on
This is where Granola diverges most from other tools in this series. The MCP path is OAuth 2.0, browser-based, with DCR: per user, no static credential, interactive only. A background job with no user at the keyboard cannot complete that flow.
The API path is the opposite. A static Bearer grn_ key, no browser, no redirect. That is what makes it the headless-friendly path. The tradeoff is that the key is long-lived and revoke-only, with no rotation built in.
For a multi-tenant B2B agent, the structural point holds either way: MCP gives you one OAuth token per user, the API gives you one key per user (or one workspace key per org). In neither case does the path itself store, rotate, or revoke those credentials. That is infrastructure you build or buy.
What you own in production
With either path you own pagination, retries, and rate-limit handling. The API allows a burst of 25 requests per 5 seconds and a sustained 5 requests per second (300 per minute), returning 429 when exceeded; MCP averages around 100 requests per minute across tools and varies by plan. Because neither path has webhooks, freshness means polling. MCP tool availability can shift while it is "GA to test," so treat its surface as a moving contract. The API is explicitly versioned at 1.2.0, so you pin a version and migrate on your schedule. The absence of a native audit trail, documented for the API by downstream integrators, means observability is on you.
When to use Granola MCP
- Interactive, user-present agents: an assistant in Claude, ChatGPT, Cursor, or Claude Code where the user completes OAuth
- Natural-language recall over meetings, where query_granola_meetings does the retrieval and returns cited answers
- Prototypes where you want zero credential setup, since DCR handles client registration
- Single-user or personal automation scoped to the user's own private notes
When to use the Granola API
- Headless and scheduled agents: nightly note syncs, CRM enrichment jobs, digest builders, with no user present at execution time
- Backends that need Team space (workspace-wide) content, which MCP cannot reach
- Deterministic pipelines that need stable cursor pagination and an explicit folder hierarchy
- Multi-tenant services using a workspace-level Enterprise key per org, or per-user personal keys
Building on Granola with Scalekit
The credential problem on both paths
Whichever path you choose, every user has their own Granola credential. Fifty customers means fifty OAuth tokens or fifty API keys, each with its own lifecycle. The API key is long-lived and revoke-only, so a leaked or stale key keeps working until someone manually kills it, and the API surfaces no audit trail, so you cannot tell which key read which note. MCP's per-user OAuth token carries the same storage, refresh, and revocation burden. Neither path gives you a vault, rotation logic, or per-user attribution.
Token Vault and per-user isolation
Scalekit's connectors store both credential types in a managed AES-256 token vault, namespaced per tenant. The credential is resolved server-side at request time and never enters your agent code, your logs, or the LLM context. Each tool call is scope-checked before it reaches Granola, and every call is logged against the user who authorized it, giving you the per-user audit trail the API does not provide natively. What the user cannot access, the agent cannot access.
Two connectors, one per path
Scalekit ships two Granola connectors so the MCP vs API choice does not change your auth code. The Granola connector (docs) takes the API path with Bearer Token auth and exposes granola_note_get and granola_notes_list. The Granola MCP connector (docs) takes the MCP path with OAuth 2.1 and DCR, exposing granolamcp_query_granola_meetings, granolamcp_list_meetings, granolamcp_get_meetings, and granolamcp_get_meeting_transcript.
Connect the Granola API path
The user supplies their grn_ key once; Scalekit vaults it and injects it on every call. Your code passes a connectionName and a user identifier, never the token. The connection name string must match the connection you configured in the Scalekit dashboard.
Connect the Granola MCP path
The MCP connector handles OAuth 2.1 and DCR negotiation. Generate an authorization link for the user, then call execute_tool after they sign in. The connection_name here is granolamcp and must match your dashboard configuration.
Use it from Claude
Fetch the tools scoped to the current user with list_scoped_tools, hand them to Claude in its native schema format, and run the tool-use loop. The agent receives only the tools the user's connected account authorizes, not a full catalog.
Use it from LangChain
actions.langchain.get_tools returns native StructuredTool objects, so there is no schema reshaping. Bind them to your model and run the loop.
Downstream tool calling and observability
Reading Granola is rarely the whole job. The agent fans the result into HubSpot, Slack, a CRM, or a ticket. Here list_scoped_tools returns only the tools the current user authorized across every connector, so the agent works from a 5-to-10 tool surface instead of a full catalog. That improves tool selection accuracy and cuts the token overhead a large catalog burns before any work starts.
Observability follows the same model. Every call across every connector lands in one audit log keyed to the authorizing user, exportable for SOC 2 evidence and incident review. This is the per-user attribution that the Granola API does not provide on its own. For N tenants, you add a user identifier, not a new auth implementation.
When a capability is not there yet
Scalekit's Granola API connector currently surfaces granola_note_get and granola_notes_list; the List Folders endpoint, plus the MCP get_account_info and list_meeting_folders tools, are not yet exposed. If your agent needs one of these, request it in the Scalekit Slack community, through Talk to us, or by booking time with a Scalekit engineer.
Which one to build against
If your agent is interactive and a user is present to authorize, build on Granola MCP. The OAuth and DCR handling is automatic, and query_granola_meetings gives you cited natural-language recall with no retrieval code of your own. If your agent runs headless, needs Team space content, or has to run deterministic scheduled pipelines, build on the API with its static key. Most production deployments use both: MCP for the user-facing assistant, the API for the background sync. Either way, neither path manages per-user credentials, rotation, revocation, or audit, and that is the part that needs production-grade infrastructure.
Browse the Scalekit Granola connector: scalekit.com/connectors/granola
Browse the Scalekit Granola MCP connector: scalekit.com/connectors/granolamcp


.png)