Post-Call CRM Agent: Granola, HubSpot, Gmail, Slack; no Auth Plumbing
.png)


TL;DR
- Problem statement: Post-call admin is manual and painful because the data exists, but is trapped in one system while 3 others might be waiting for it.
- Engineering solution: This guide builds an AI agent that closes that gap: reads the Granola transcript, updates the HubSpot deal record, creates a Gmail draft, and posts a Slack summary; all within 30 seconds of a call ending.
- Authentication Challenge: Managing auth across 4 heterogeneous systems (Granola, HubSpot, Gmail, Slack), each with distinct token lifetimes, scope models, and failure modes — in a single multi-tenant agent pipeline without leaking credentials across user contexts.
- Authentication solution: Authentication across all 4 systems (including Granola's MCP-based OAuth and HubSpot's 30-minute token expiry) is handled by Scalekit – eliminating token management, refresh logic, and scope configuration. The pipeline is fully automated. No token management in your code. No manual CRM updates for your reps.
- Agent resources: The full source code is available on GitHub and can be run with your Scalekit, Granola, HubSpot, Gmail, and Slack credentials in under 10 minutes.
The moment a sales call ends, the data you need is already sitting in a Granola transcript. The problem is that HubSpot, Gmail, and Slack don't know that. Getting structured deal updates, follow-up drafts, and team summaries out of a raw transcript automatically, across every call, means connecting 4 systems with each having their own auth model, token lifecycle, and failure modes. That's the engineering problem this guide solves: building AI agents without any auth headache.
How Does Transcript Data Flow Into CRM Systems?
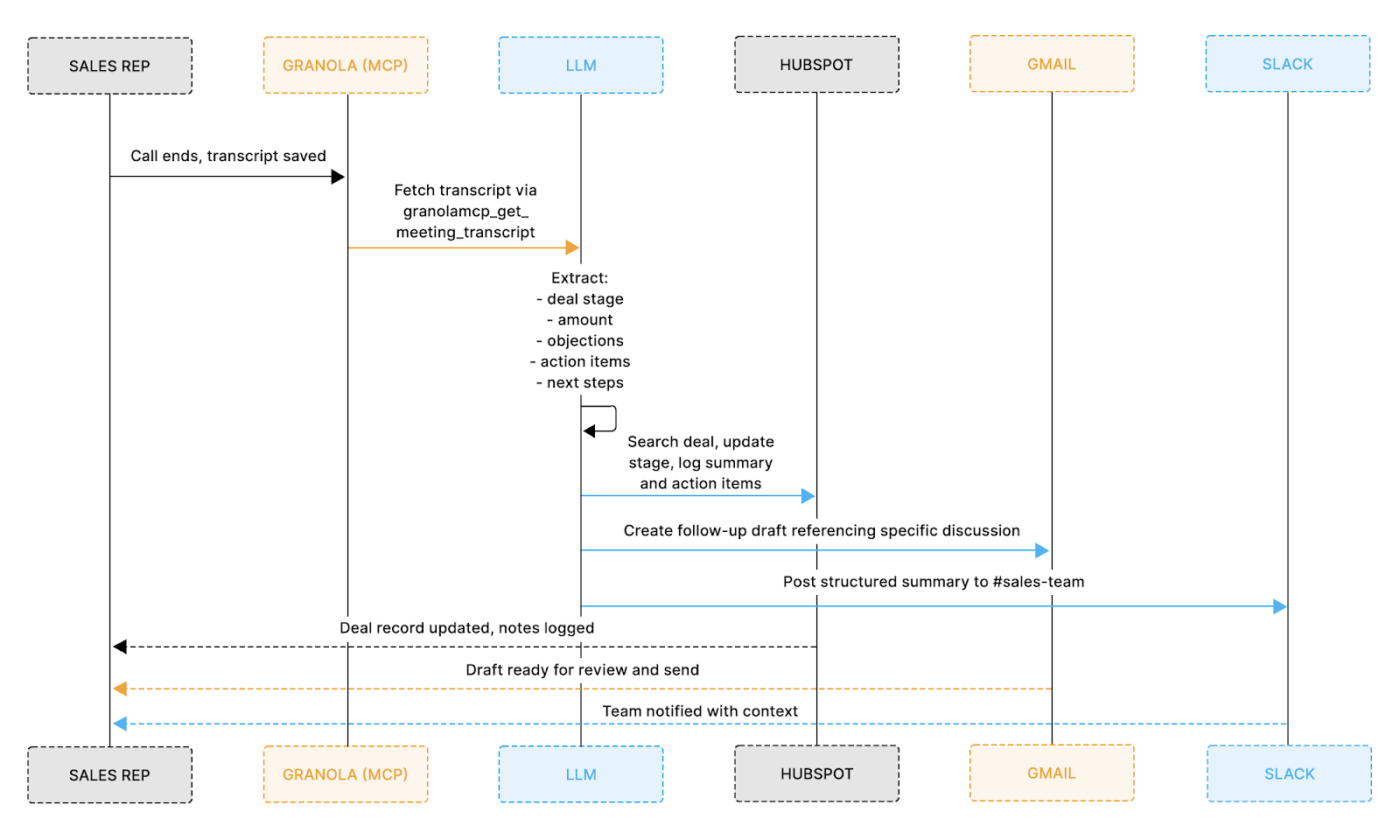
Once a call ends, the agent runs a five-step pipeline that takes the raw Granola transcript and pushes structured updates across HubSpot, Gmail, and Slack, all without the representative touching anything.
Here's exactly how the data moves:
- Read: The agent pulls the completed transcript directly from Granola
- Extract: An LLM identifies key deal information, such as company name, deal stage, objections raised, and agreed next steps
- Update: That structured data updates the HubSpot deal record with the latest stage, call summary, and action items
- Draft: A personalized follow-up email is generated from the actual conversation and saved to Gmail Drafts for the rep to review
- Notify: A concise summary is posted to your team's Slack channel so everyone is immediately in the loop
The diagram below shows how that data flows across each system end-to-end:
What Happens After a Sales Call Ends
Most representatives spend 15–20 minutes after every call doing the same thing: skimming the transcript, copying notes into HubSpot, drafting a follow-up, and pasting a summary into Slack. This agent eliminates all of that.
By the time you close your laptop, here's what's already done:
- HubSpot: deal stage updated, call summary logged, action items recorded
- Gmail: a follow-up draft written from your actual conversation, not a generic template, sitting in Drafts ready for your review
- Slack: a structured call summary already posted to your team channel
The whole thing runs in under 30 seconds. LLM extraction takes 8–12 seconds, depending on transcript length, and each tool call to Granola, HubSpot, Gmail, and Slack completes in 2–3 seconds.
Prerequisites
Before starting, confirm the following are in place:
- Claude Code is installed, and a Scalekit account free tier works for the initial setup
- Granola MCP is available on all plans, but full transcript access is only available on the Business plan. The Basic plan limits queries to the last 30 days and does not include transcripts
- Active HubSpot, Gmail, and Slack accounts with sufficient permissions to create and update records
- Python 3.11+
Why Authentication Is the Hardest Part of Building a Post-Call Automation
Before writing any integration logic, this workflow introduces four separate authentication systems, each with distinct behaviors, constraints, and failure modes that must be handled correctly for the agent to run reliably.
Key challenges across these systems include:
- Granola uses browser-based OAuth with Dynamic Client Registration (DCR), which handles credentials automatically with no client ID or secret required. In isolation, this is straightforward, but managing it consistently alongside HubSpot, Gmail, and Slack, each with different auth patterns, is where complexity builds up
- HubSpot's access tokens expire every 30 minutes, a hard constraint. In any background workflow or event-triggered pipeline, a token acquired at session start is likely stale by the time a tool call fires. You need reliable refresh handling to avoid mid-execution failures.
- Gmail: The gmail.compose scope is classified as sensitive, introducing additional configuration and approval requirements. Getting scope selection wrong in either direction — under-scoping causes runtime failures, over-scoping causes enterprise IT admins to block the consent screen entirely.
- Slack produces two token types per install: a bot token and a user token. If your agent should act as the rep (not as a bot), you need user token scopes configured correctly. Getting the distinction wrong means messages post from the wrong identity with no error.
Managing all of this independently means writing token storage, refresh cycles, retries, and error handling for each system separately, which means building authentication capabilities would feast upon developer hours as it is one of the most time-consuming and failure-prone parts of AI agent development. That's exactly where Scalekit comes in.
How Scalekit Simplifies Post-Call Authentication
Scalekit provides a unified authentication layer designed specifically for agent-based workflows and multi-system integrations.
What Scalekit saves you from: dynamic client registration negotiation for Granola MCP, token refresh scheduling for HubSpot's 30-minute expiry, per-user token isolation across all four systems, revocation detection when a user disconnects an app, and scope configuration that has to stay in sync as your agent gains new capabilities. Your integration code calls execute_tool(). Everything between that call and a valid API response is invisible.
Basically, instead of managing each integration separately:
- Connectors are configured once through the Scalekit dashboard.
- All API interactions are executed through a single interface using execute_tool()
- Token refresh, scope management, and connection state are handled automatically.
This allows your agent developers to focus entirely on designing workflow execution rather than credential management, which becomes especially important when multiple services must be accessed reliably within a single run.
Here's how to get all four connectors configured in Scalekit before writing a single line of integration code.
How to Set Up Your Scalekit Connectors for Granola, HubSpot, Gmail, and Slack
Step 1: Create your Scalekit account and workspace
Go to scalekit.com and create a free account. Once inside, create a new workspace for this project. Your workspace gives you a SCALEKIT_ENV_URL, SCALEKIT_CLIENT_ID, and SCALEKIT_CLIENT_SECRET, which should be added to your .env file.
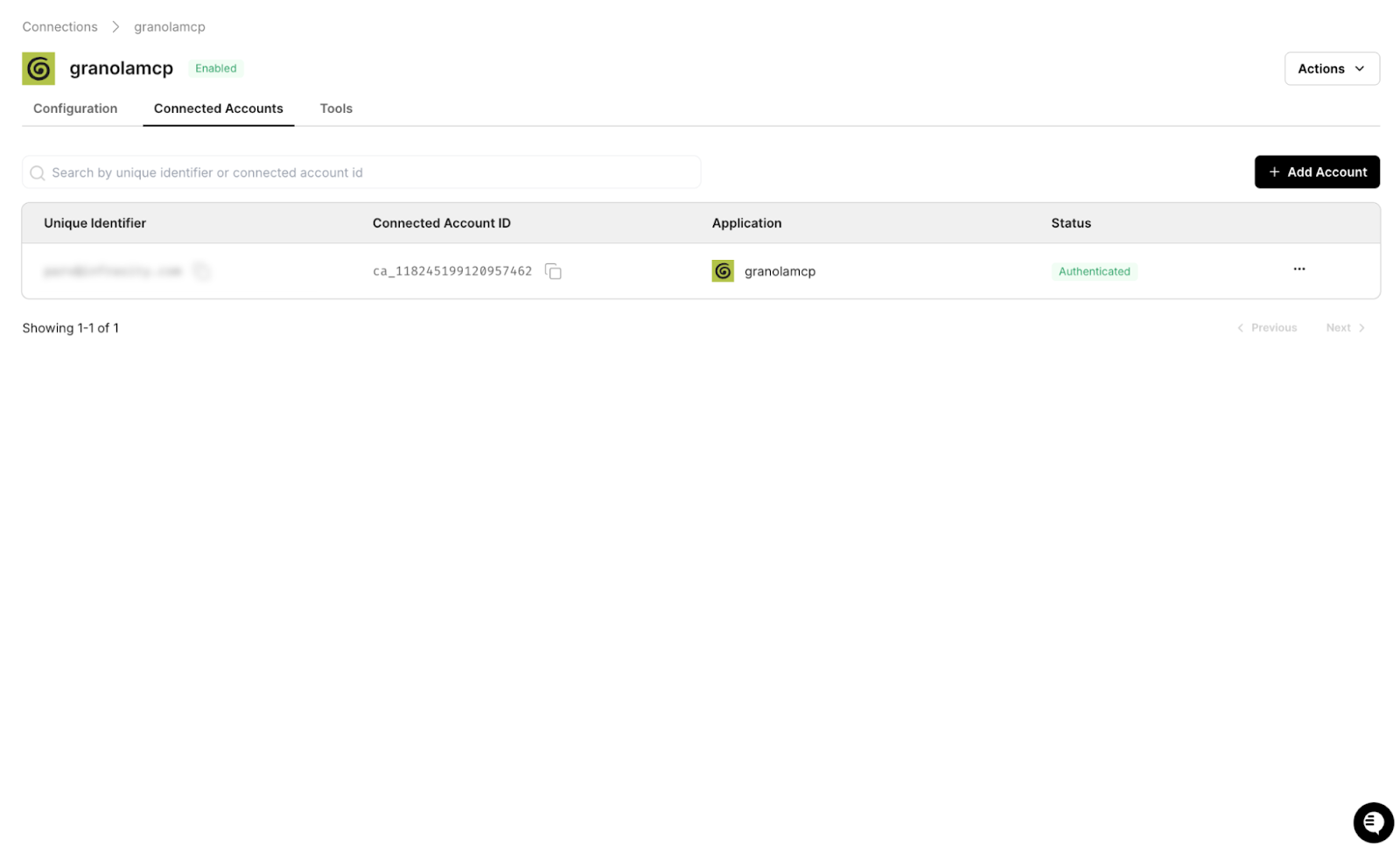
Step 2: Add the Granola connector
In the Scalekit dashboard, go to Connectors, search for Granola, and add it. The setup flow automatically handles Granola's MCP-based OAuth configuration.
Step 3: Add the HubSpot connector
Add HubSpot and select the required scopes: crm.objects.deals.read and crm.objects.deals.write. Scalekit manages token refresh for HubSpot's short-lived access tokens.
Step 4: Add the Gmail connector
Add Gmail and select the gmail.compose scope, which allows draft creation without full inbox access. Scalekit handles the sensitive scope flow.
Step 5: Add the Slack connector
Add Slack with the chat:write scope for posting messages to your target channel. Scalekit manages workspace-level OAuth configuration.
Once all connectors are active, every integration in this workflow maps directly to an execute_tool() call, and authentication is fully handled, allowing the remaining implementation to focus purely on data flow and logic.
Setting Up Auth with Claude Code
With the Scalekit plugin installed in Claude Code, the authentication layer across all four connectors can be configured in just two commands, eliminating the need to manually handle OAuth flows, token refresh logic, or scope management.
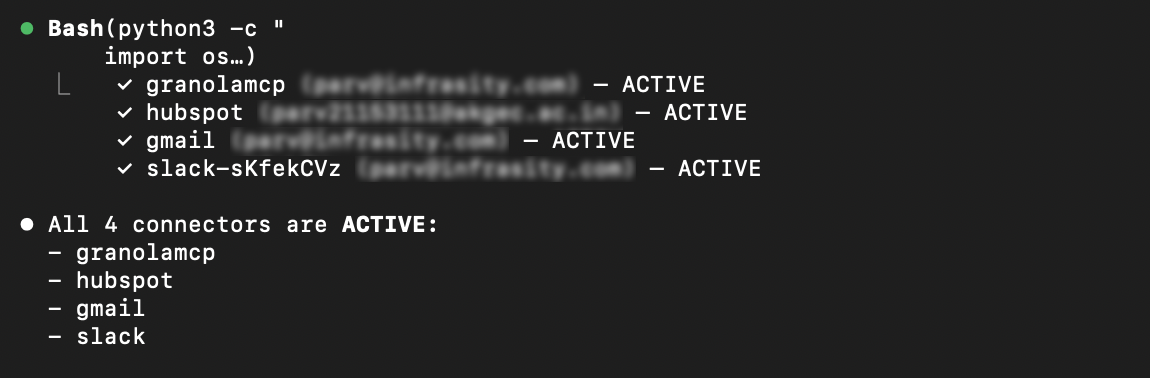
Run these two commands in your Claude Code terminal to install the Scalekit authentication plugin. This is what gives Claude Code the ability to manage connections to Granola, HubSpot, Gmail, and Slack:
Claude Code terminal showing both plugin install commands completing successfully with confirmation messages:

From there, give Claude Code this prompt to generate the Scalekit client and a reusable auth check function:
Claude Code generates the following:
Call ensure_authorized() once per connector at startup. On the first run for a new user, Scalekit prints a magic link. The user completes OAuth once, tokens are stored, and every subsequent run proceeds directly to ACTIVE. There is no token management code to write, no refresh logic to debug, and no scope configuration to maintain across connectors.
How to Connect Granola and Read Your Call Transcripts Automatically
Granola exposes meeting data through an MCP server, and Scalekit exposes that server through the same execute_tool() interface used by all other connectors in this workflow, so there is no MCP client to configure and no token fetching to implement. Interactions with Granola are handled in the same way as any other integration, using simple named tool calls.
The response includes the full transcript text alongside citation links back to specific timestamps in the Granola meeting. Passing these citations to the LLM allows the HubSpot note to include deep links that the representative or their manager can click through directly to the moment where a key objection was raised or a commitment was made. The structured extraction that follows produces everything the downstream steps need:
Granola app showing a real meeting transcript, meeting title, timestamps, and transcript text visible to show what the agent is reading from:
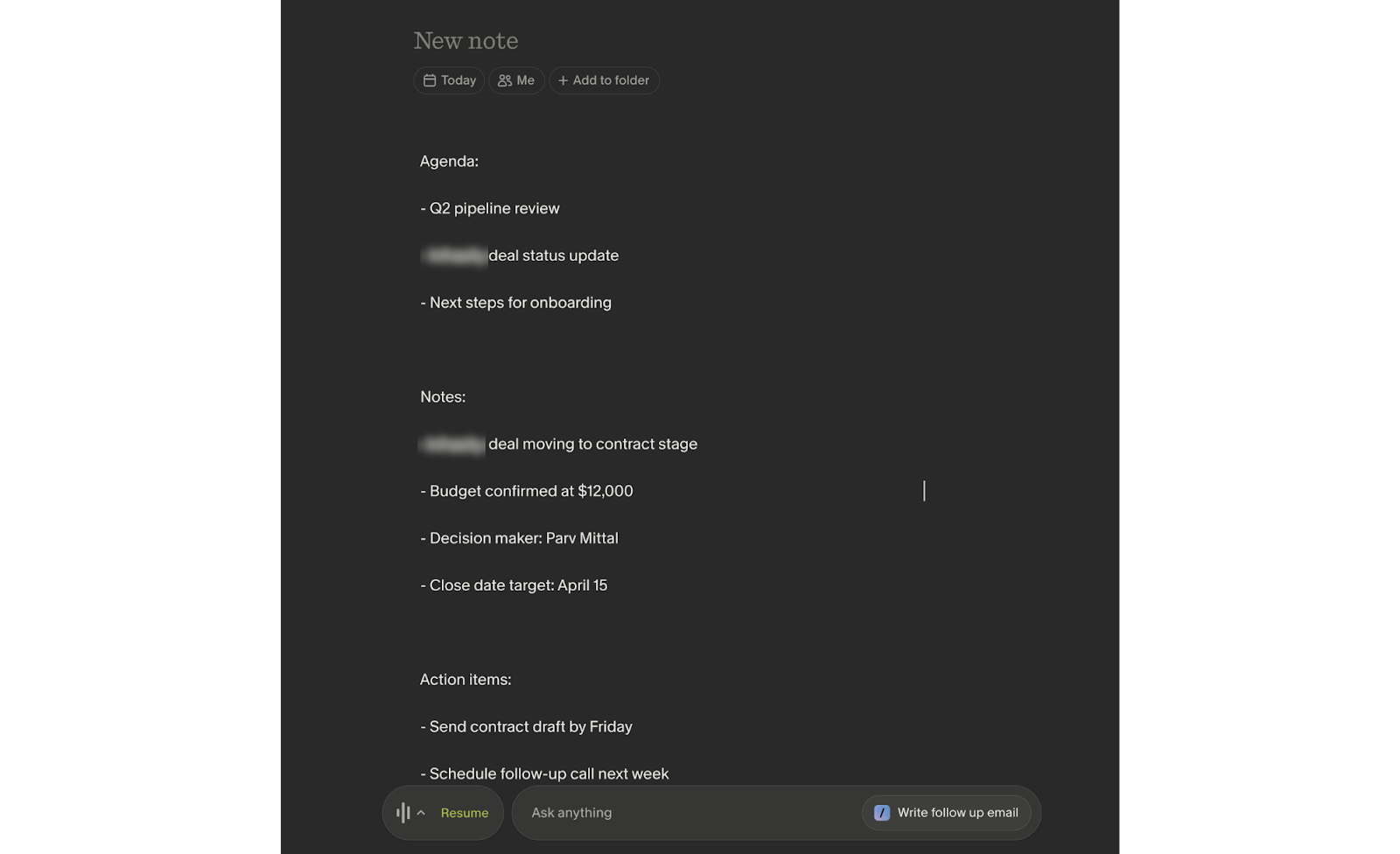
How to Automatically Update HubSpot Deal Records After Every Call
HubSpot's 30-minute token expiry is a known silent failure point for production agents. Tokens acquired at the start of a session expire mid-afternoon without any obvious error, and deal updates fail quietly. execute_tool() handles token refresh invisibly so the agent never needs to track token age or implement retry logic around credential failures.
Three tool calls cover the complete update workflow: search for the existing deal, create it if none is found, and write the meeting output to the deal record:
If your HubSpot instance uses custom properties such as competitor mentions, budget confirmed, or technical requirements flagged, they can be added directly to the properties dict using the same structure. No additional configuration is required.
HubSpot deal record showing the updated deal stage, call summary written in the description field, and action items listed below. This is the proof that the agent worked.
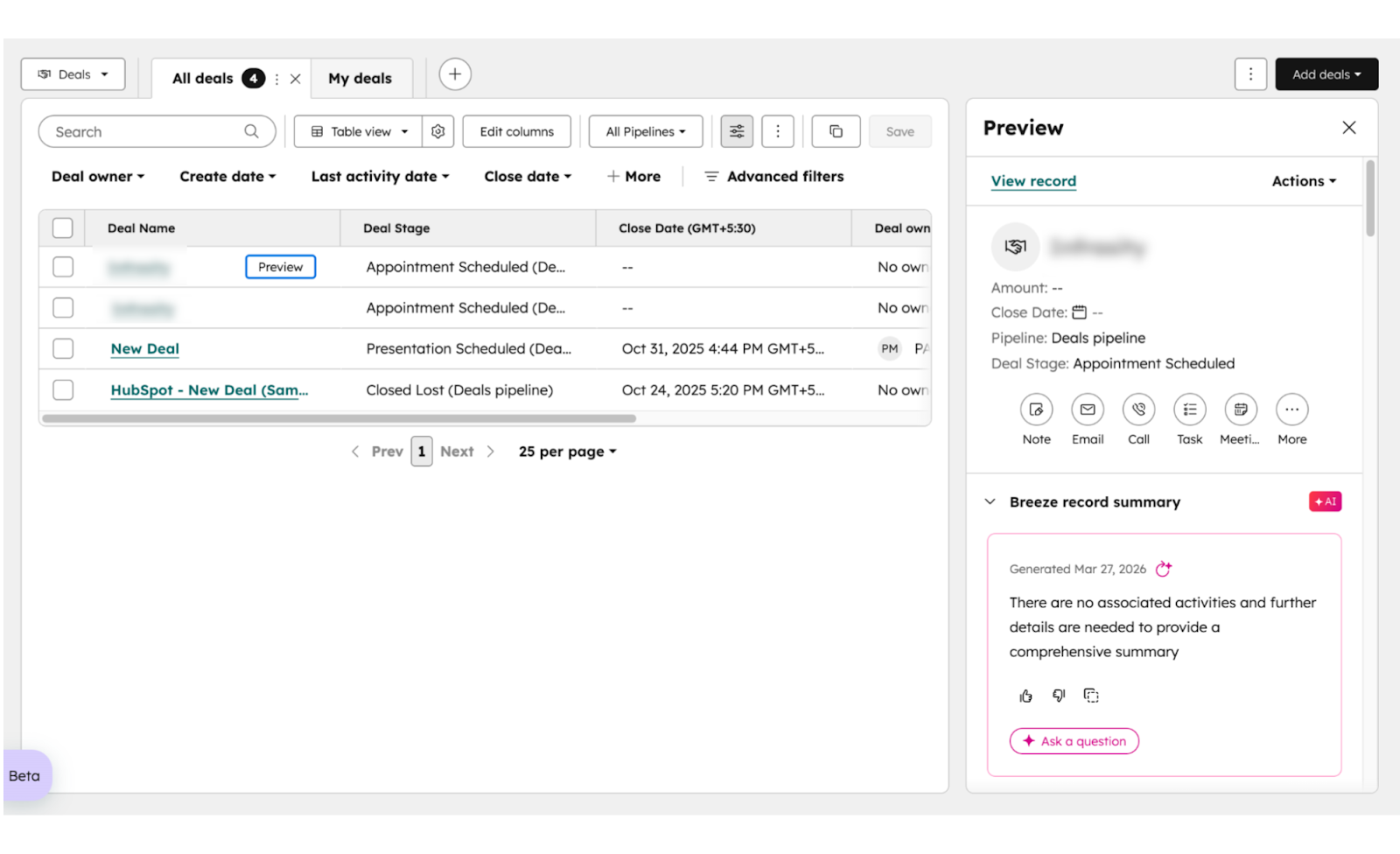
How to Auto-Generate a Personalized Follow-Up Email Draft in Gmail
Scalekit does not yet expose a gmail_create_draft tool, so this step retrieves a fresh OAuth token directly from get_connected_account() and calls the Gmail API using that token. Scalekit still manages the credential — calling get_connected_account() immediately before the API call guarantees a valid, refreshed token every time, regardless of how long the agent has been running.
The LLM-generated email body is constructed from the actual meeting content. It references the specific objection the prospect raised, confirms the agreed next step, and reads like something the sales representative wrote rather than a template pulled from a sequence. Critically, it lands in Gmail Drafts, not the Sent folder, and the sales representative opens it, makes any edits they want, and sends it when ready. The agent handles the work; the sales representative maintains ownership of the relationship.
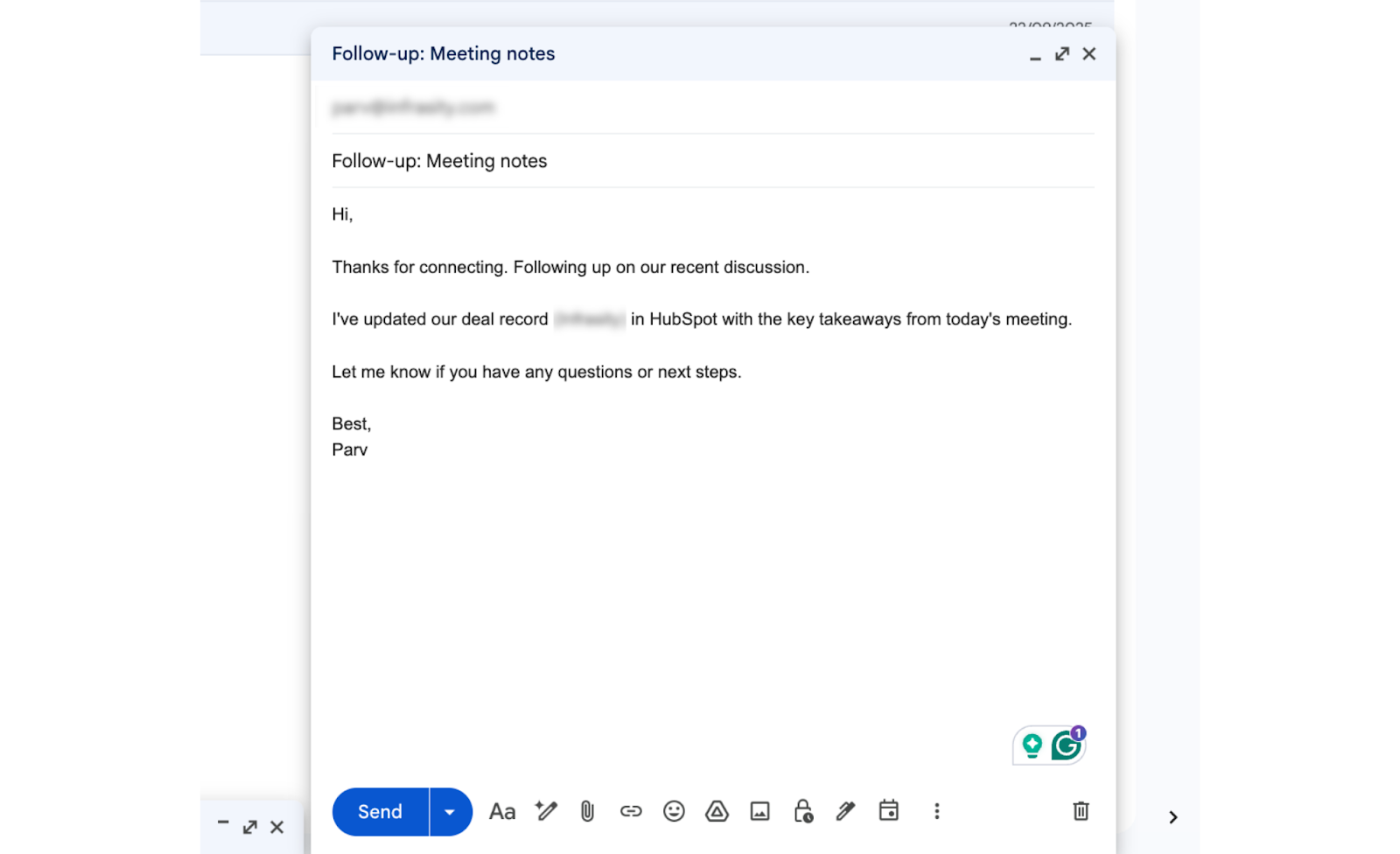
Gmail Drafts shows the generated email, including the subject line and the first 3 to 4 lines of the body, visible. Recipient email blurred if needed. This shows the email reads naturally, not like a template.
Here's what the agent actually generates: a Gmail draft written from the real conversation, referencing the prospect's specific objection and agreed next step, ready for the rep to review and send.
How to Run the Full Post-Call Automation Pipeline
Claude Code terminal run showing all four steps: Granola fetch, HubSpot update, Gmail draft, and Slack post, all completed successfully, with the total time displayed at the bottom.
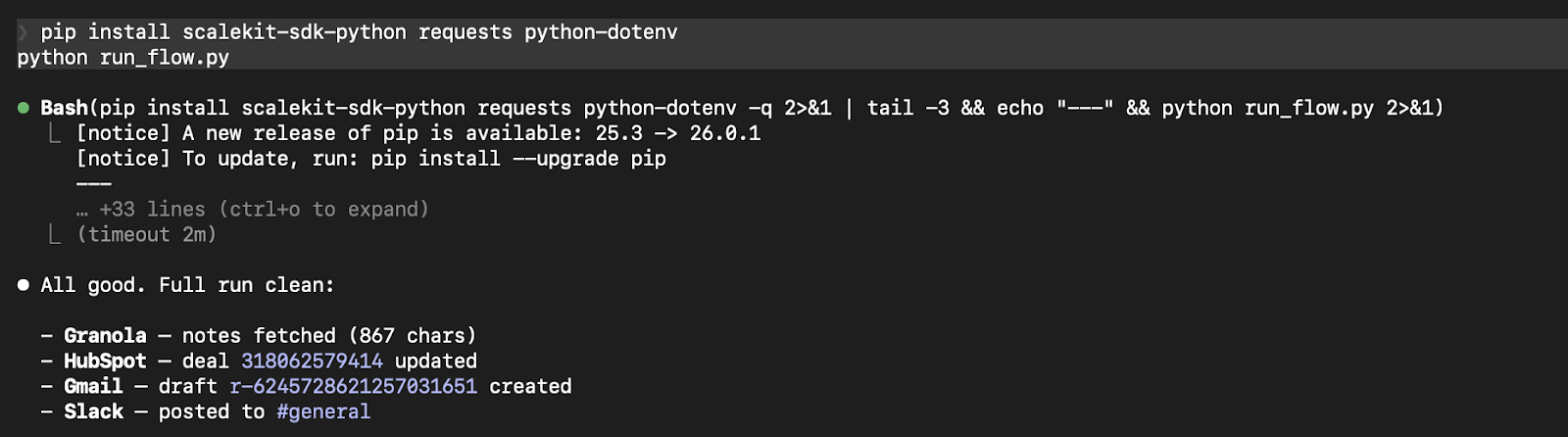
LLM extraction accounts for 8 to 12 seconds, depending on transcript length. Each execute_tool() call runs in 2 to 3 seconds. The full workflow completes consistently under 30 seconds for a standard 45 to 60-minute call before most sales representatives have even opened their CRM tab.
What to Check Before You Go Live
A few things to account for before running this in a live sales environment:
- Granola: The MCP server only surfaces notes where the authenticated user is the owner. Notes shared by a colleague are not accessible. If users ask the agent to query "team meetings," it will only return meetings the connected user personally recorded, so build your prompts and UX around this constraint. On the Basic plan, granolamcp_get_meeting_transcript returns an access error, not an empty result. MCP works on all plans, but full transcript history and webhook access are available only with the Business plan. The Basic plan only covers the last 30 days. Avoid high-frequency polling across concurrent users.
- HubSpot: HubSpot's access tokens expire every 30 minutes. Scalekit refreshes them proactively, but if you're calling the raw HubSpot API anywhere outside of execute_tool(), you're responsible for that refresh yourself. At scale, cache deal IDs by contact email to reduce redundant search calls.
- Gmail: If your Google Cloud project's OAuth consent screen is still in Testing mode with External user type, refresh tokens expire after 7 days, not the standard expiry. Promote to Production status before building anything multi-session or you'll see unexplained re-authorization prompts in production. Also: if you're in a Google Workspace environment, admin_policy_enforced can silently block scope access after authorization succeeds — there's no way to detect this programmatically in advance.
- Slack: channels:history and channels:read cover public channels only. Private channels need groups:history and groups:read. Multi-person DMs require mpim:history. A missing scope returns a missing_scope error at runtime, not an auth failure — it looks like a data access problem and is easy to misdiagnose. Confirm your scope set covers every channel type your agent needs before going live.
- Scheduling: Use Granola's meeting.completed webhook with a lightweight Flask endpoint for the cleanest setup, or a cron job every 5 minutes if you prefer simplicity.
Conclusion
Four systems. Four OAuth models. One agent. The Granola transcript doesn't change after the call ends — what changes is how quickly the rest of your stack reflects it. This agentic pipeline makes that propagation automatic, consistent, and invisible to the rep.
The auth layer here is worth noting separately: Granola MCP's dynamic client registration, HubSpot's 30-minute token expiry, Gmail's sensitive scope path, Slack's bot-vs-user token distinction — none of that is in the integration code. Scalekit maintains it all. You maintain none of it.
Once implemented, it becomes a reusable foundation for automating similar processes across the organization. The same extraction-and-dispatch pattern applies anywhere conversation data needs to become structured system updates: customer success handoffs, onboarding calls, renewal reviews, support escalations. Scalekit already has 2500+ execution tools across 150+ connectors, and more are on its way. Explore more production-ready agent workflow patterns to see what's possible.
Frequently Asked Questions
How does the agent handle authentication failures or token expiry?
Authentication is managed by Scalekit. Scalekit refreshes tokens before expiry and moves a connected account to REVOKED status when a user disconnects or a password-triggered revocation occurs (this is routine in enterprise Workspace deployments for Gmail). Check account.status before critical operations: a REVOKED status means to prompt the user to re-authorize rather than returning an opaque API error. Also, automated auth prevents mid-execution failures, especially for services like HubSpot, where tokens expire frequently.
How does the agent convert unstructured conversation data into CRM fields?
The LLM extracts structured information, such as deal stage, action items, and next steps, from the transcript context. This mapping can be refined by adjusting the extraction prompt to match your team's pipeline definitions and terminology.
How do you avoid processing the same meeting multiple times?
Each meeting should be tracked after processing, typically using a database or cache, so the agent can skip previously handled transcripts when using polling or retry mechanisms.
Can this workflow scale across multiple sales representatives or teams?
Yes. Each user connects their own accounts through Scalekit, and the agent runs within that user context, ensuring proper data isolation without shared credentials or cross-account conflicts.