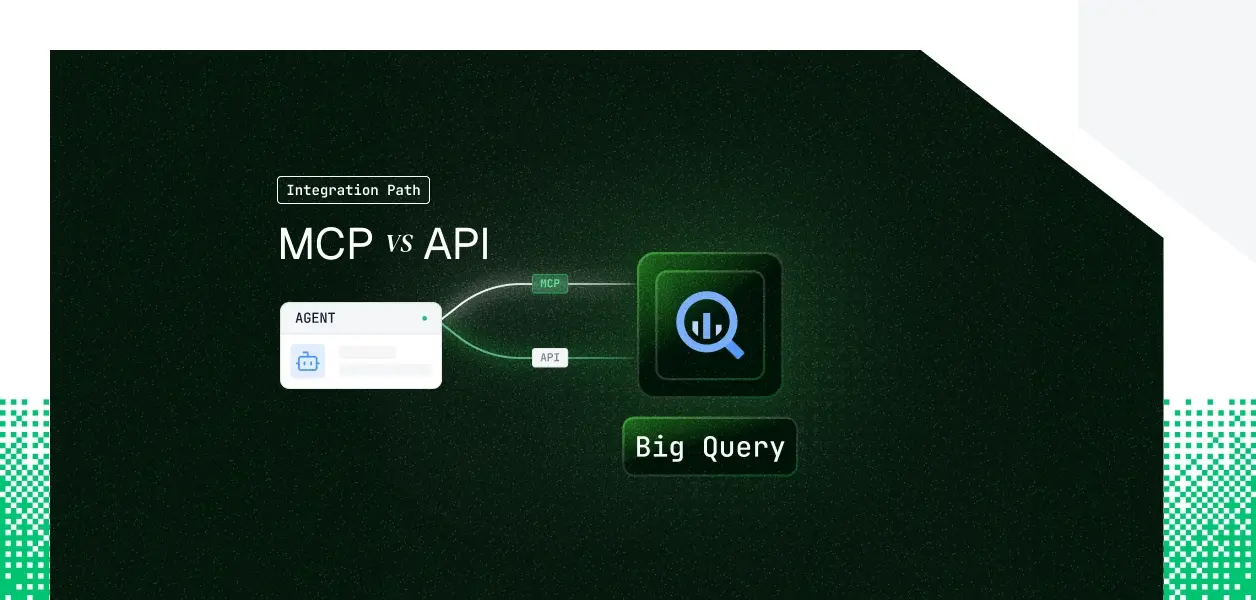
Google BigQuery MCP vs API for AI Agents


TL;DR
- Google BigQuery MCP and the BigQuery API have overlapping but not identical coverage. The managed MCP server handles dataset discovery, schema inspection, and SQL, but it caps query runtime at three minutes and results at 3,000 rows by default, and it does not expose the Storage Write API, the Storage Read API, or bulk load jobs.
- The common "MCP is OAuth-user-only, so it cannot run headless" claim is false for BigQuery. The MCP server authenticates with OAuth 2.0 over IAM and accepts all Google Cloud identities, including service accounts and agent identities. It rejects only API keys. The real ceiling is capability and result size, not auth.
- The BigQuery API adds OAuth, service account JWT Bearer (RFC 7523), Application Default Credentials, and Workload Identity Federation, plus the full Storage Write, Storage Read, load, and admin surfaces.
- For multi-tenant B2B agents, neither path stores, rotates, or revokes the per-tenant credential for you. That is an infrastructure problem regardless of which path you choose.
- Scalekit's Google BigQuery connector handles the OAuth flow, token vault, and rotation for both paths, so the MCP vs API decision does not change your auth infrastructure.
Your analytics agent needs to read and write Google BigQuery. It needs to discover datasets, inspect schemas, run SQL, and hand results back to a model. BigQuery now ships two paths: a fully managed remote MCP server at https://bigquery.googleapis.com/mcp and the REST and Storage APIs your pipelines have called for years.
They cover overlapping but not identical ground, and the obvious assumption (that the MCP server is the lightweight, auth-limited option) turns out to be wrong in an important way. Here is how to pick.
What's Google BigQuery MCP
The BigQuery remote MCP server is a Google-managed endpoint at https://bigquery.googleapis.com/mcp, enabled when you enable the BigQuery API and live in preview as of January 2026. Google hosts, scales, and patches it. Authentication uses OAuth 2.0 with Identity and Access Management; all Google Cloud identities are supported and API keys are not accepted. The server exposes six tools: list_dataset_ids, get_dataset_info, list_table_ids, get_table_info, execute_sql_readonly (SELECT only), and execute_sql (the one non-read-only tool, which can run DML and DDL).
Official docs: Use the BigQuery MCP server
What's Google BigQuery API
The BigQuery API is a versioned REST surface at https://bigquery.googleapis.com/bigquery/v2/, plus the gRPC Storage Write and Storage Read APIs for high-throughput ingestion and parallel reads. It authenticates any Google Cloud identity through OAuth, service account JWT Bearer (RFC 7523), Application Default Credentials, gcloud credentials, or Workload Identity Federation. Endpoint coverage is complete: every action the MCP server exposes is reachable here, plus a large surface the MCP server does not touch.
Official docs: BigQuery REST API reference
What your agent can actually do with MCP and/or API
The MCP server covers the conversational analytics loop well: list datasets, read schemas, generate SQL, run it, interpret results. The gaps appear when an agent needs volume, ingestion, or org-level control.
Where the MCP ceiling sits
The most consequential limit is result size. The MCP tools cap returns at 3,000 rows and cancel queries that run past three minutes by default. An agent summarizing a metric is fine; an agent that needs to pull a large slice of rows into its own logic is not. That work belongs to the Storage Read API or to query jobs that write to a destination table.
The second limit is ingestion. There is no Storage Write API tool, no load-job tool, and no legacy streaming insert. If your agent writes high volumes into BigQuery, that path is API-only, and it is architectural, not a tool that ships next month.
The auth path each one puts you on
This is where BigQuery breaks the usual MCP pattern. Most hosted MCP servers are OAuth-user-only and cannot run without a browser.
BigQuery is different: its MCP server authenticates with OAuth 2.0 over IAM and accepts all Google Cloud identities, including service accounts and agent identities. A headless agent can authenticate to the MCP server with a service account; only API keys are rejected.
Why this changes the decision
Because both paths authenticate service accounts, the headless question does not decide it for BigQuery the way it does for Notion or Salesforce. The decision turns on capability: result size, query runtime, ingestion, and admin surface. The multi-tenant credential question, covered below, applies to both paths equally.
What you own in production
On the MCP path, Google owns hosting, scaling, and tool schemas. You own per-tenant credential storage, refresh, and revocation, plus cost control: every execute_sql call runs a real query and is billed on bytes scanned, and a curious agent on broad questions can run up charges. Queries carry the label goog-mcp-server: true, and IAM deny policies can block the read-write execute_sql tool.
On the API path, you own all of the above plus endpoint selection, retries, pagination, and version pinning. The MCP server has no separate quota; both paths consume the same underlying BigQuery API quotas. For deterministic pipelines where an unplanned schema change is an incident, the explicitly versioned REST API is the more predictable dependency.
When to use MCP, when to use the API
Use Google BigQuery MCP when:
- Your agent is interactive and analytics-facing: a user asks questions in natural language through Claude, Cursor, or Gemini CLI, and the agent discovers schemas and runs read queries.
- Result sets are modest and queries finish inside the processing cap.
- You want Google to enforce IAM, audit logging, and optional Model Armor with zero adapter code.
- You are validating a data-agent concept quickly.
Use the Google BigQuery API directly when:
- Result sets exceed the MCP row cap, or queries run longer than the processing cap.
- You need the Storage Write API for ingestion, the Storage Read API for parallel reads, or bulk load jobs.
- You manage org configuration: Data Transfer Service, reservations, BigLake, or the Connection API.
- You are running a deterministic pipeline and need to pin API versions.
The credential problem that exists on both paths
Both paths hand you a credential, not a credential system
Whether your agent authenticates to the MCP server or the API, a multi-tenant B2B agent ends up with one credential per customer. Forty customers across eight GCP projects means many credentials, each with its own lifecycle. Neither path gives you a vault, rotation logic, or a revocation flow; those have to be built separately.
Why this bites with BigQuery specifically
A service account key shared by a customer becomes a long-lived secret you must store, rotate, and revoke. An OAuth grant can be revoked by the user inside Google at any time, and your agent has no built-in way to learn that until the next call fails. Either way, the token must be encrypted at rest, isolated per tenant, and revocable on offboarding. This is precisely the token vault problem that production agents face across every connector.
Where Scalekit fits
Scalekit's Google BigQuery connector handles the OAuth flow, token storage, and rotation for both paths, so the MCP vs API decision does not change your auth infrastructure. The connector ships in two forms: Google BigQuery for user-delegated OAuth and BigQuery (Service Account) for org-level headless access.
Building a BigQuery agent with Scalekit
Agent Auth and the Token Vault
Scalekit Agent Auth resolves the per-user credential on every tool call. The token lives in an AES-256 token vault, namespaced per tenant, and is fetched server-side at request time in roughly 40 milliseconds. It never enters your agent runtime or the LLM context.
What the user cannot do in BigQuery, the agent cannot do: every query runs with the authorizing user's IAM roles, so column-level security and row-level access policies apply unchanged. This is how access control for multi-tenant AI agents should work in practice.
The connector tools your analytics agent reaches for
The Scalekit Google BigQuery connector exposes a scoped tool set the agent calls through execute_tool. Tool names and parameters are taken from the connector page, not assumed.
Scoping the tool surface before execution
The agent does not load a flat catalog of every BigQuery tool. It loads the tools the current user's connected account is authorized to call, scoped further by an explicit tool-name filter. The sequence is discovery, then scope, then execution.
The connectionNames value passed below must match the connection name configured in your Scalekit dashboard; a mismatch here is the most common integration error.
Scalekit also ships native examples for Anthropic, OpenAI, Google ADK, and Claude managed agents.
Virtual MCP for a per-user, least-privilege endpoint
If you want an MCP endpoint instead of SDK calls, Scalekit's Virtual MCP Server gives every agent a scoped, user-specific MCP endpoint that declares exactly which BigQuery tools it can see and whose credentials it acts with, with no MCP server to deploy, host, or maintain.
One server definition serves all users; before each run, a short-lived session token is minted scoped to that user's connected account. The endpoint is static; the identity is per-user. A Scalekit Virtual MCP server URL looks like https://yourcompany.scalekit.com/mcp/v3/servers/<server-id>.
Setup is covered in the quickstart and configure a virtual MCP server.
Observability for multi-tool, multi-tenant agents
Every BigQuery tool call is logged with who triggered it, which query ran, and what came back, with 90 days of SIEM-ready history tied to the user who authorized it.
For an agent spanning BigQuery, Slack, and a CRM across many tenants, those agent auth logs answer the question a security reviewer always asks: under whose credential did this action run, and was it in scope.
The same vault and audit chain covers every connector, so adding the next tool adds no new auth code. This is how agent tool observability works at scale.
When the tool you need is missing
If the BigQuery action your agent needs is not yet a Scalekit tool, request it through the Scalekit Slack community or talk to the team. New connector requests typically land within a week, on the same vault and audit plumbing as every existing tool.
Which one to build against
- If your agent is an interactive analytics assistant that discovers schemas and runs read queries with modest result sets, the managed BigQuery MCP server is the faster path, and its IAM-based auth means a service account can drive it headlessly when needed.
- If your agent pulls large result sets, ingests data through the Storage Write API, reads in parallel through the Storage Read API, or manages org configuration, build against the API directly.
Most production BigQuery agents will use both, and either way the per-tenant credential problem is identical. That is the part that needs production-grade infrastructure.
Browse the Scalekit Google BigQuery connector.

.webp)