


The security community is doing what it does. That's not what this is about.
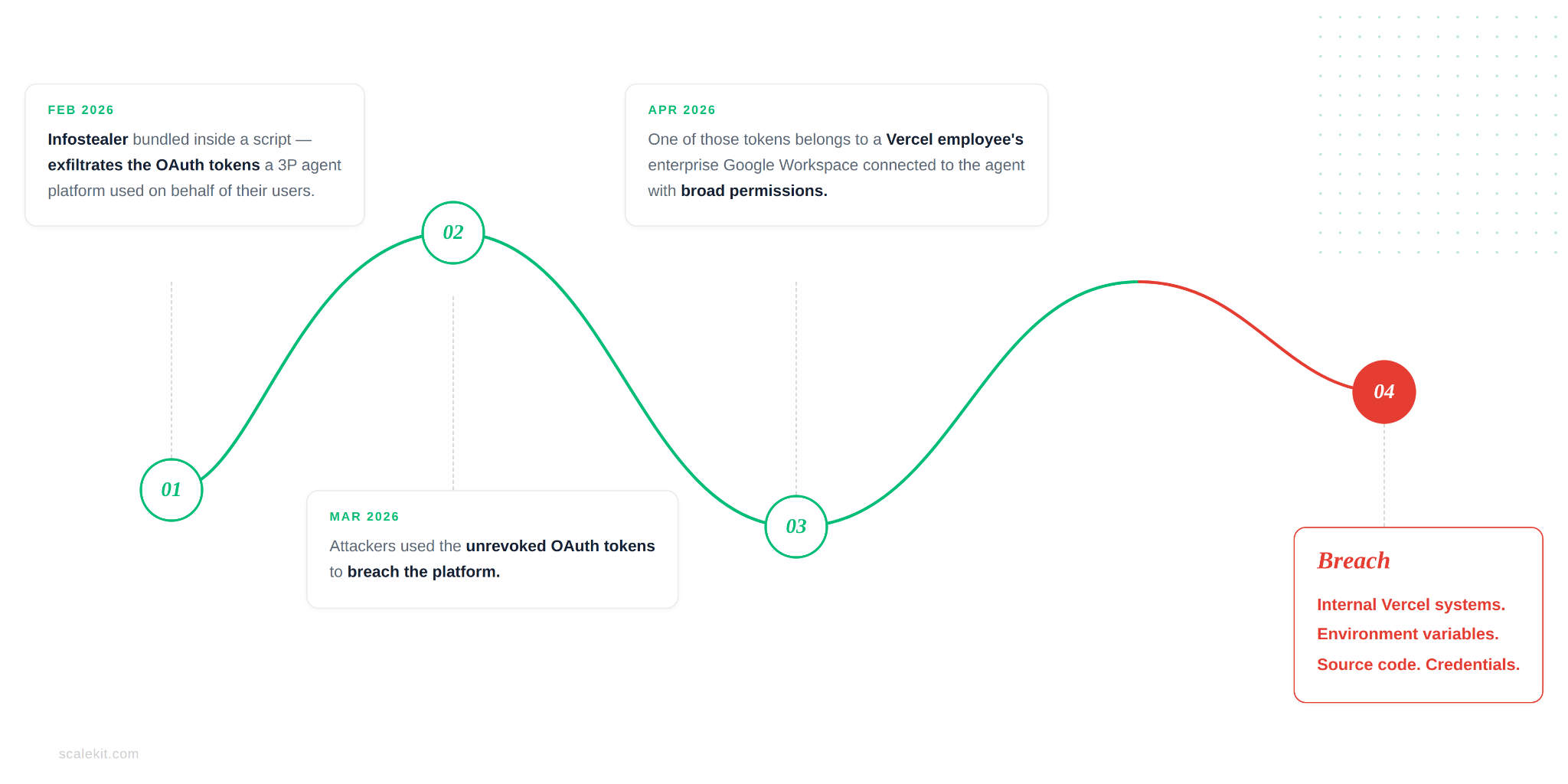
The breach didn't start at Vercel. It started at a third-party agent a Vercel employee had connected to their enterprise Google account - and it propagated through an OAuth token that stayed valid long after it should have been dead. That shape is worth understanding precisely, because it's the same shape in every agentic application being built today.
No phishing. No zero-day. No brute force. A door left open, not kicked in.
Most post-breach commentary has focused on "Allow All" permissions and the need to audit third-party integrations. That's not wrong - but it misses the root.
The more precise question: why were those tokens still valid and replayable - weeks after the breach?
When infrastructure holding OAuth tokens is compromised, those tokens should be invalidated as part of the response. The fact that they weren't - that they remained replayable from an unfamiliar IP, in access patterns nothing like the original user, weeks later - is a token architecture problem. Tokens stored without isolation, without event-triggered revocation, with no binding between infrastructure health and token validity.
OAuth tokens are identity. The moment an application stores a user's OAuth token in a general-purpose environment, that environment becomes part of the user's identity perimeter. A breach of the storage is a breach of every identity inside it. That tradeoff is worth designing for explicitly - not discovering after the fact.
When a user connects an agent to their Google Workspace, they're not sharing a password. They're delegating a slice of their identity to a platform they're trusting to hold it responsibly. That delegation lives as an OAuth token - and from that moment, the agent platform becomes its custodian.
Three questions every platform holding those tokens needs to answer:

Authorization in most systems answers one question: does this identity have access to this resource? That framing works when the actor is the person who holds the credential.

Agents break that assumption. When an agent takes an action using an OAuth token, it isn't acting as itself - it's acting on behalf of the human who granted consent. That distinction matters enormously for how authorization should work.
The right question isn't "does this token have access to this workspace?" It's "can this token holder take this specific action, on behalf of the human who originally granted consent, in this environment and context?"
Those are different questions. A token with workspace-level permissions, used to enumerate environment variables across hundreds of internal projects at 3am from an unfamiliar IP - it passes the first question. It should fail the second. The human who clicked approve months ago did not consent to that action, in that context, with that access pattern.
Authorization for agents needs to operate continuously - not as a gate at token issuance, but as an evaluation at every action. Scoped to what the agent was deployed to do. Bound to the context in which the original consent was granted. Suspicious patterns should trigger revocation, not just logging.
A human session has natural bounds - working hours, predictable actions, a person who notices when something looks wrong. An agent runs continuously, acts across multiple systems autonomously, and has no human in the loop. A compromised agent token doesn't expose a session. It exposes every action that agent is authorized to take, running until something explicitly stops it.
The gap between "this token is valid" and "this token should be doing this" is exactly where an attacker operates. With agents, that gap runs faster, wider, and longer than any human session.
Closing it - just-in-time token issuance, per-action authorization, revocation tied to infrastructure signals - is what production-ready agent auth requires. This is the problem Scalekit is built to solve.
Four things that separate an agent built to demo from one built for production. None of these are configurations. They're design decisions.
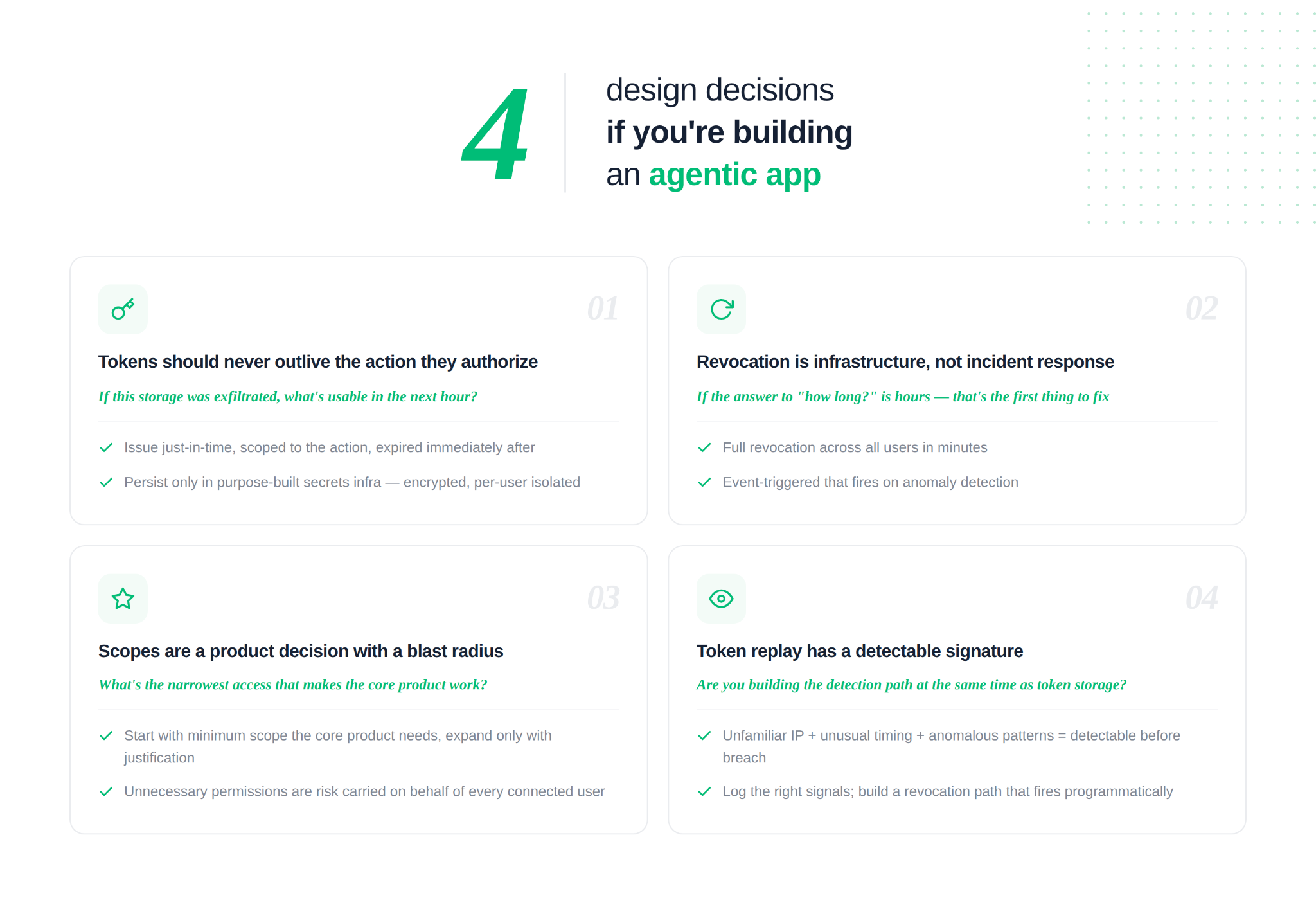
The four principles above aren't a security checklist. They're a description of what it means to hold someone else's identity seriously.
Every agent that connects to a user's tools - their calendar, their repositories, their internal systems - is operating inside their trust perimeter. The token that enables that access isn't application data. It's a credential, and it carries the same weight as a password with MFA bypassed: once it exists in an environment that gets compromised, the blast radius is exactly as wide as the token's permissions.
The breach that started with a downloaded script and ended with stolen credentials across an entire platform wasn't an outlier. It was the result of design choices that most agent applications are making right now - tokens stored where they shouldn't be, permissions broader than necessary, revocation paths that don't exist.
The bar for production-ready agent infrastructure isn't does it work? It's what happens when something in my stack is compromised? That question should be answered in the design, before the first user connects their account - not after the first incident makes it urgent.








