Automating Salesforce customer insights with Slack and Scalekit


TL;DR
- Customer 360 insights agent automates visibility between Salesforce and Slack by pulling key Account and Opportunity signals, summarizing them, and posting concise digests with deep links into the proper Slack channels.
- Scalekit connectors handle authentication, retries, and rate-limits for Salesforce REST API and Slack Web API so that developers can focus purely on logic instead of managing tokens or SDK plumbing.
- Deterministic rules or optional LLM summarization turn raw CRM data into clear, human-readable insights while enforcing field-level permissions and automatically redacting PII.
- Governor-limit awareness and snapshotting ensure each scheduled run fetches only recent changes, avoiding duplicates and staying safely within Salesforce quotas.
- Deployment is straightforward: configure environment variables from .env, run the function run_customer_360() on a cron or CI pipeline, and your team starts every morning with real-time, compliant customer context inside Slack.
Introduction: When customer signals go unnoticed
Every customer-success engineer knows the chaos of chasing context across tabs. A Slack ping flags a renewal risk, Salesforce holds untouched opportunity notes, and buried emails contain key customer signals. By the time an account manager gathers all the information, the customer has already gone quiet, or the opportunity for an upsell has passed. What should have been a simple, proactive insight turns into a post-mortem meeting.
Salesforce holds the truth about every account, opportunity, and interaction, but that truth is locked away behind dashboards and search filters. Teams collaborate in Slack, not in Salesforce, which means valuable data often stays invisible until it’s too late. Manual reporting loops are slow, error-prone, and impossible to scale as the number of accounts grows.
This guide walks you through building a Salesforce-backed customer 360 insights agent that automates this visibility gap. You’ll learn how to extract key signals from Salesforce using SOQL, summarize them into concise insights (optionally powered by an LLM), and post-formatted updates directly into Slack with deep links, all while staying compliant with field-level permissions, governor limits, and PII safety.
From data chaos to unified insights: Why Customer 360 matters
Customer 360 isn’t just a Salesforce buzzword; it’s the idea that every customer interaction, opportunity, and support event contributes to a single, unified profile. In theory, it gives revenue and success teams complete visibility. In practice, that visibility often remains trapped behind Salesforce dashboards that are not checked daily. The result is context-rich data that never reaches the teams who act on it.
Slack, meanwhile, is where daily execution happens. Deals are discussed, renewals are pursued, and support escalations are addressed in real-time. The problem is that Slack conversations rarely pull fresh data from Salesforce automatically. A rep might mention a “high-value renewal,” but unless someone manually looks it up, the team lacks live context account health, deal stage, or recent opportunity changes.
That’s where a Customer 360 Insights Agent bridges the gap. Instead of expecting humans to cross-reference systems, the agent continuously extracts meaningful signals from Salesforce, summarizes them into human-readable insights, and posts those updates into Slack threads or channels. This transforms raw CRM data into operational awareness, ensuring every customer conversation begins with facts, not assumptions.
Designing the Salesforce-backed insights agent
Building a Customer 360 Insights Agent begins with understanding the data flow from Salesforce to Slack, while maintaining performance, permissions, and privacy. The agent’s job is simple: pull key account and opportunity signals, summarize them into human-friendly insights, and deliver them to Slack channels where teams actually work. To make that happen reliably, each component must play a distinct role.

Each step serves a real operational safeguard. Salesforce queries adhere to governor limits to prevent API throttling. The summarization process honors field-level visibility, ensuring users only see what their permissions allow. Before sending to Slack, a lightweight redactor strips sensitive fields, such as email addresses, phone numbers, or customer IDs. The result: clean, contextual insights that respect both technical and legal boundaries.
This architecture provides teams with live visibility without exposing private data, laying a sturdy foundation for building predictive or LLM-driven analytics later on.
Bootstrapping Scalekit and validating configuration
Setting up and configuring the environment safely
Environment configuration defines how your Insights Agent connects, authenticates, and behaves across Salesforce and Slack. In this project, configuration is handled entirely through a .env file, which is loaded via the Python dotenv module. The goal is to ensure a clean, reproducible setup that never exposes credentials in logs or code.
Each variable defines which organization you query, which Slack channel you post to, and how securely data is processed. Misconfiguration can cause missed insights or worse, send private data to the wrong workspace.
Required environment variables
The .env file defines all environment variables required for the agent to connect securely to Salesforce and Slack through Scalekit, control window sizes and record caps, and enable optional features like redaction and snapshots.
Configuration validation stops bad boots early. A thin, explicit layer keeps “missing secret” bugs out of production and makes failures obvious locally.
Secrets management keeps credentials out of logs and Git. Store .env only in local dev, inject env vars via your CI/CD for staging and prod, and never print tokens. For debugging, log only non-sensitive configuration (e.g., org domain, selected channel, cron).
Registering providers and wiring OAuth through Scalekit
Before your agent can fetch Slack messages or create GitHub issues, the users behind those actions must authorize Scalekit to act on their behalf.
This section demonstrates how to register those provider apps correctly and how to expose two small Flask routes that complete the OAuth handshake safely, ensuring that no tokens touch your code or database.
Step 1: Connect Slack through Scalekit (no manual Slack app setup needed)
You no longer need to manually create a custom Slack app. Scalekit already provides a verified Slack app that handles OAuth, scopes, and token management for you.
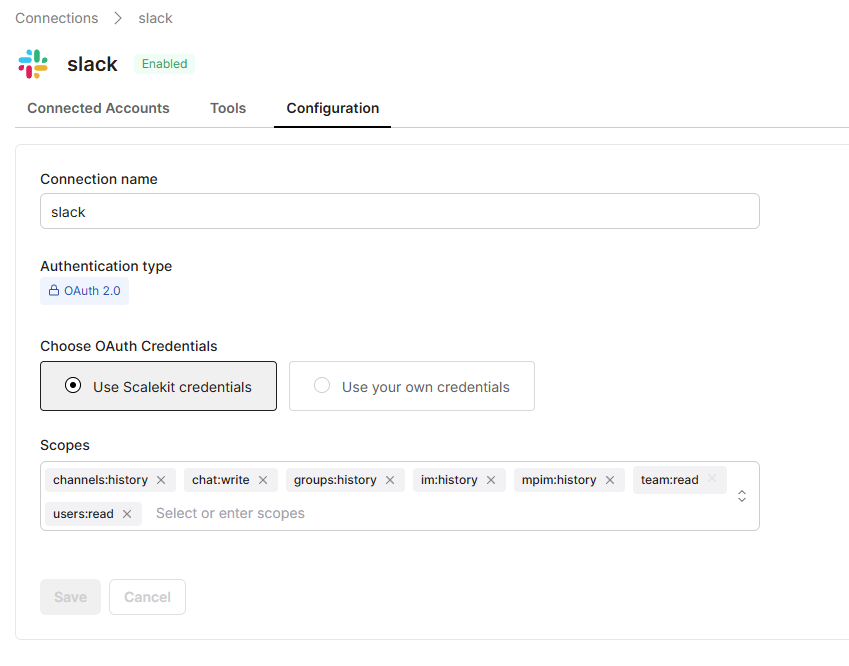
Open your Scalekit dashboard and navigate to Connections →Create Connection and select Slack. Here’s what you’ll see:
- Connection name: slack (default)
- Authentication type: OAuth 2.0
- Choose OAuth Credentials: select Use Scalekit credentials (recommended).
This tells Scalekit to use its managed Slack application instead of requiring your own client ID and secret.
- Scopes: keep the default minimal scopes: channels:history, groups:history, im:history, mpim:history, chat:write, team:read, users:read
These scopes allow the agent to:
- Read messages from public, private, and group channels
- Post replies in threads
- Identify workspace users and teams
After saving the configuration, simply authorize Slack by logging in with your workspace account when prompted in the browser. Scalekit completes the OAuth handshake, stores tokens securely, and exposes tools like slack_fetch_conversation_history and slack_send_message, fully authenticated for your connected account.
No Client ID, no Secret, and no custom Slack app creation required, Scalekit’s managed credentials and hosted Slack app handle it all automatically.
Step 2: Connect Salesforce through Scalekit
To enable OAuth access, create a Salesforce Connected App in your Developer org, note its Consumer Key and Secret, and assign the required scopes (full,id,lightning,openid, profile) before linking it to Scalekit.
Log in to your Salesforce org
Go to your Developer Edition or sandbox with administrative privileges.
Navigate to Setup → App Manager → New External Client App
Fill out basic information
- Connected App Name: e.g., Customer 360 Agent
- API Name: auto‐filled or entered manually
- Contact Email: admin email for notifications
Enable OAuth settings
- Check “Enable OAuth Settings”
- Enter a Callback / Redirect URL (for Scalekit, you might use the hosted redirect provided by Scalekit)
- Under “Selected OAuth Scopes,” add what your agent needs and ensure both sides authorize with identical permissions to avoid token mismatch issues.
- Save the connected app; note the Consumer Key (Client ID) and Consumer Secret (Client Secret), which you will use in Scalekit.
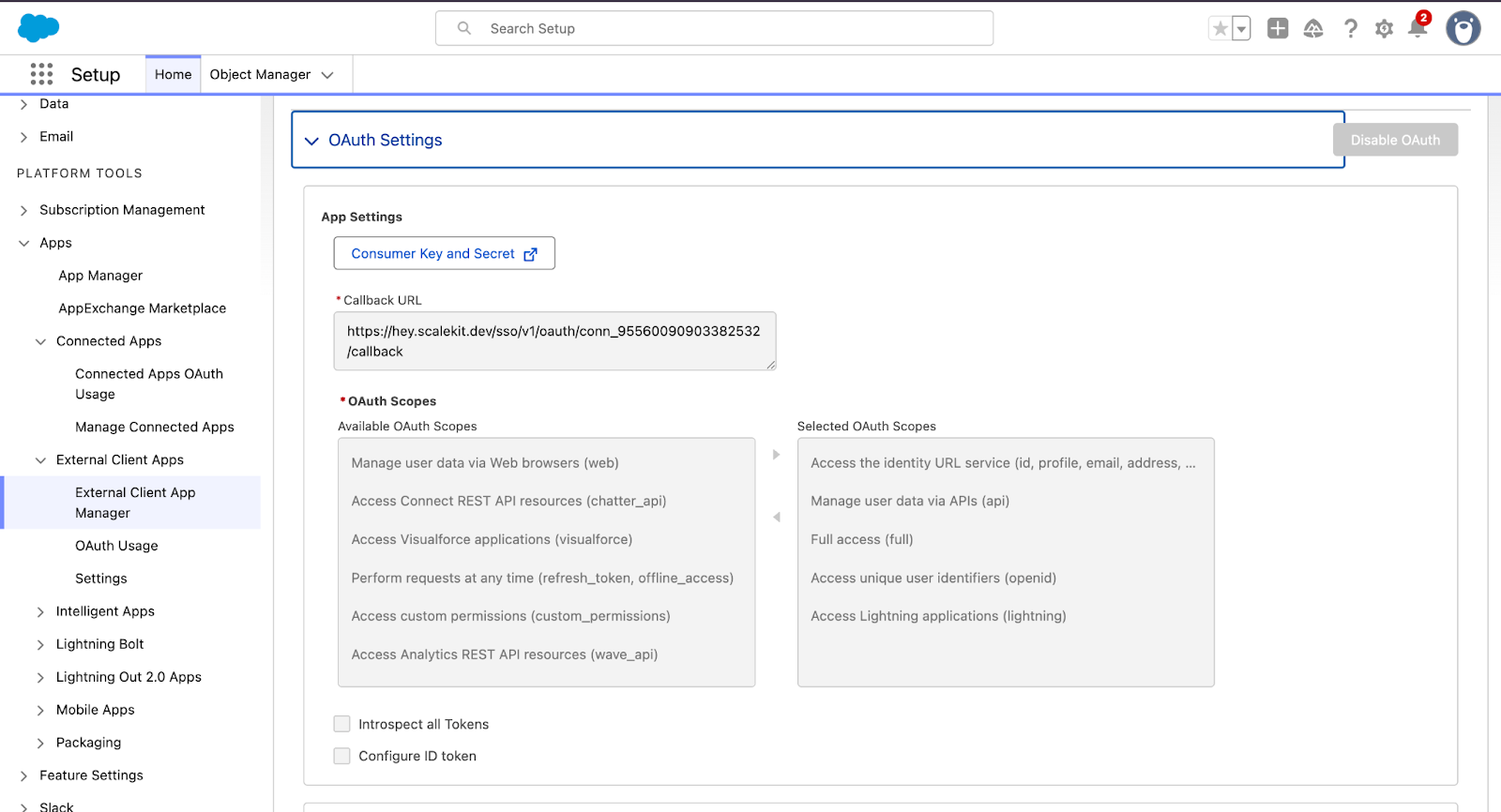
You no longer need to create or manage OAuth tokens in Salesforce manually. Scalekit provides a verified Salesforce connector that handles the Connected App handshake, OAuth flow, and token lifecycle automatically.

Open your Scalekit dashboard and navigate to Connections → Create Connection → Salesforce. Here’s what you’ll see:
- Connection name: salesforce (default)
- Authentication type: OAuth 2.0
- Choose OAuth Credentials: Select Use Scalekit credentials (recommended) → This instructs Scalekit to use its managed Salesforce application, eliminating the need for your own Client ID and Secret.
Scopes: Keep the default minimal scopes: full, id, lightning, openid, and profile. Ensure the same scopes are added in both your Salesforce Connected App and Scalekit connection for a seamless OAuth match.
After saving the configuration, authorize Salesforce by logging in with your org credentials when prompted in the browser. Scalekit completes the OAuth handshake, stores tokens securely, and exposes connector tools like salesforce_soql_execute, salesforce_query_soql, all fully authenticated for your account.
No Connected App hosting, no refresh-token scripts, and no client secrets in .env, Scalekit’s managed Salesforce connector takes care of OAuth, token rotation, and scope validation automatically.
Initializing the Scalekit client safely
Every interaction with Salesforce and Slack runs through Scalekit’s managed connectors.
Before fetching or posting anything, the agent needs to initialize a verified Scalekit client using environment variables, never hard-coded credentials.
Resilient API execution with exponential backoff
To guarantee reliability across integrations, the agent wraps every Salesforce and Slack API call inside a unified retry mechanism. The function execute_action_with_retry() is the core abstraction that standardizes error handling, exponential backoff, and safe logging for all Scalekit connector actions. It’s the unseen backbone that lets the Customer 360 Insights Agent recover gracefully from rate limits, transient network issues, or temporary service outages without manual intervention.
How does it keep your agent reliable
- Exponential backoff: Starts with a 1s wait, doubling each attempt, easing pressure on throttled APIs.
- Retry-aware logic: Looks for rate-limit, timeout, and temporary connection errors in ScalekitException messages.
- Controlled attempts: Respects RETRY_ATTEMPTS and RETRY_BACKOFF_SECONDS from settings, allowing safe tuning per environment.
- Transparent logging: Prints the tool name, attempt count, and a sanitized parameter preview to simplify debugging without exposing sensitive information.
- Fail-safe exit: Returns None after the final attempt, instead of throwing an error, ensuring the overall workflow completes gracefully.
This single helper is the reliability backbone of the Customer 360 Insights Agent, allowing Salesforce queries and Slack posts to recover automatically when APIs throttle or momentarily drop connections.
With the Scalekit client initialized and retry logic in place, the agent can now start pulling data confidently from Salesforce. Every query runs through the same fault-tolerant layer, ensuring transient API failures or governor limit hiccups never break the daily sync. The next step is to extract meaningful signals from Salesforce Accounts, Opportunities, and related objects using precise SOQL queries.
Extracting key account and opportunity signals with SOQL
Salesforce querying in this agent flows through a single gateway that’s resilient to tenant differences and transient errors. Queries are windowed (last N hours), field-selective, and limit-bounded to stay safely within governor limits.
1) The SOQL gateway: exec_soql(...)
exec_soql attempts multiple tool/parameter shapes to ensure compatibility across tenants without requiring code forks. Your retry layer wraps every call.
Different environments expose salesforce_query_soql or salesforce_soql_execute with query vs soql input. This chain makes your code portable.
2) The result normalizer: soql(...)
soql calls the gateway and normalizes common shapes ({records:[...]} or {result:[...]}) into a plain list.
It flattens Salesforce responses into a consistent list, simplifying downstream processing and summarization.
3) Time-windowed queries (incremental by default)
Each run dynamically computes a time window, since → until, using the helper _iso_hours_back(Settings.LOOKBACK_HOURS).
Only records updated within that interval are fetched:
This incremental pattern keeps each run fast, quota-safe, and repeatable.
It pairs with the local snapshot mechanism, which remembers the last-seen record IDs and timestamps, so subsequent runs fetch only new or modified records, rather than re-fetching everything again. Together, the time window and snapshot logic ensure the sync is stateful, lightweight, and free from duplicate Slack posts.
4) Field-selective fetchers for efficient, FLS-safe queries
Every query should pull only what you actually use, nothing more.
The agent’s fetchers are intentionally narrow, requesting only the minimum viable set of Salesforce fields necessary for summarization and Slack rendering. This keeps payloads light, avoids unnecessary joins, and ensures compliance with field-level security (FLS).
These fetchers are the data boundary between Salesforce and the rest of the agent. They enforce scope (LIMIT), time (LastModifiedDate), and visibility (selecting only specific fields).
If you ever add a new signal, usage drops or new cases spike; extend these field lists, don’t widen them blindly. That small discipline keeps your agent predictable under governor limits and readable months later.
5) Redaction and delta detection (pre-Slack)
Data safety and signal accuracy are enforced right after the fetch stage. Every record passes through a two-step gate, redaction for privacy and snapshot comparison for change detection.
- PII redaction scrubs emails and phone numbers in Account.Phone, Account.Website, Account.Name, and Opportunity.Name.
It uses regex-based masking via redact_pii() to ensure that no identifiable information leaks into summaries or LLM prompts. - Snapshot diffing tracks A:{Id} and O:{Id} against LastModifiedDate in a local file (default: sf_insights_snapshot.json).
Only newly created or updated records since the last run are surfaced, keeping Slack digests relevant and quiet on unchanged data.
Together, these checks ensure every message that reaches Slack is both compliant and signal-driven, with no PII exposure, no duplicates, and no noise.
6) Extending the agent: adding new signals cleanly
The framework makes it easy to extend your signal surface without touching the core logic. To add a new metric, say, open escalations, churn risks, or product usage drops, follow the same disciplined pattern:
- Add a focused fetcher with its own field list and a WHERE clause scoped by the same incremental window (since_iso, until_iso).
- Use the standard SOQL gateway (soql(conn, Settings.SALESFORCE_IDENTIFIER, query)) so retries and normalization just work.
- Run redaction and snapshot checks before publishing, keeping results safe and idempotent.
- Render using the existing Slack formatter, passing deep links built with SALESFORCE_DOMAIN.
This modularity means you can evolve the insights surface, not the scaffolding. Each new signal becomes a small, composable fetcher that the runtime naturally understands.
With the data layer in place, including resilient SOQL execution, incremental windows, and field-selective fetchers, the final step is orchestration.
The run_customer_360() entry point ties it all together: initialization, validation, fetching, redaction, diffing, summarization, and Slack delivery, encompassing the complete operational loop.
Executing the end-to-end flow with governance and safety
Execution starts at a single entry point: run_customer_360(). It wires everything together: initializes the Scalekit connector, verifies OAuth for Salesforce and Slack, checks API quotas, computes the time window, fetches records, redacts PII, diffs snapshots, summarizes changes, and posts to Slack.
That one function is the operational backbone of the agent.
Connections and OAuth validation guard the runtime
The connector factory (get_connector()) returns a singleton with retrying tool calls.
is_service_connected() gates execution up front and prints a Scalekit reauth link if a connection is missing, avoiding half-configured runs and noisy tracebacks.
Governor limit awareness keeps runners safe
Before querying, the agent calls salesforce_limits_get to check API capacity and logs the remaining quota. This anchors scheduling and batch-size decisions in real, live limits, not assumptions.
Incremental, windowed fetches ensure precision
The agent computes an ISO window (e.g., last 24 hours) and fetches only Accounts and Opportunities updated within that window, ordered by LastModifiedDate. Hard limits and strict filters ensure queries remain predictable within Salesforce governor limits.
Portable SOQL execution handles backend differences
The helper exec_soql() attempts tool variants (salesforce_query_soql → salesforce_soql_execute → {query}) in a safe order, normalizing tenant quirks without branching the logic.
Privacy and idempotency checks run before Slack
Emails and phone numbers are masked using redact_email and redact_phones, and snapshot diffs ensure that only changed records are announced. Together, they guarantee compliance and clean, one-time notifications.
Readable digests, retried delivery
The digest groups Opportunities under their parent Accounts or summarizes them inline when standalone.
Messages are posted through execute_action_with_retry() against slack_send_message, ensuring reliability even in the event of transient Slack errors.
In the opening scenario, renewals were buried deep in Salesforce until someone noticed too late.
Now, the same data is delivered to Slack within minutes, with one digest per run, eliminating noise and lag. What was once hidden in dashboards is now visible in real time, right where teams work.
Generating concise, context-safe insights (rules first, LLM optional)
Summarization begins with structure and intent rather than randomness. Before involving any language model, the agent applies deterministic summarization logic to transform raw Salesforce data into a concise, human-readable insight. Using the built-in summarize_opps() routine inside build_text_fallback, it analyzes Opportunities to count total records, compute Closed-Won revenue, surface the largest deal, and highlight the next upcoming close date. This rule-based foundation ensures summaries are accurate, repeatable, and production-safe, providing clarity even when LLMs are disabled or restricted.
Optional hooks enable LLMs. If you want a higher-level summary, add a simple function in custom_summarizer.py:
Returning a string prepends your custom line to the digest; returning None keeps the deterministic path. The hook is minimal, side-effect-free, and isolated from business logic.
Redaction precedes language generation. Emails and phones are masked before any text hits an LLM or Slack. The same reversible-safe patterns (e.g., a***z@domain.com, masked digits for phones) apply to all outbound text fields, protecting sensitive data even if logs or prompts are inspected.
The digest keeps the signal first. If Accounts change, it groups related Opportunities with deep links; if only Opportunities change, the digest opens with a one-liner summary, then lists deals by stage, amount, and close date.
Formatting emphasizes skimmability:
- Headline: “Customer 360, updated in the last N hours”
- Optional summary: one sentence from summarize_digest or deterministic rules
- Per-account bullets: stage, amount, close date
- Deep links: <https://{domain}/{sObject}/{Id}|Open> wherever users might click
In the opening scenario, renewal insights were buried in dashboards. This flow transforms raw CRM deltas into a crisp, readable digest so when big deals move or close dates shift, the team sees it instantly in Slack, not next week in a report.
Posting structured insights to Slack with deep links
Slack delivery is the final mile of the workflow. The agent posts a single digest message to a target channel using a thin wrapper around the Scalekit Actions API, ensuring retries, backoff, and normalized responses across environments. The post_slack(...) helper in your runtime constructs {channel,text} and delegates execution to execute_action_with_retry(tool="slack_send_message", ...). This keeps Slack-specific logic out of your core code while maintaining consistent observability and resilience.
The digest is rendered through build_text_fallback(...), which generates a compact message that lists Accounts and Opportunities updated in the last window, complete with Salesforce deep links. The same function handles both deterministic summaries and optional custom text from summarize_digest, so the Slack layer only needs to deliver and not interpret content.
Deep links keep the workflow grounded. Each Account and Opportunity is linked directly to Salesforce via:
<{domain}/{sObject}/{Id}|Open>
When Accounts change, related Opportunities appear grouped beneath them; when only Opportunities update, the digest opens with a one-line summary, followed by bullet-style deal lines (Stage, Amount, CloseDate). This structure turns raw deltas into skimmable, actionable context without flooding the channel.
Operational guardrails minimize noise. Each run posts exactly one digest per window after deduping against the snapshot file, ensuring that the same record never appears twice. Long messages are preview-logged safely (no secrets), and retries apply exponential backoff on transient Slack or network errors. Permanent failures are clearly surfaced, preserving reliability without requiring manual babysitting.
In our opening scenario, renewals went unnoticed because updates were trapped inside Salesforce reports. With this Slack integration, the same signals now appear as one crisp, linked digest in-channel, so the team reacts in real-time, without needing dashboards or inbox hunts.
Scheduling, lookback windows, and duplicate-safe automation
Schedules turn the workflow into a habit. The agent is designed to run on a cadence (cron, GitHub Actions, Kubernetes CronJob) and process only records modified within a sliding window, producing one digest per run. Window size and record caps are configurable, so operations stay under governor limits even on busy days.
Lookback windows bound each run. The job computes since_iso/until_iso for the past LOOKBACK_HOURS and queries Accounts and Opportunities where the LastModifiedDate falls within that range, ordered by recency, and limited to MAX_RECORDS. This keeps payloads small and makes each run deterministic.
Governor limits guide throughput. Before querying, the agent fetches salesforce_limits_get and logs the remaining API requests, allowing you to tune the frequency or caps if the organization is tight on quota. This “limits-first” mindset prevents noisy failures and lets ops scale confidently.
Snapshots prevent duplicate chatter. After fetching, the job loads a simple on-disk snapshot (map of A:{Id}/O:{Id} → LastModifiedDate), selects only changed items, posts the digest, and then saves the new snapshot. On retries or reruns, unchanged records won’t be announced again.
Retries are centralized in the connector. Slack posting and Salesforce tool calls are executed via execute_action_with_retry, which includes exponential backoff and safe parameter previews (no secrets are logged). This keeps the scheduler simple, and transient network or rate-limit errors are handled uniformly.
A minimal ops recipe keeps it production-ready.
- Cron: run daily at 09:00 or hourly during business hours; increase frequency for fast-moving pipelines. (Use LOOKBACK_HOURS ≥ run interval.)
- Caps: set MAX_RECORDS to protect Slack noise and SOQL pages during spikes.
- Limits: monitor salesforce_limits_get output to adjust cadence on low quota days.
- Idempotency: rely on the snapshot file to avoid repeat announcements when jobs overlap or re-run.
A short orchestration snippet shows where scheduling meets logic.
Previously, renewal signals were hidden deep within Salesforce dashboards. Now they surface in Slack each morning, clean, deduplicated, and instantly actionable, so teams catch risks in-channel before they turn into surprises.
By this point, each module, from SOQL fetchers to summarization and Slack delivery, is clear on its own. But seeing the entire system in motion reveals why this pattern works so reliably.
The Customer 360 Agent’s runtime isn’t a set of scripts; it’s a governed flow that begins with data extraction and culminates in actionable insights in Slack.
Visualizing the end-to-end workflow
Before we dive into the full runtime, it helps to see the agent in motion. The Customer 360 Insights Agent runs as a clean, observable pipeline, with each step visible from terminal logs to Slack delivery.
In the terminal, you’ll see the agent initialize connectors, check Salesforce API limits, fetch Accounts and Opportunities, redact PII, compute diffs, and summarize updates.
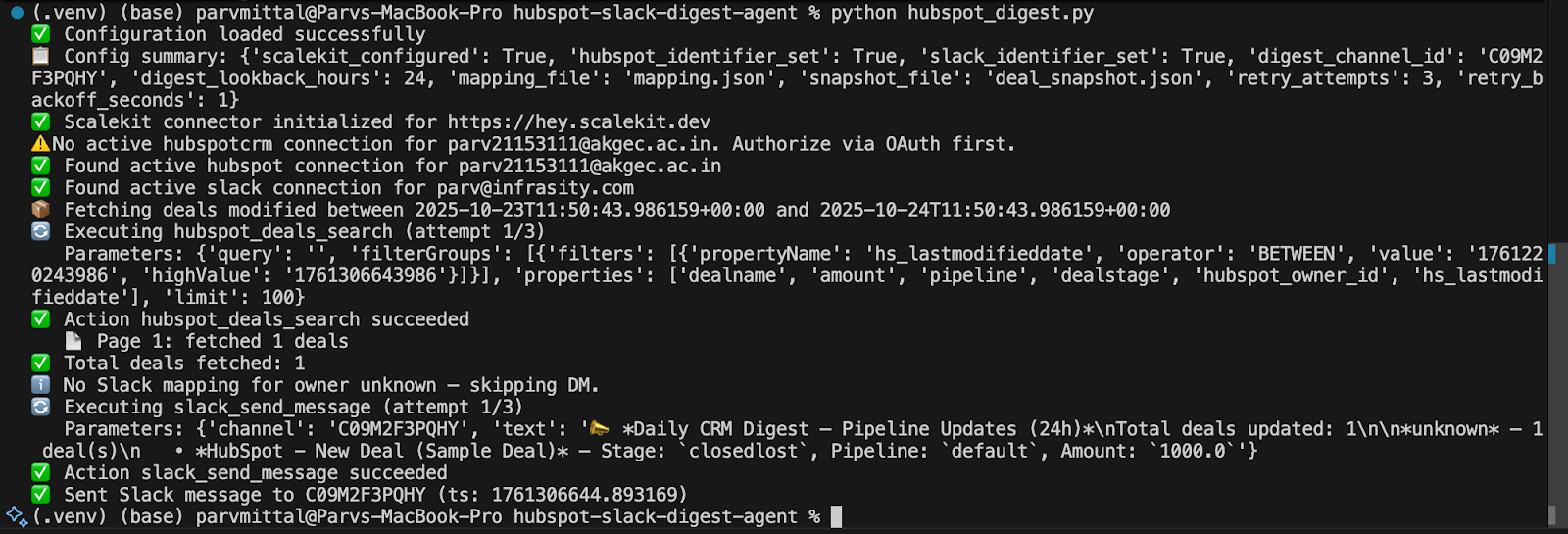
Moments later, the output appears in Slack as a single, concise digest with deep links back to Salesforce, showing precisely what changed.
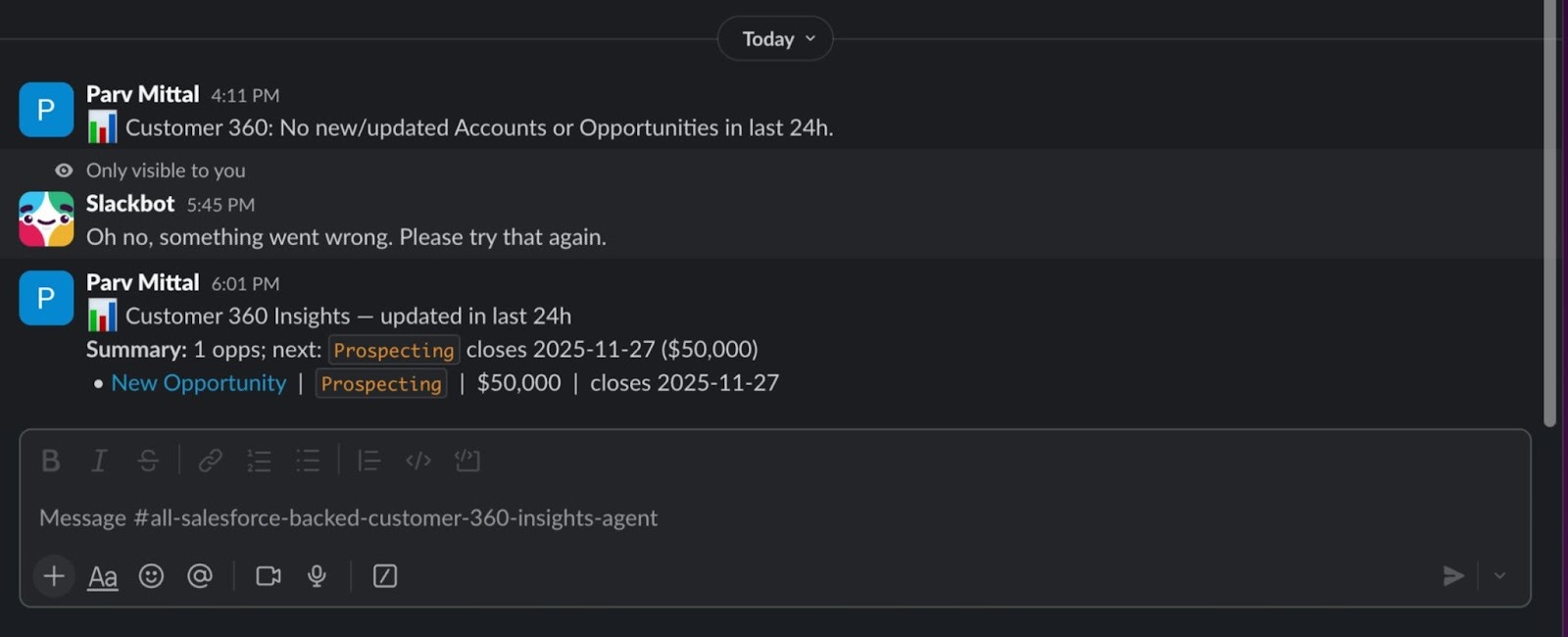
These two views of backend execution and user-facing delivery complete the feedback loop. You can trace every record fetched, redacted, summarized, and posted from log line to Slack message, ensuring observability, compliance, and trust in automation.
End-to-end workflow: From query to Slack
Each module, from SOQL fetchers to summarization and Slack delivery, contributes to a governed, self-healing runtime.
The diagram below maps the complete flow: how Salesforce data moves through Scalekit, gets redacted, summarized, and posted safely into Slack, all under live governor and retry control.

Each step in the flow is both modular and governed, from retries in the connector to snapshot-based deduplication and privacy-safe summarization. The result is an automation loop that’s transparent, auditable, and resilient by design.
With the operational flow complete, the final layer ensures that it stays secure and compliant for every query, post, and snapshot, including all included.
Security, permissions, and compliance: Building trust into the flow
Every automation touching customer data must earn trust. The Customer 360 Insights Agent embeds security from the first query, not as an afterthought. Each layer enforces Salesforce’s access model and privacy expectations while staying performant under governor limits.
Field-Level Security (FLS) enforcement
Before querying, the agent uses Salesforce’s describe metadata endpoint to determine which fields are queryable and accessible to the authenticated user. The final SELECT list filters out restricted fields, ensuring SOQL never returns data users shouldn’t see.
Governor limits as runtime guards
Governor limits aren’t suggestions; they’re ceilings. The run_customer_360() entry point proactively calls salesforce_limits_get and logs the remaining API quota. Each run respects MAX_RECORDS and LOOKBACK_HOURS, scaling gracefully even under high load. These live limit checks prevent silent throttling and failed jobs during periods of high activity.
Redaction before export
No personal identifiers leave Salesforce boundaries. The agent applies a regex-based scrubber to mask email addresses and phone numbers before any data reaches summarization or is sent to Slack. This is enforced both in sf_utils.py (extraction layer) and before LLM summarization in custom_summarizer.py. When REDACT_PII=true, sanitization is automatically applied to all outbound text.
Slack posting under least privilege
Slack integration operates with minimal permissions, specifically the ability to post messages and retrieve basic channel metadata. No reads or DMs are required. Secrets are stored outside of code via environment variables. The connector redacts token previews in logs and retries only safe payloads.
Auditability and observability
Each run logs what was posted, how many records were processed, and surfaces errors as descriptive messages, without leaking data. This makes failures easy to trace in CI or Cron logs while preserving compliance boundaries.
Security isn’t a trade-off against speed; it’s the reason the system can move safely and efficiently. By enforcing permissions, redacting PII, and adhering to governor limits, the agent earns the trust necessary for automation to scale without friction.
Conclusion: From hidden data to actionable insights
The Customer 360 Insights Agent transforms passive Salesforce data into actionable Slack signals. You’ve seen how it:
- Extracts key Accounts and Opportunities safely using SOQL under governor limits.
- Summarizes signals into human-readable updates with optional LLM enrichment.
- Redacts PII and enforces field-level permissions before any data is sent from Salesforce.
- Posts structured digests to Slack, with retries and deep links that close the loop.
- Schedules are clean using lookback windows and snapshots, ensuring no duplicates.
- Operates securely, guided by Salesforce limits, Slack scoping, and full observability.
This automation closes the “visibility gap” that costs teams time and deals. With it, every Slack channel becomes a live window into Salesforce, updated daily, scrubbed for safety, and instantly actionable.
What to explore next
- Extend the summarization step with your own LLM chain for context-aware insights (e.g., summarize changes per Account using GPT-4o-mini).
- Integrate Slack interactivity by adding buttons, such as “Open in Salesforce” or “Mark Reviewed.”
- Pipe the same signals into Teams, email digests, or dashboards via webhooks.
- Explore adjacent topics like "Automating Slack workflows with LangGraph and Scalekit”
FAQs
1. How does Scalekit simplify integration with Salesforce and Slack?
Scalekit unifies authentication, rate-limiting, and retries across tools. You can call both Salesforce and Slack actions through a single connector interface, eliminating the need to manage separate SDKs or OAuth tokens. This keeps your run_customer_360() flow clean and API-version-proof.
2. How does the agent respect Salesforce governor limits?
Before each run, the agent checks salesforce_limits_get to understand the remaining API capacity. Query size, lookback windows, and pagination adapt dynamically, so it never exceeds daily quotas or fails due to throttling.
3. Can I use an LLM for smarter summaries?
Yes, the custom_summarizer.py file exposes a simple hook for LLM integration. You can plug in GPT-4 or any other model to convert structured data into narrative summaries, while maintaining deterministic fallbacks for safety.
4. How is sensitive customer data protected?
All emails, phone numbers, and identifiers are redacted before being sent from Salesforce. The agent enforces field-level permissions (FLS) and logs only sanitized metadata, ensuring PII never reaches Slack or external services.
5. How can teams extend this agent further?
You can add new signal types (such as “High Priority Cases”), route outputs to additional channels (like Teams or email), or schedule runs via CI/CD. Because the code relies on modular connectors and snapshots, these changes require minimal refactoring.






