.png)


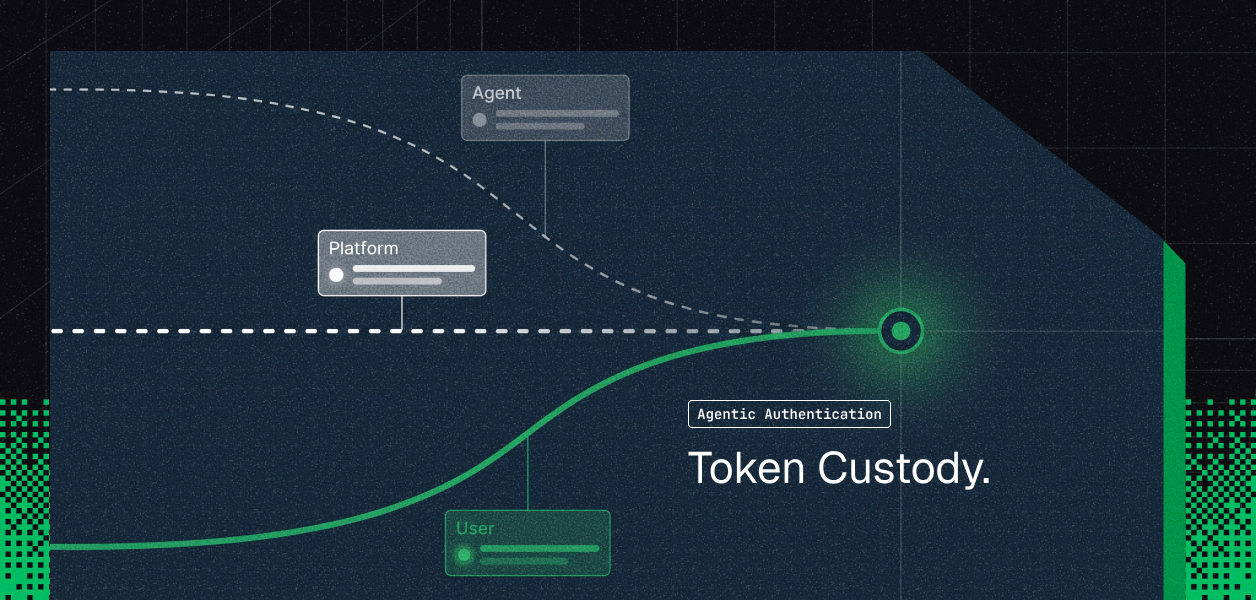
Every tool-calling agent needs the same 5 auth components. They are not optional modules. They are a dependency chain: you cannot properly implement layer N without having correctly built layer N-1.
In a demo, none of this is visible. The demo works with a single access_token hardcoded in an environment variable, a single user, a single provider, no refresh logic, no tenant boundaries, no audit trail.
In production — specifically the moment a second customer organization appears — every skipped layer becomes a live failure.
The sketch below is the full auth stack your tool-calling agent converges on. This post maps each layer: what it requires, what breaks when it's absent, and which pressure event exposes the gap.
The layers are ordered by dependency, not by importance. All five are mandatory in production. The ordering describes which ones you can temporarily defer and which ones, if deferred at the wrong point, create structural rework.
Before the first line of auth code, there is an architectural choice that most agent engineers treat as a developer experience preference. It is not.
When you choose how to connect your agent to external tools, three integration patterns are available:
The direct function calling pattern feels like the correct choice at prototype stage. Low setup cost. Full control. Fits any LLM SDK. All true. The problem is what this choice makes mandatory for everything that follows.
When the agent process owns the access_token and refresh_token, every auth layer in the stack becomes your engineering team's problem to build and maintain:
None of these is a documentation problem. Each is a full engineering surface that scales linearly with the number of providers your agent integrates with.
The MCP server pattern moves credential ownership from the agent process to the MCP server process. The credential problem relocates; it does not disappear. Additionally, MCP introduces a second auth boundary — agent to MCP server — that is frequently left completely unauthenticated in production. The credential ownership post documents the precise failure mode: three concurrent agent threads, one shared refresh_token, Slack token rotation enabled. At 2:47am, all three threads detect an expired access_token simultaneously. All three call the OAuth token endpoint with the same refresh_token. The first thread succeeds; threads two and three receive invalid_grant. They fail silently. The investigation takes four days.
That failure is not a bug. It is the documented behavior of any architecture where the agent process owns the refresh_token, specified in RFC 6749 §6: refresh tokens are single-use.
The vault-backed pattern resolves this structurally. The access_token and refresh_token never exist in agent runtime memory or LLM context. The agent holds an opaque connected_account_id. The vault owns refresh, rotation, revocation detection, and audit attribution as infrastructure primitives.
The execute_tool call above does not contain a credential. The agent never receives one. This is the only pattern where all five subsequent layers can be implemented without custom infrastructure.
Once credential ownership is resolved, the next question is where tokens are stored and what "secure storage" actually means at the implementation level.
Three distinct failure modes appear in production systems that describe their token storage as "secure":
Tokens are encrypted at rest in a shared database table. Encryption key is a single application secret. A misconfigured query — SELECT * FROM connected_accounts WHERE user_id = ? missing an AND org_id = ? clause — returns tokens from a different tenant's ConnectedAccount. The token is encrypted, but it's the wrong tenant's encrypted token, and the agent decrypts and uses it correctly. This is not a data bug. It is a data leak that produces correct-looking behavior.
Correct storage requires separate key material per org, not application-layer encryption with a shared key.
The Authorization: Bearer eyJhbGci... header in an outbound API request appears verbatim in access logs if the HTTP client logs request headers. This is the most common and least-discussed token exposure vector in agent systems. The token is encrypted at rest in the database. It is plaintext in the log aggregator.
Correct storage requires that access_token values never appear in any log path: application logs, HTTP client debug logs, LLM completion logs, or structured telemetry.
An agent that receives a raw access_token as part of its tool call input — even temporarily, even for a single turn — exposes that credential to the full prompt injection attack surface. Not just to adversarial extraction; to any input that instructs the agent to include the token in a response, a summary, or a tool call to a second system.
Correct storage requires that credentials never enter the LLM context at any point in the tool execution path. The agent calls a tool by name with business-logic parameters; credential injection happens inside the connector layer, after the LLM has produced its output and before the API call is made.
Only 37% of organizations enforce purpose binding for AI agent credentials. Storage misconfiguration is the primary mechanism through which agent credentials reach unintended destinations.
The transition from one customer to two is not an incremental change. It is the first time your agent runs against two different organizations' data simultaneously, on two different sets of credentials, where a routing error exposes one organization's data to the other.
The specific failure is structural, not careless. A fintech team wires an AI triage agent across four engineering Slack channels, one per team. Three months into production with a dozen customer orgs, the backend team starts finding issues landing in the frontend repo. Root cause: a shared GitHub access_token with no tenant boundary. Every channel, every customer org, used the same identity to act. (Full pattern analysis here.)
At the tool call level, multi-tenant isolation requires a precise distinction between two concepts that most teams initially conflate:
Connection: The developer's OAuth app credentials for a provider. Configured once, in the Scalekit dashboard, per provider. Contains the client_id and client_secret for your OAuth app registration with GitHub, Salesforce, Slack, etc. One Connection per provider, shared across all your customers.
ConnectedAccount: A specific end user's authorization grant. Created when a user completes the OAuth flow for a provider. Contains that user's access_token, refresh_token, authorized scopes, and token expiry — all encrypted and isolated to that user's org. One ConnectedAccount per user per provider.
The agent must resolve every tool call against a ConnectedAccount, never against a Connection. The Connection is infrastructure. The ConnectedAccount is identity.
The user.scalekit_connected_account_id is the tenant isolation boundary. It is the identifier that binds every tool call to a specific user's authorization event in a specific customer org. Without it, every tool call is potentially cross-tenant.
What tenant isolation requires in the connection config:
Per-tenant isolation guarantees that the right credential is used for the right organization. Scope enforcement guarantees that the right action is authorized for that credential.
These are different problems. A ConnectedAccount with full admin scopes, correctly isolated per tenant, can still allow an agent to perform actions the authorizing user never intended to authorize.
Two distinct categories of agent tool calls require different OAuth flows:
User-delegated actions (Authorization Code Flow, RFC 6749)
The agent acts on behalf of a specific user. The user completed the OAuth flow; the agent inherits exactly that user's permissions — no more, no less. If the user can't write to a repository, the agent can't write to a repository. If the user's Jira access doesn't include PROJ-PRIVATE, the agent's Jira queries return exactly what that user's Jira session would return.
This is the correct model for any action that creates, modifies, or accesses data attributable to a specific user: creating issues, sending emails, updating CRM records, posting Slack messages.
Org-level background actions (Client Credentials Flow, RFC 6749)
The agent runs on org-level credentials. No user in the loop. Correct for syncing records, updating dashboards, running scheduled reports — actions where the operation is systemic and the org is the principal, not a specific employee.
The structural problem: many teams use a service account (Client Credentials or a shared OAuth token with broad scopes) for all agent actions, including actions that should be user-delegated. The consequence is not just an audit failure; it is an active security gap.
GitHub get_repository_secrets is available to senior developers. An agent running on that developer's over-scoped service account can query secrets the task never required. Not because the LLM was instructed to; because "gather context" and "read available data" are reasonable agent behaviors that the absence of scope enforcement turns into privilege escalation. (IAM and agent access control deep dive here.)
Scope enforcement at the tool call boundary requires:
Layers 0 through 3 can all be implemented correctly while this layer destroys your agent's reliability in production. Token lifecycle failures are the most operationally invisible failure class in agent systems because they often do not throw exceptions. They produce incorrect behavior silently, at 2am, on a background workflow that nobody is watching.
Three distinct lifecycle events produce three distinct failure modes:
access_token lifetimes vary by provider: 1 hour for Google, 6 hours for HubSpot, configurable for Slack. The agent runs continuously. At some point, a token expires mid-workflow.
Reactive refresh — waiting for a 401 response, then calling the refresh endpoint — is the approach most teams implement first. It creates a race condition: multiple concurrent agent threads detect the 401 simultaneously, all attempt refresh simultaneously. The first succeeds; the others may receive invalid_grant depending on the provider's token rotation behavior.
Proactive refresh — checking expires_in before each tool call, refreshing if within a configurable window — prevents this. But proactive refresh requires distributed locking: if two threads check simultaneously and both determine a refresh is needed, the race condition reappears. The locking logic must be implemented once, correctly, per deployment environment.
Slack, with token rotation enabled, invalidates the refresh_token on each use. This is correct per RFC 6749 §6. It is also the specific failure mode documented in the credential ownership post: three concurrent threads, one refresh_token, invalid_grant on threads two and three. Silent failure. Four-day investigation.
Provider-specific rotation behavior is not consistently documented. You encounter each variant at production scale, not in the OAuth spec.
A user disconnects their account. An IdP admin revokes an OAuth grant. An employee's Okta account is disabled and the cascade reaches the OAuth grant.
Without event-driven revocation detection, the agent discovers this when the next tool call returns 401 on a token that was valid one minute ago. At that point, the agent is mid-task. The task fails. The agent must surface an error to a workflow that assumed the credential was valid.
With agent webhooks on connected_account.disconnected, the revocation event fires before the next task starts. The orchestration layer can pause the workflow, notify the user for re-authorization, and resume — rather than discovering the problem inside a running task.
Revocation detection via webhooks requires the infrastructure to exist before the first revocation event. You cannot retroactively add event-driven revocation detection to a polling-based architecture without replacing the polling architecture.
The audit trail is the last layer, but it is not independent. It is structurally dependent on every layer beneath it. You cannot have a meaningful audit trail if connected_account_id doesn't exist (Layer 2 gap), if scopes weren't bound at authorization time (Layer 3 gap), or if refresh events aren't captured (Layer 4 gap).
This matters because the audit trail is how enterprise security teams evaluate your agent. The SOC 2 CC6.1 requirement is not "do you have logs." It is: "show me evidence that the credential used to access this specific record was authorized by the specific user whose data was accessed, and that the credential was valid at the time of access."
A shared service account credential cannot satisfy this requirement. A user_id + timestamp log cannot satisfy this requirement. Only a log entry that contains all of the following can:
Required fields in every agent action audit entry:
The compliance standard mapping:
The four event categories every agent audit trail must capture:
The dependency statement is precise: a gap at Layer 2 means connected_account_id doesn't exist in the audit log. The log entry attributes the action to an application, not to a user. The SOC 2 auditor's question — "show me the user who authorized this action" — has no answer.
A gap at Layer 3 means scope_used is absent or is the full scope set rather than the specific scope exercised. The ISO 27001 question — "demonstrate least privilege" — cannot be answered with "the user authorized these 12 scopes and the agent used all of them."
A gap at Layer 4 means refresh events aren't recorded. The GDPR Article 6 question — "was consent still valid at the time of this access" — cannot be answered for actions that occurred after a token refresh, because the refresh itself isn't attributed to a re-authorization event.
For a complete treatment of audit trail structure and compliance mapping, see: Audit Trails for Agent Auth in B2B SaaS.
The total implementation surface for all 5 layers — built correctly, with proper distributed locking, per-provider refresh edge cases, cryptographic tenant isolation, and structured audit logging — is conservatively a year of careful engineering. That estimate comes from the build vs. buy analysis, which also documents the deal-velocity cost: a $400K enterprise deal stalled because the security questionnaire asked about revocation controls and scope governance that the homegrown system wasn't built to answer.
Scalekit's AgentKit implements all 5 layers as infrastructure primitives. Each one maps directly to a component:
The single execute_tool call abstracts every layer:
What this call does before the Salesforce API receives the request:
After the call:
The architecture you build on Scalekit's free tier — 10,000 Connected Accounts at $0/month — is the same architecture that handles enterprise customer security reviews. No rewrites when you add your 50th customer or your first SOC 2 audit. Start at app.scalekit.com.
Yes. The MCP server is now the entity that owns the access_token and refresh_token. All 5 layers still apply; they've relocated to the MCP server process. The agent-to-MCP boundary is a second auth surface that's frequently left unauthenticated in production — 492+ MCP servers were found exposed without authentication in production as of Q1 2026. The outbound boundary (MCP server to downstream API) is almost always Pattern 1 credential ownership — the agent developer's problem — with the MCP server developer as the new owner. See the MCP auth overview for the correct auth topology.
A user_id lookup without an org_id filter. If connected_accounts is queried by user_id alone, and two customers happen to have users with the same internal ID (common with incremental integer PKs or UUID collisions in imported data), the query returns the wrong tenant's tokens. The agent decrypts and uses them correctly. Correct-looking behavior. Wrong tenant's data. This is not detectable by the agent and not detectable by standard application monitoring. It surfaces when a customer reports seeing another customer's records — after the fact.
The moment any action must be attributable to a specific user. SOC 2 CC6.1, GDPR Article 6, and HIPAA all require linking data access to a specific authorized identity. A service account satisfies none of these requirements. Background sync, scheduled reports, and org-level dashboard updates are legitimate Client Credentials use cases. Any action touching a specific user's data — reading their email, updating their CRM record, posting on their behalf — requires a ConnectedAccount scoped to that user. The rule: if the action would require the user's explicit consent in a human-driven workflow, it requires their delegated authorization in an agent workflow.
Technically yes. The migration cost is high and the timeline is almost always underestimated. Token storage, refresh logic, scope enforcement, audit instrumentation, and tenant isolation are all built on top of the credential location decision. Migrating requires: refactoring every tool call to use opaque ConnectedAccount references (touching every integration point in the agent), replacing your custom refresh scheduler with vault-managed proactive refresh, rebuilding your audit log schema to include connection_id and connected_account_id (retroactive audit records cannot be reconstructed), and migrating existing stored tokens into the vault with per-tenant key material. Most teams do this once, under time pressure, before a significant enterprise deal closes. The build vs. buy post documents the full cost structure.
Each connector in AgentKit has provider-specific behavior encoded: Salesforce instance URL resolution per ConnectedAccount (each customer's Salesforce org lives at a different subdomain), HubSpot portal-scoped token binding, Slack workspace-specific token rotation behavior with distributed refresh locking. These are the implementation details you discover one integration at a time when rolling your own — each one a production incident. Scalekit's 150+ prebuilt connectors encode the provider-specific edge cases that don't appear in the OAuth spec.