The Hidden Cost of Building OAuth Internally for AI Agents



Oh, the seductive simplicity of "We'll Build It." Very tempting, right? It starts innocuously – as most expensive decisions do.
Your AI agent needs to read a user's Slack channels and post summaries. You open the Slack OAuth docs, implement the Authorization Code flow in an afternoon, store the access token in your database, and ship. Your demo works flawlessly. Your team is proud. Your CTO says "good call on building that internally – we own it now."
Six months later, the same team is debugging a silent token expiry race condition affecting 12 enterprise tenants. A senior engineer is rewriting the refresh scheduler for the third time. Your SOC 2 auditor is asking why there's no per-tenant token isolation. And a $400K enterprise deal just got stalled because the security questionnaire asked about your revocation controls and OAuth scope governance – questions your homegrown system wasn't designed to answer.
This is more or less the story of virtually every AI SaaS company that chooses to build OAuth internally for AI agents rather than abstracting it behind purpose-built infrastructure.
The problem with OAuth for AI agents that teams don't foresee is that it's a distributed systems problem, a cryptographic key management problem, a compliance problem, and a multi-tenant isolation problem – all at once, all stacked on top of each other, and all evolving as your provider integrations, your MCP server connections, and your enterprise customer requirements evolve.
This Scalekit insight is a precise accounting of what that actually costs: in engineering hours, in security posture, in deal velocity, and in the long-run financial model that founders and VPs of engineering almost never see until it's too late.
What OAuth for AI Agents Actually Means
Before we can cost-model the build path, we need to be exact about what "OAuth for AI agents" encompasses. This is not the same as "adding a login button."
The 3 Flows You Actually Need
Traditional web apps typically use one OAuth flow. AI SaaS systems serving autonomous agents need at minimum three – each with distinct implementation requirements, token lifecycle properties, and security controls.
- Authorization Code Flow (User-Delegated Access)
When your agent acts on behalf of a specific user – reading their Google Drive, posting to their Slack, updating their CRM records – you need the Authorization Code flow with Proof Key for Code Exchange (PKCE). The user grants consent, your backend exchanges the short-lived code for long-lived tokens, and those tokens become the credentials the agent uses autonomously – often for days, weeks, or months after the user's session has ended.
This is where lifecycle complexity explodes: Access tokens expire, refresh tokens rotate, users leave organizations, admins revoke consent; yet the agent should continue to operate in the background and must handle all of these events gracefully, at scale, across tenants. - Client Credentials Flow (Service-Level Access)
When your agent acts as a service identity, i.e., scanning organization-wide repositories, generating aggregate analytics, or running scheduled compliance checks, you need Client Credentials. There's no user redirect. The service authenticates directly and receives a token representing the application's authority.
This sounds simpler, but it introduces its own challenges: scope configuration becomes the only control boundary, and any misconfiguration is a systemic risk rather than a user-scoped one. - Token Exchange Flow (RFC 8693)
When your agent orchestrates across multiple services, i.e., an API gateway calling downstream microservices, an AI orchestrator invoking protected internal APIs – you need Token Exchange. One service exchanges an existing token for another with reduced or modified scopes, preserving least-privilege across the delegation chain.
Most teams don't think about this until they're deep into production and realize their agent's identity is getting silently promoted across internal service boundaries.
What AI Agents Require That Web Apps Don't
SaaS engineering surfers venturing into AI waters, this is for you.
The critical distinction between traditional OAuth and OAuth for AI agents is that agents operate beyond the user session. A standard web app OAuth token lives as long as the browser tab. An AI agent's delegated authority must persist across:
- Background scheduled jobs running while users sleep
- Event-driven workflows triggered by webhooks
- Multi-step orchestrations that span hours or days
- Concurrent execution across thousands of tenants simultaneously
This means what looks like a "simple OAuth redirect" in your demo is actually long-lived credential infrastructure in production. And long-lived credential infrastructure requires token storage architecture, refresh orchestration, revocation handling, tenant isolation, audit logging, and compliance controls – none of which your initial implementation includes.
Committing to "We'll Do OAuth Internally?" Well, Commit to Engineering Hours Too! And Costs, of Course.
Here is what your team actually has to build when they commit to "we'll do OAuth internally" for AI agent workflows.
Phase 1: Initial Implementation (Weeks 1–2)
Week 1: Basic Flow Implementation
- OAuth 2.0 Authorization Code flow implementation
- PKCE (RFC 7636) – now mandatory per OAuth 2.1
- State parameter generation + CSRF validation
- Authorization URL construction per provider
- Callback endpoint and code exchange
- Token parsing and initial persistence
Estimated: 1 senior engineer. 80 hours.
Did you just splutter "Why an entire week?" Well, here's a basic callback handler:
Notice two critical mistakes embedded in what looks like working code: storing tokens in plaintext and potentially logging them on error. Both will come back to haunt you in SOC 2 review.
Week 2: Token Storage Schema
Now you realize you need to model the token properly:
This schema looks reasonable. But it assumes you already have a KMS (AWS KMS, Google Cloud KMS, HashiCorp Vault) with per-tenant key isolation. Setting that up properly is another sprint in itself.
Estimated: 1 senior engineer. 80 hours.
Total (Phase 1): 2 engineers. 160 hours.
Phase 2: Refresh Orchestration (Weeks 3–4)
This is where most teams hit their first serious wall. Access tokens from Slack expire every hour. Google tokens expire every hour. GitHub tokens vary. But refresh tokens also have their own lifecycle rules that vary per provider and are often underdocumented.
The naive approach (that will break in production):
The production approach (what you actually have to build):
This is the minimum viable refresh handler for production multi-tenant agents. It requires: Redis (or equivalent), per-tenant KMS encryption/decryption, an admin notification system, a requires_reauth state machine, and careful distributed lock TTL tuning.
Estimated Phase 2: 2 engineers × 1 week = 160 hours
Phase 3: Multi-Tenant Isolation Hardening (Week 4)
You now have to audit every single path where a token is read, refreshed, or used to ensure that tenant context is never assumed – only verified.
For each integration: audit the token lookup. Audit the cache layer (Redis keys must include tenantId). Audit the background job scheduler (jobs must carry tenant context). Audit the webhook handler (provider webhooks include enough context to derive tenant). Audit the error logs (scrub tokens from stack traces).
Estimated Phase 3: 1 engineer × 1 week = 80 hours
Phase 4: Scope Governance, Revocation, and Offboarding (Weeks 5–6)
Scope governance means building internal tooling to:
- Log what scopes were granted at consent time
- Alert when agents attempt actions outside their approved scope bundle
- Review scope usage across providers periodically
- Enforce versioned scope bundles as provider APIs evolve
Revocation means handling:
- User-initiated revocation (via provider settings)
- Admin-initiated revocation (via your SaaS admin panel)
- Automatic revocation on user offboarding (SCIM deprovisioning)
- Webhook-based revocation events from providers
Offboarding means a user leaving an organization must cleanly terminate all their delegated agent access without affecting other users in the same tenant.
Estimated Phase 4: 1–2 engineers × 1–2 weeks = 80–160 hours
Phase 5: Observability, Audit Logs, and Operational Tooling (Weeks 7–8)
Enterprise customers and compliance audits will ask:
- Which user authorized this agent action?
- Which token was used for this API call?
- What scopes were in effect at the time?
- When was this token last refreshed?
- Has this token ever been used outside its tenant context?
Building audit-grade logs for OAuth lifecycle events – authorization grants, token refreshes, scope validations, revocations – is a non-trivial operational engineering problem.
Estimated Phase 5: 1 engineer × 2 weeks = 160 hours
Total Engineering Time Summary
At a fully-loaded senior engineer cost of $100–150/hour (including benefits, overhead, and opportunity cost), this is a $90K–$110K investment in infrastructure that generates zero direct revenue and will need to be maintained indefinitely (as it will accrue technical debt.)
And this estimate assumes everything goes right, the first time. Well, if you've been in engineering for a while, you know "It won't."
Where OAuth Gets Truly Vicious
The hours above are for the normal path. The real cost of build vs buy OAuth AI lives in the edge cases – the scenarios that don't exist in demos, that appear in production at 3 AM, and that your initial architecture wasn't designed to handle.
1. Refresh Token Inactivity Expiry
Every major provider has different rules about refresh token expiry:
Your background refresh scheduler runs every night. But what about an enterprise tenant that only uses the feature quarterly? That refresh token quietly expired two months ago. The next time the agent runs, it silently fails – and your scheduler marks the job as "completed" because the error handling doesn't distinguish refresh_failed_token_revoked from api_temporarily_unavailable.
Building proper detection and re-consent workflows for every provider-specific expiry pattern is typically a two-week engineering project that no one budgets for upfront.
2. Concurrent Refresh Race Conditions at Scale
Imagine you have 1,000 enterprise tenants, each with a 1-hour token expiry from Slack. Your background scheduler runs every hour. If your scheduler doesn't implement per-token distributed locking, and multiple worker processes start simultaneously, you can end up with:
- Worker A fetches token for tenant X, sees it's expired
- Worker B fetches token for tenant X, sees it's expired
- Worker A calls Slack's refresh endpoint, gets a new access + refresh token
- Worker B calls Slack's refresh endpoint using the old (now-invalidated) refresh token
- Slack returns an error – but now the refresh token Worker A received is also at risk because Worker B's request may have invalidated it in some provider implementations
Yes, a theoretical scenario, but very possible in production, and may have been a nightmare to multiple well-funded AI SaaS teams. Why else do you think that even the giants like OpenAI and Anthropic outsource Auth?
Anyway, the fix to concurrent refresh race conditions requires distributed locking with careful TTL management and retry semantics – adding another layer of infrastructure dependency (Redis, Memcached, or a database-backed advisory lock).
3. Provider API Rate Limits During Token Operations
When a Slack workspace admin revokes your app's access and then re-authorizes it the same day, your callback handler may hit Slack's rate limits on the token exchange endpoint during a high-traffic period. Your retry logic (if you have any) needs to implement exponential backoff – but the OAuth flow has a time-bounded code exchange window (typically 10 minutes). If your retry loop expires the code, the user sees a generic error and has to start over.
This is one of the most common sources of user-reported OAuth failures that are genuinely hard to debug.
4. Redirect URI Validation Failures in Multi-Environment Setups
Enterprise customers often require your app to be deployed in their VPC or on custom subdomains. Slack, GitHub, and Google require pre-registered redirect URIs. When a customer wants their own subdomain (ai-agent.enterprise-corp.com), you need to register new redirect URIs for each OAuth app per environment. If your OAuth app registration is centralized but your redirect URIs aren't parameterized correctly, you'll start seeing redirect_uri_mismatch errors that are extremely difficult to trace without good audit logging.
5. Token Migration Across Key Rotation Events
Your security team mandates quarterly KMS key rotation. Now you need to decrypt every token in your database (with the old key) and re-encrypt it (with the new key) – atomically, without downtime, across potentially millions of rows. If this migration fails partway through, you have a subset of tokens that can no longer be decrypted, and a subset that can. Your background jobs will start failing silently for affected tenants. Recovery requires manual intervention and potentially re-authorization flows for every affected user.
6. The MCP-Layer OAuth Complexity
If your AI agents connect to external services via MCP (Model Context Protocol) servers, the OAuth complexity compounds. Each MCP server requires its own OAuth 2.0 authorization flow, often on top of the provider's existing OAuth. As noted in the MCP spec, you must also implement:
- Dynamic Client Registration (RFC 7591): MCP clients must be able to programmatically register themselves with authorization servers they've never seen before – without manual configuration.
- OAuth 2.0 Protected Resource Metadata (RFC 8414 + RFC 9728): MCP servers advertise their authorization server location via .well-known/oauth-authorization-server. Clients must fetch and parse this before initiating any auth flow.
- PKCE (RFC 7636): Mandatory per OAuth 2.1 draft, which MCP spec tracks.
The practical consequence: you're not building one OAuth client. You're building a general-purpose OAuth infrastructure layer that can discover, register with, and maintain long-lived delegated access to arbitrary OAuth-protected MCP servers – with per-tenant token isolation across all of them.
This is a qualitatively different engineering problem from "implementing a Slack OAuth flow."
The Spec Evolution Problem
The MCP authentication specification has already gone through multiple major revisions in 2025 alone (March → June → November). Each revision brought new capabilities and new implementation requirements. Teams that built against early spec versions found themselves doing significant refactoring work to maintain compatibility. As one industry observer put it: "Engineering teams that built against the March spec found themselves refactoring for June."
When you build OAuth infrastructure internally, you own the obligation to track spec evolution and maintain compatibility. When you buy, that tracking becomes someone else's full-time job.
The Permanent Engineering Tax: Some Call It "Technical Debt," Some Call It "Maintenance," We Call It "Unnecessary Pain"
Every honest discussion of build vs buy OAuth AI must confront this: OAuth infrastructure is not a project. It's a permanent operational responsibility.
Provider API Changes
Major OAuth providers change their token endpoint behavior, refresh token policies, scope definitions, and webhook formats – with varying levels of advance notice:
- Google deprecated several OAuth scopes in 2024 and required app re-verification
- Slack modified its token rotation behavior in the v2 OAuth migration
- GitHub introduced fine-grained personal access tokens that require different scope modeling
- Microsoft changed its refresh token lifetime defaults in Azure AD B2C
Every one of these changes requires your team to: detect the change (often from a provider changelog email or a burst of production errors), understand the impact, implement the fix, test across tenants, and deploy – usually on a tight timeline to avoid service disruption.
Security Vulnerability Patching
OAuth security vulnerabilities are discovered and disclosed regularly. The IETF published RFC 9700 in January 2025 as a major update to OAuth 2.0 security best practices, adding new requirements around redirect URI validation, token binding, and PKCE enforcement. Additional updates to the Security Best Current Practice were published later in 2025 addressing new threats.
When you own your OAuth infrastructure, you must track these publications, assess their impact on your implementation, and ship fixes – often under time pressure when the vulnerability is actively being exploited in the wild.
The Rotating Cast of Provider-Specific Quirks
Each provider you integrate behaves differently in ways that are not well-documented:
Your team will discover every one of these quirks through production incidents. Each discovery costs debugging time, post-mortem time, and fix-and-deploy time.
Ongoing Compliance Updates
SOC 2, ISO 27001, HIPAA, and GDPR all have ongoing audit requirements that touch your OAuth implementation:
- SOC 2 Type II: Continuous evidence of encryption at rest, access controls, and audit logging – all of which intersect with your token storage layer
- HIPAA: PHI-adjacent API calls must have full audit trails with user-level attribution (which requires your OAuth tokens to carry identity claims)
- GDPR: Right to deletion means you must be able to revoke tokens and purge associated data atomically on user deletion request
Each compliance renewal cycle will surface new questions about your OAuth implementation, requiring engineering time to answer, remediate, and document.
"We'll Build It" Means Invisible Drag on Every Enterprise Deal; Because You Can't Ignore Compliance
Here's a number that doesn't show up in most build vs buy analyses: 41% of businesses without a continuous compliance program experience significant slowdowns in their enterprise sales cycle.
Your OAuth implementation is directly in the critical path of your SOC 2 audit. And every enterprise security questionnaire will probe it explicitly.
What Auditors Actually Ask About OAuth
On token storage:
- Where are OAuth tokens stored?
- Are they encrypted at rest? What algorithm? What key management system?
- Are encryption keys rotated? How frequently?
- Are keys isolated per customer/tenant?
- Are tokens ever written to logs?
On token lifecycle:
- What is your access token expiry policy?
- How do you handle refresh token rotation?
- What happens when a refresh token expires or is revoked?
- How quickly can you revoke access for a specific user?
On tenant isolation:
- How do you prevent cross-tenant token access?
- What controls exist at the database layer?
- At the application layer?
- In your background job infrastructure?
On audit trails:
- Is every API call made on behalf of a user logged with their identity?
- Are those logs immutable?
- For how long are they retained?
- Can you produce logs for a specific user's actions in a specific time range?
If you built OAuth in-house, and you didn't build it with SOC 2 in mind from day one, you will be answering "we're working on that" to several of these questions. And "we're working on that" extends your deal cycle by weeks to months.
The Re-Verification Trap
Several OAuth providers (notably Google and Meta) require app re-verification when you modify your requested scopes or expand the categories of data your application accesses. This verification process:
- Can take weeks to complete
- Requires explicit justification for each scope
- May require a privacy policy update
- Sometimes requires a security assessment by the provider
If your scope model evolves because a customer asks for a new integration feature, you may need to halt that feature until re-verification completes. This is a business risk that is eliminated when your OAuth infrastructure abstracts scope management behind versioned, pre-approved bundles.
Cross-Border Data Residency
Enterprise customers in the EU, Germany, Japan, and Australia often require that OAuth tokens and associated metadata be stored in specific geographic regions. If your token storage infrastructure is centralized, you may need to build geo-partitioned storage specifically for OAuth tokens – a significant infrastructure investment that has nothing to do with your core product.
The Security Questionnaire Problem
Modern enterprise sales cycles include security questionnaires – typically 200–400 questions administered through platforms like OneTrust, Whistic, or SecurityScorecard. The authentication and authorization section routinely includes questions that map directly to OAuth implementation quality:
- Does your system support per-user token revocation without affecting other users?
- Can your system produce an audit log of all actions taken by AI agents on behalf of our users?How are OAuth tokens encrypted at rest?
- What is your key rotation policy?
- How do you enforce least-privilege scope boundaries for AI agents operating in our environment?
- Can we revoke agent access for a specific employee without disrupting the integration for other employees?
API key-based or poorly architected OAuth systems fail every one of these questions. And unlike a product roadmap question ("will you have SSO by Q3?"), security architecture questions rarely get a "promise to build" pass.
Scalekit's Approach to This Problem
Scalekit's Agent Auth is built explicitly to answer these enterprise security questions from day one. The connection and connected account model means:
- Every delegated grant is tied to a specific user identity, tenant, and approved scope bundle
- Revocation operates at the grant level – revoke one user's access without affecting others
- Audit logs are tenant-aware and capture every token resolution and API call
- Tenant isolation is enforced cryptographically, not just at the application layer
When a security reviewer asks "can you demonstrate per-user revocation?", the answer is a one-click operation in the Scalekit dashboard – not a two-sprint engineering project.
Long-Term Cost Model
Let's be honest about 3-year cost contributors for the build path vs. the buy path for a mid-stage AI SaaS company with 50–500 enterprise tenants and 5–10 provider integrations.
Year 1: Build Costs
- Initial engineering
- Security hardening + compliance prep
- KMS infrastructure setup
- Redis for distributed locking
- Incident response (production bugs)
Year 2: Maintenance Costs
- Ongoing maintenance (bug fixes, edge cases)
- Provider API change responses
- Security patch implementation
- SOC 2 Type II prep related to OAuth
- Scope governance tooling
- Adding new provider integrations
- Infrastructure
Year 3: Scaling Costs
- Multi-region token storage (EU customer)
- MCP auth layer (agents via MCP servers)
- Enterprise audit log enhancements
- Ongoing maintenance
- Provider changes + security patches
- Infrastructure scaling
Three-Year Cost Estimates: ~$200,000–$250,000
And this doesn't include:
- Opportunity cost: 2–3 senior engineers spending 20–30% of their time on auth infrastructure instead of core product
- Lost deal velocity: Deals delayed or lost because OAuth security review failed
- Incident cost: Customer-impacting token failures and the post-mortem engineering work they generate
- Talent risk: Key engineers who understand your homegrown OAuth system leaving the company
The Buy Alternative
Scalekit starts free and scales with your usage. Even at a generous estimate of $2,000–5,000/month at 100+ enterprise tenants, the three-year buy cost is:
The financial case for buying is straightforward. But the real argument isn't even the cost savings – it's the engineering focus savings. Every hour your senior engineers spend on OAuth infrastructure is an hour not spent on your core AI product.
When Building Makes Sense
This is an honest analysis, so we have to answer this: are there legitimate reasons to build OAuth internally for AI agents? Yes. But they are narrow.
OAuth Is Your Core Differentiator
If you are building an identity platform – if OAuth infrastructure is the product you're selling – then building is not just justified, it's required. Your investment in deep OAuth expertise, protocol-level compliance, and infrastructure resilience is what customers are buying.
This applies to companies like Okta, AWS Cognito, and yes, Scalekit itself. These products/companies exist specifically because OAuth infrastructure is sufficiently complex to justify dedicated engineering investment.
If you are an AI SaaS company – if your product creates value through AI-powered workflows, agent automation, or intelligent integrations – OAuth is infrastructure, not product. The distinction matters enormously.
Deep Regulatory Requirements
Regulated industries (defense, banking, healthcare in some jurisdictions) may have requirements that disqualify third-party OAuth infrastructure:
- Air-gapped deployment: The authorization server must run entirely within the customer's network boundary
- FIPS 140-2 compliance: Cryptographic operations must use FIPS-validated modules
- FedRAMP authorization: Government customers may require FedRAMP-authorized infrastructure throughout
In these cases, building (or using open-source self-hosted options like Keycloak) is the only viable path. But even here, the question is "build the business logic" vs. "build the compliance-validated infrastructure from scratch." Most regulated deployments use a certified authorization server framework rather than implementing RFC 6749 from the ground up.
Highly Idiosyncratic Protocol Extensions
Some enterprise integrations require proprietary extensions to standard OAuth flows – custom assertion grant types, non-standard token formats, or provider-specific authentication extensions that no commercial platform supports. If your core integration depth depends on these extensions, building the specific layer that handles them makes sense.
The key question is: Are you building a custom layer on top of standard OAuth infrastructure, or are you rebuilding the standard infrastructure from scratch? The former is reasonable. The latter is almost never justified.
Why Infrastructure Abstraction Wins
The fundamental argument for infrastructure abstraction isn't cost. It's complexity boundary management.
Every system has a finite capacity for complexity. The teams that build the most successful AI SaaS products aren't the ones that handle the most complexity – they're the ones that most aggressively push non-core complexity outside their boundary.
OAuth lifecycle management for multi-tenant AI agents is not core complexity for an AI SaaS product. It is infrastructure complexity that your product depends on, the same way it depends on PostgreSQL, Redis, or your cloud provider's object storage. You don't build a database engine. You don't build a CDN. You configure and operate them.
What Abstraction Actually Looks Like in Practice

With Scalekit's Agent Auth, the OAuth lifecycle collapses to three abstractions:
Connection: Defines the provider integration boundary (Slack, GitHub, Google Drive, Salesforce). Configure it once – client credentials, allowed scope bundle, redirect configuration.
Connected Account: Represents an authenticated identity under a connection. Created when a user completes the OAuth consent flow. Carries an internal identifier that your agent uses instead of raw tokens.
Action Execution: Your agent calls execute_tool() with a connected account identifier. Scalekit resolves the identifier to the encrypted token, validates expiry, refreshes if needed, calls the provider API, and returns structured output.
Your agent never sees a token. Never manages expiry. Never implements refresh. Never handles tenant isolation. Never deals with key rotation. All of that is inside the abstraction layer.
Compare this to the production implementation your team would build:
This is the same operation. But the homegrown version owns the distributed lock, the KMS decryption, the refresh logic, the error classification, the reauth state machine, and the Slack-specific error handling. Each of those is a failure mode. Each is a maintenance obligation. Each adds latency. And there are 8 more provider integrations with their own quirks.
The Scalekit Connection Model in Production
For teams already operating in production, Scalekit's connection and connected account model maps cleanly onto existing architecture patterns:
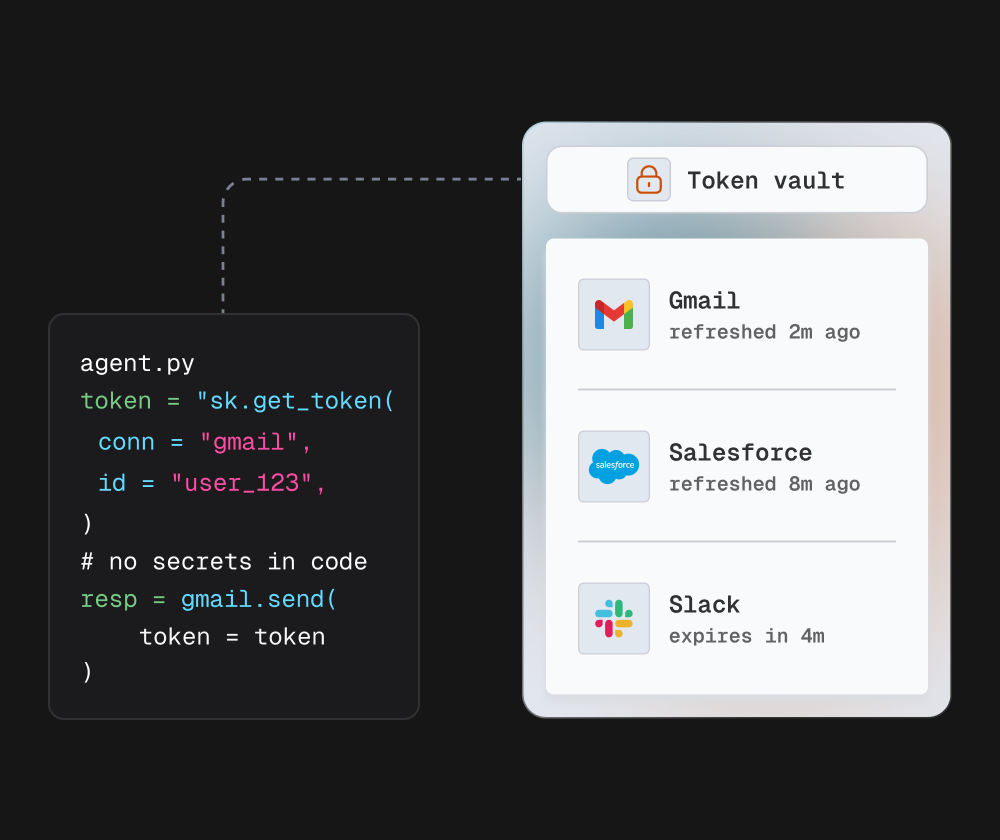
Your agent runtime knows nothing about tokens. Scalekit handles everything between "I need to call Slack as user_123" and "here is the result."
MCP Auth: The Next Layer of Complexity
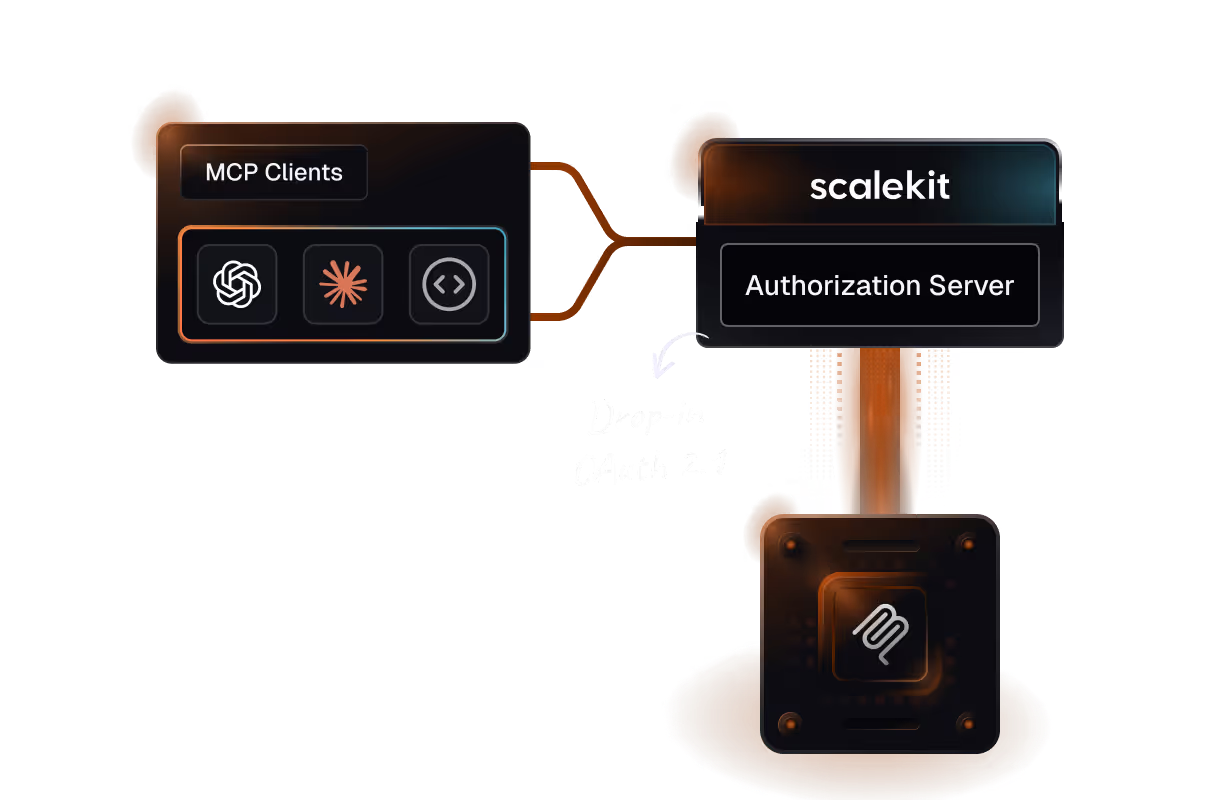
If your agents are or will be connecting through MCP servers, the abstraction argument becomes even stronger. Scalekit's MCP Auth provides:
- Drop-in OAuth for remote MCP servers
- Dynamic Client Registration (RFC 7591) compliance
- OAuth 2.0 Protected Resource Metadata (RFC 8414 + RFC 9728) support
- PKCE enforcement per OAuth 2.1 draft
- Scoped, short-lived tokens designed specifically for LLM-based agents
The alternative – building MCP auth compliance from scratch – means implementing multiple IETF RFCs, tracking an evolving specification, and building the discovery, registration, and token exchange flows that make arbitrary MCP server connections work securely.
Scalekit's product is already SOC 2 Type II compliant and tracking the MCP auth spec in real time. When the spec evolves (and it will), Scalekit updates the platform. Your agents keep working.
The OAuth Infrastructure Decision Framework
For technical founders and engineering leaders making this decision today, here is an actionable evaluation framework:
The 3 Critical Questions
Q1: What is your engineering team's OAuth/identity expertise depth?
Be honest. Most generalist engineering teams have written an OAuth flow but haven't implemented production-grade token storage with per-tenant KMS key isolation, distributed refresh locking, or provider-specific quirk handling at scale. If you don't have 2+ engineers who can enumerate the edge cases in section 4 from memory, you're going to discover them in production.
Q2: What is the opportunity cost of diverting engineering capacity to auth infrastructure?
Calculate the number of product features, AI capability improvements, or customer integrations that 6–12 months of auth infrastructure work would displace. For most AI SaaS teams in growth stages, that opportunity cost is an existential question.
Q3: When is your first enterprise customer security review?
If it's in the next 6 months, you don't have time to build. Enterprise security reviews take 2–4 weeks and require production-quality OAuth infrastructure to pass. Building from scratch and reaching audit-ready quality in under 6 months is possible but requires dedicating disproportionate engineering capacity to it.
The Build vs. Buy Matrix
Conclusion: OAuth Is Infrastructure, Not a Feature
The most important reframe for founders and engineering leaders making the build vs buy OAuth AI decision is this: OAuth lifecycle management for AI agents is infrastructure, not a feature.
You don't build your own PostgreSQL. You don't build your own S3. You don't build your own CDN. Not because these things are easy – they're extraordinarily complex – but because the complexity is well-understood, has been commoditized, and building it from scratch would not produce a better result for your customers than using the production-hardened version that specialists maintain.
OAuth lifecycle management for AI agents is at exactly the same inflection point. The complexity is well-understood (this blog has tried to surface it clearly). The failure modes are documented. The maintenance burden is permanent. The compliance surface is material. The security review impact is measurable. And the cost model is unfavorable for the vast majority of companies.
What Scalekit has built is the production-hardened version: the auth stack purpose-built for AI applications, with the connection/connected account abstraction that keeps your agents focused on their actual job – executing intelligent workflows on behalf of users – rather than managing credential infrastructure.
The companies that ship the best AI agents aren't the ones that master OAuth internals. They're the ones that master what to build vs. what to abstract – and execute on that distinction with discipline every sprint.
OAuth is infrastructure. Treat it like infrastructure. Abstract it, operate it, and then go build the AI product that actually creates value for your customers.
Quick Reference: Key Resources
- OAuth for AI Agents: Production Architecture Guide
- OAuth vs API Keys for AI Agents
- Secure Token Management for AI Agents at Scale
- MCP Authentication & Authorization: Build vs. Buy Roadmap
- Scalekit Agent Auth
- Scalekit MCP Auth
- RFC 6749
- RFC 8693
- RFC 9449
- RFC 9700
Note: All cost estimates are approximations based on industry benchmarks and should be validated against your specific team composition and market rates.






