.png)


The agent was in production. One customer, one Slack workspace, one set of OAuth tokens living in .env. Clean demo. Signed contract. Smooth first two weeks of operation.
Then the second enterprise customer onboarded.
Their Slack was a different OAuth app with different workspace permissions. Their Salesforce had custom field mappings the agent had never seen. Their IT team sent a security questionnaire asking which credentials the agent held, under what scope, on whose behalf, and where those credentials were stored at rest. Their CISO asked what would happen to the agent's access if one of their engineers left the company mid-contract.
Three weeks followed: one near-miss data exposure where the agent pulled records from customer 1's Salesforce because the org_id filter was absent from the credential lookup. One enterprise deal nearly lost to a security review the architecture was never designed to pass.
Customer 2 is not an edge case. 88% of organizations have confirmed or suspected AI agent security incidents in the last year, and only 14.4% send agents to production with full security approval. The failure mode is not the model. It is the auth architecture underneath it. This piece maps exactly where the architecture breaks, and in exactly what order the breaks surface.
Before pipeline ordering, token lifecycle, or scope enforcement become relevant, the credential model itself is usually wrong. Not insecure in theory. Wrong in practice for any customer beyond the first.
Three credential models are used in agent prototypes. Each one looks reasonable at customer 1. Each one creates a specific, traceable incident at customer 2.
The service account model is operationally seductive. One credential to manage. No per-user consent flows to build. Customer 1's demo runs clean. But when customer 2 onboards, a critical sequence fails: assignee = currentUser() in the CRM or project management tool resolves to the service account identity, not the engineer who triggered the action. Linear issues get reassigned to a ghost account. Salesforce activity is logged against a service user nobody recognizes. The audit trail is technically complete and completely useless.
The deeper problem: service accounts centralize risk by design. When customer 2's IT team asks "what happens when one of our engineers leaves?" The answer with a service account is: nothing, automatically. The credential persists. The agent continues to run under it. The only remediation is manual key rotation that also breaks every other customer's agent simultaneously.
The admin account model creates the same blast radius with an additional vulnerability: it inherits full admin scope not because the agent needs it, but because the developer has it. Customer 2's security team will identify this during procurement. 45.6% of teams currently use shared API keys for agent-to-agent authentication, creating no individual accountability and no ability to scope or revoke access per agent instance.
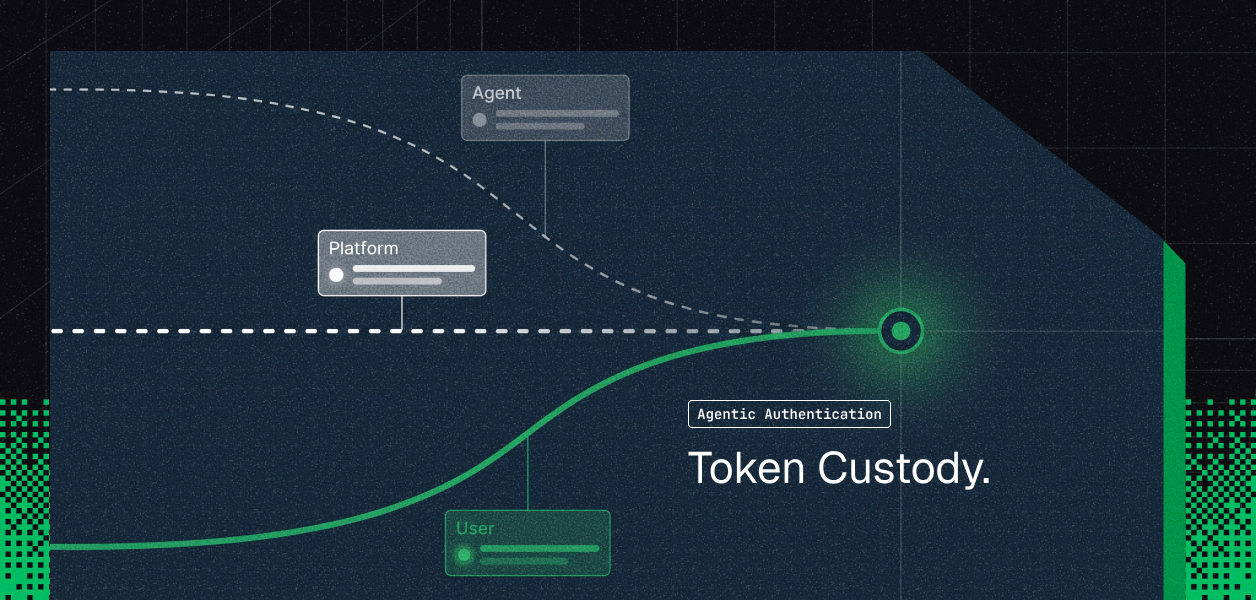
User-delegated OAuth is the only model where what the user can't do, the agent can't do. The scope is bounded by the authorizing user's actual permissions. Revocation is per-user and per-connection. Customer 2's engineer leaving triggers a revocation event on that specific connected_account; nothing else is affected.
Scalekit handles this layer: Connected accounts are the implementation primitive. Each user who authorizes an agent gets a connected_account_id scoped to their user_id and org_id. No shared credentials across tenants. No raw tokens in application code. The agent calls execute_tool with a connected_account_id; Scalekit resolves the credential from the vault, checks scope, and executes the call. The agent never sees a token.
For a deeper treatment of all four access models and their production tradeoffs, see API Access Patterns for AI Agents and Who Holds the Token? Credential Ownership Across Agent Tool-Calling Patterns.
Assume the credential model is now correct: per-user delegated OAuth, connected accounts, vault-backed storage. Customer 2 is onboarded with their own org_id. The agent still produces a data leak. The credentials were right. The pipeline ordering was wrong.
The five steps every tool call must traverse, in this order:
Auth → Tenant Resolution → Scope Enforcement → Tool Execution → Audit Log
Breaking this sequence, skipping a step, or deferring one step to inside another is not a configuration issue. It is a structural security bug. Each deviation has a specific, silent failure mode.
The ordering failure that causes the most production incidents: tenant resolution happening inside the tool handler rather than before dispatch. Concretely, this looks like:
The wrong version will not throw an error. It returns results. The results happen to belong to customer 1 when called from customer 2's context. No exception is raised. No alert fires. The leak is discovered three weeks later during an internal audit, or not at all until a customer discovers it.
The connection_id is the structural fix. A connection_id carries user_id, org_id, and the scopes granted at consent time as a single resolved unit. It is established before the tool call and passed through every subsequent step. The audit log entry that references a connection_id can be traced back to the exact authorization event that created it. A user_id in the log cannot; it requires a secondary lookup that may return ambiguous results across tenants.
The three privilege escalation patterns from this pipeline break are: parameter injection via message payload, token reuse across tenants, and stale in-memory session mappings. All three are config failures, not attack vectors. All three are prevented by resolving tenant context before dispatch and binding it to an immutable connection_id.
Scalekit handles this layer: execute_tool(connected_account_id, tool_name, params) enforces pipeline ordering by design. The connected_account_id is resolved at the vault layer before the tool fires. Scope is checked against the OAuth grant from the consent event, not the prompt. Every call produces an audit record with connection_id, org_id, user_id, and scope — automatically.
For the five-layer identity model and privilege escalation patterns in depth: Access Control for Multi-Tenant AI Agents and Agent Tool Calling Auth: Patterns and Anti-Patterns.
The credential model is correct. The pipeline is ordered correctly. Customer 2 is live. The agent runs continuously as a background process, refreshing Slack summaries every hour, updating CRM records on a schedule, syncing project states overnight. Three months in, it starts failing silently. No errors in the log. No alerts. Tasks just stop completing.
Token lifecycle failures are the failure class that takes the longest to diagnose because they do not produce immediate errors. They produce silent degradation. The standard mental model — "tokens expire, we refresh them, done" — covers one of four sub-problems. The other three are active production incidents waiting for the right conditions to surface.
Per-tenant encrypted vault is not the same as a database column with AES-256 encryption. The distinction is fault isolation. With a shared encrypted store, a single compromise exposes the decryption path to all tenant credentials simultaneously. With isolated vault storage, a compromise of tenant A's credential store does not provide access to tenant B's. This is the infrastructure definition of tenant isolation; it is not achievable with field-level encryption on a shared table.
28.65 million hardcoded secrets were added to public GitHub in 2025, a 34% year-over-year increase; AI-assisted code showed roughly double the secret leak rate of the GitHub-wide baseline. The velocity of code generation is increasing faster than human review capacity. Secrets that should never be in code end up there through automation, and they end up there at scale.
The token refresh race condition is the failure that only manifests at N > 1 concurrent background workers. The sequence:
This is not a theoretical edge case. It is a production incident that appears intermittently and is difficult to reproduce in staging because staging typically runs single-threaded workers. The fix requires a distributed lock on the refresh operation scoped to connected_account_id, with TTL management and retry semantics.
Provider-specific refresh behavior that must be handled distinctly:
Rotation is a provider-side behavior, not an application-side choice. The operational requirement: the vault must update the stored credential atomically when a rotation occurs. Non-atomic updates — write new access token, then write new refresh token as two separate operations — create a window where the stored refresh token is the old one but the provider considers it invalidated. Any concurrent read during that window gets an invalid credential.
Revocation and expiry are structurally different events that require structurally different handling. Expired token → proactive refresh resolves it. Revoked token → the user explicitly withdrew authorization; there is no credential to refresh; automated retry will return 401, then 403, then potentially trigger account lock sequences at the provider level.
The wrong handling: a retry loop on 401. The correct handling: check for revocation error codes distinct from expiry codes (providers signal these differently), cease automated operation, surface a re-authorization request to the user, and stop all agent actions under that connected_account_id until re-authorization completes.
Scalekit handles this layer: The vault stores credentials with per-tenant isolation. Proactive refresh runs on expires_in rather than 401 response. Distributed locking prevents concurrent refresh race conditions. Rotation is handled atomically per connector's specific behavior. Revocation events are surfaced via agent webhooks, which trigger re-authorization flows and halt dependent agent actions. The provider-specific edge cases — Slack's single-use rotation, GitHub's missing expiry, HubSpot's 30-minute window — are handled at the connector layer without application code.
For detailed refresh mechanics and the race condition architecture: How to Handle Token Refresh for AI Agents. For the build-vs-buy cost of implementing this correctly: The Hidden Cost of Building OAuth Internally for AI Agents.
The credential model is correct. The pipeline is ordered. Token lifecycle is handled. The agent passes the technical security review. Then the enterprise customer's security architect asks one more question during the SOC 2 audit: "Can you demonstrate that the agent was structurally constrained to access only what the user authorized — not just instructed to?"
There is no good answer to that question if scope enforcement happened inside the agent's reasoning loop.
Prompt-level scope enforcement looks like this: "You are an agent with access to GitHub. Only read repositories that are relevant to the current task. Do not access sensitive configuration files." This is a natural language instruction to a probabilistic reasoning system. Under normal operating conditions, it works. Under the right context pressure — a deeply nested tool call, a multi-step reasoning chain, a prompt injection in a document the agent processes — the instruction is reweighed against the available context and may lose.
The GitHub example is concrete: an agent with a broad OAuth scope including get_repository_secrets is given the instruction "gather context about this repository." The reasoning system does not recognize secrets retrieval as out of bounds for "gather context." It is not a misconfiguration. It is the agent doing exactly what it was designed to do, within an access boundary that was never structurally enforced. Stanford's Trustworthy AI Research Lab found that model-level guardrails alone are insufficient: fine-tuning attacks bypassed leading models in the majority of cases. Model-layer safety does not extend to the execution layer.
Infrastructure-level scope enforcement means: the OAuth grant issued at user consent carries specific scopes. Those scopes are bound to the connection_id. Before execute_tool fires, the scope is checked against the grant — not against the prompt. If the call requires a scope not present in the grant, the call is rejected before execution. The agent gets an error, not data.
The compliance implications make this a hard requirement, not a recommended practice:
The audit log consequence: a log entry that records user_id and action proves attribution. It does not prove authorization. A log entry that records connection_id proves attribution and authorization because the connection_id carries the consent event, the granted scopes, and the authorization chain back to the user who approved them.
An agent that posts to a Slack channel the user never authorized is an error that prompts a support ticket. An agent that does the same and produces no verifiable proof of what it was scoped to access is an enterprise deal terminated in the next security review cycle.
Scalekit handles this layer: OAuth scopes are bound to the connection_id at the moment the user completes the consent flow. Every execute_tool call checks the requested operation against the scopes present in the grant before execution — not inside the agent's reasoning. The audit log entry for every call carries connection_id, scope, org_id, user_id, and the result. Scope change events are logged separately with the identity of the approving user. Auth logs are exportable to Datadog, Splunk, or any SIEM with 90-day retention by default.
For the compliance standard mapping and audit trail architecture: Audit Trails for Agent Auth in B2B SaaS and Why Your IAM Setup Doesn't Cover AI Agents.
The four sections above map four failure dimensions in the order they surface during a real enterprise onboarding. The verification groups below are structured in the same order. Before the second enterprise customer signs their MSA, each group should return a clear yes. If any group surfaces a no, the corresponding section above identifies the architectural fix.
This is not a general security checklist. It is a test of whether the specific failure modes diagnosed above are present in your current architecture.
Verifies the failure mode from Section 1.
If any of these is absent: the blast radius of a credential compromise or employee offboarding event expands to all tenants simultaneously.
Verifies the failure mode from Section 2.
If any of these is absent: tenant data can cross org boundaries without throwing an error, and scope violations produce no verifiable audit record.
Verifies the failure mode from Section 3.
If any of these is absent: background agents fail silently under concurrency load, or continue retrying against revoked credentials until account lock.
Verifies the failure mode from Section 4.
If any of these is absent: a SOC 2 audit cannot be satisfied with evidence, and a GDPR data access inquiry cannot be answered with verifiable attribution.
Field-level encryption protects the tokens if the database is exfiltrated, but it does not provide tenant isolation at the storage layer. The decryption key is typically shared across all rows, or managed at the application layer rather than the storage layer. If the application's decryption path is compromised, all tenant tokens are accessible through the same path. Vault-based storage isolates decryption per tenant so that a compromise of one tenant's credential store does not expose another's.
Two things break simultaneously: First, the agent's effective permissions are the service account's permissions, not the permissions of the specific user whose context triggered the action. If customer 1's Salesforce service account had read-write on all objects, and customer 2's Salesforce restricts write access to certain record types, the agent will behave differently across customers without surfacing any error. Second, every action is attributed to the service account identity in audit logs. Customer 2's security team cannot answer "which of our users authorized this action" with a service account audit trail. That question fails the SOC 2 review.
No. A retry loop on a revocation 401 is incorrect handling with specific consequences. Some providers implement progressive error codes: repeated failed refresh attempts can result in 403 responses or account-level rate limiting that affects all of your application's tokens for that workspace, not just the revoked user's token. The correct handling: distinguish revocation errors from expiry errors using the provider's error response body (Slack returns token_revoked; Google returns invalid_grant), cease all retry, surface a re-authorization event to the user, and halt agent operations under that connected_account_id until re-authorization completes.
Because a system prompt is a natural language instruction to a probabilistic reasoning system; it is not a constraint on the OAuth token's granted scopes. The agent can be instructed not to read sensitive files, and still read them if the reasoning context makes it seem relevant — not through defiance, but through the probabilistic nature of token prediction under context pressure. Structural scope enforcement means the OAuth grant physically does not include the scope for the call; the infrastructure layer rejects the call before execution. That is not achievable with a prompt.
A user_id identifies who triggered the action. A connection_id identifies who authorized the action, under what scopes, at what point in time, through what OAuth grant. For a SOC 2 CC6.1 audit, the question is not "who triggered this action" but "were the credentials valid and appropriately scoped at the time of this action." A connection_id answers that question by tracing back to the consent event and the scopes granted. A user_id alone does not.