Human-in-the-Loop Tool Calling: Approval Gates Before Your Agent Writes


TL;DR
- OAuth scope answers "can this agent call this tool?" It cannot answer "should this specific invocation execute, with these arguments, right now?" Approval gates answer the second question, at execution time.
- Write operations break the "grant once, run forever" credential model along three axes: irreversibility, audit obligation, and dynamic risk context that static scope cannot model.
- Three patterns address invocation-level authorization: the Pause-Resume Interrupt (human approval required before execution), the Dynamic Authorization Check (policy evaluation at tool invocation time, routes to human if policy escalates), and the Scope-Escalation Request (mid-workflow re-consent for additional scopes).
- When an agent pauses for approval, the credential valid at pause time is not guaranteed to be valid at resume time. This is the failure most approval-gate implementations skip, and it is where production systems break.
- The queue-then-execute model decouples approval latency from agent execution latency. The vault holds credential state across the pause window; the agent references a user identity and connection name, never a raw token.
- Scalekit's AgentKit provides the vault, token lifecycle management, and connected_account state the queue-then-execute model depends on. The approval queue itself (routing, reviewer assignment, approval storage) is your application layer.
Consider an agent has everything it needs: valid OAuth credentials, correct scope, a user who had authorized access weeks earlier. It reaches a GitHub tool call mid-workflow, evaluates the diff, and merges to main with auto-merge enabled. No one approved that specific call. No one had the chance to.
This is not a prompt injection story, and it is not a compromised credential story. The agent was operating exactly as designed. The scope covered the action. The token was live. It was, by every traditional auth measure, fully authorized. What it was not: contextually authorized. Nobody said "merge this diff, right now, with these arguments, to this branch."
That gap, between "technically authorized" and "contextually authorized," is where production agent systems fail silently. By 2026, autonomous agents outnumber humans in enterprise environments at an 82:1 ratio, yet only 22% of organizations treat AI agents as identity-bearing entities with formal access controls.
The governance gap is not theoretical. Approval gates are the engineering answer. Not a UX affordance; an authorization primitive.
The Authorization Gap OAuth Was Never Designed to Close
OAuth scope is a grant-time primitive. When your user authorizes the agent, they answer one question: "should this agent be allowed to call this category of operation?" That decision is made once, at consent time, and the resulting token carries the answer forward into every subsequent tool call.
This works for read operations. The risk profile of a read is bounded by what the agent does with the data. The operation itself is non-destructive. The scope grant from three weeks ago is still a reasonable proxy for the user's intent today.
Write operations are structurally different.
- Irreversibility. DELETE /record/8823, POST /merge, PATCH /account/billing: none of these can be undone by revoking the token post-execution. The token was valid. The action ran. Revocation is forensic at that point, not protective. Anthropic's published framework for trustworthy agents explicitly calls out irreversibility as a distinct risk axis, stating that agents should prefer reversible over irreversible actions and request narrower scope when the reversibility of an operation is unclear.
- Audit obligation. SOC 2 requires evidence that logical access controls were functioning at the time of each action. GDPR requires that processing records carry a clear lawful basis tied to the acting identity. Most enterprise security reviews go further: they require that writes carry not just "the agent had scope" but "a human authorized this specific operation at this timestamp." Scope grants do not satisfy that requirement. Approval events do.
- Dynamic risk context. A salesforce_update_record call touching one field in a sandbox and the same call bulk-updating 10,000 production records share the same OAuth scope. The risk profile is not the same. Static scope cannot model the difference. Only contextual authorization at execution time can.
The structural consequence is precise: OAuth answers "can this agent call this tool?" Approval gates answer "should this invocation execute, with these arguments, in this context?" These are two different authorization questions. Both must be answered before a write executes.
Here is where agent auth implementations diverge.
Three Patterns for Invocation-Level Authorization
These three patterns are not mutually exclusive. In production systems, they compose: Pattern B classifies every write and routes to Pattern A or Pattern C based on policy evaluation. Understanding them separately is necessary to understand how they combine.
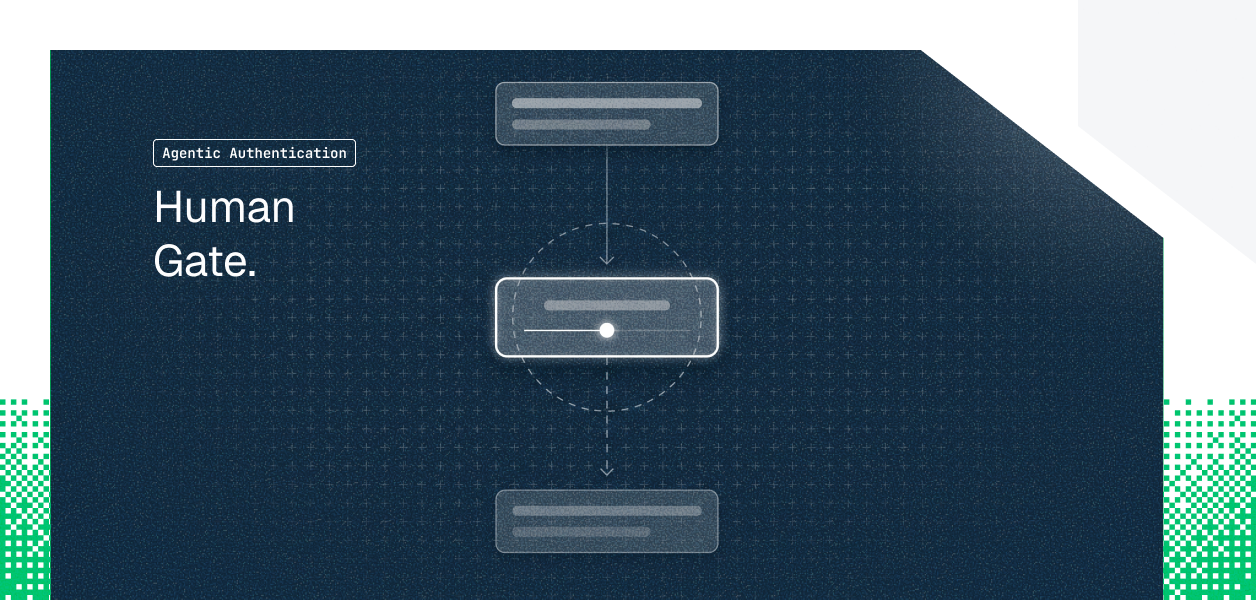
Pattern A: Pause-Resume Interrupt
The agent reaches a write tool call. Instead of executing, it serializes the pending invocation and emits an approval request. Execution is blocked. The agent's graph is parked at the write node, with full state preserved, until an approval signal arrives.
In LangGraph, the current recommended primitive is interrupt() (introduced as the preferred approach in January 2025, superseding NodeInterrupt), called inside a node to pause the graph and return a payload to the caller. The graph stops at exactly that line; execution resumes when the caller sends back a decision. The entire state snapshot is persisted to the checkpointer. Without a checkpointer configured, interrupt() has nowhere to park state, and the pattern does not work.
In the OpenAI Agents SDK, the same pattern is expressed via RunState serialization: the run surfaces pending approvals as interruptions, you serialize RunState to disk, reload it, collect the decision, and resume the original run. The mechanism differs by framework; the requirement is the same: the framework must support resumable execution with persisted state.
credential_status in the payload is not optional. If the connected account's token expires or is revoked before approval arrives, the agent must know this at resume time rather than discovering it mid-execution via a 401. Including the status at serialization time lets the resume path check before calling the tool.
Tradeoff: This pattern introduces latency that is entirely human-dependent. An approval that takes 4 hours holds the agent's checkpoint for 4 hours. For long-running agents with many concurrent pending approvals, checkpoint storage becomes a capacity concern. The queue-then-execute model described later in this post addresses this by decoupling checkpoint state from approval state.
Pattern B: Dynamic Authorization Check
Not every write needs a human in the loop. Some writes are low-risk enough to proceed under a pre-defined policy; some are high-risk enough to block outright; some fall into a gray zone where the policy escalates to Pattern A. Pattern B is the classifier that routes all writes to one of these three outcomes.
The critical distinction from IAM role checks at login time: this evaluation happens at tool invocation time, not at session establishment. The same user with the same OAuth grant may receive different outcomes on the same tool call, depending on runtime context.
The evaluation inputs:
A policy that enforces "developers can merge to feature/* branches but not to main; merges to main require human approval" cannot be expressed in OAuth scope alone. It requires evaluation of resource_path at invocation time. The policy outcome for refs/heads/main is ESCALATE (routes to Pattern A). The outcome for refs/heads/feature/billing-refactor is ALLOW.
Important boundary: This policy evaluation layer is your application code, not a Scalekit feature. Scalekit enforces that every tool call is scope-checked per connector, per tenant, and that credentials never reach the agent runtime. The ALLOW/BLOCK/ESCALATE routing logic on top of that is yours to define.
Tradeoff: Policy maintenance is a real cost. Policies that are too broad (escalate everything) defeat the purpose of having a classifier. Policies that are too narrow leave gaps. Start with a default-deny posture for production environments, carve out explicit allows, and log every BLOCK and ESCALATE for policy tuning.
Pattern C: Scope-Escalation Request
The agent, mid-workflow, reaches a write that requires a scope not covered by the user's current authorization. The naive implementation fails with 403. The overcompensating implementation pre-grants maximum possible scope at agent setup time, violating least-privilege and failing every enterprise security review.
The correct implementation: detect that the connected account does not have the required authorization, surface a targeted re-consent request to the user, and resume only after the user has completed it.
In Scalekit, the scope update flow works as follows:
- Update the connection's required scopes in AgentKit > Connections > Edit (or via API).
- Call actions.get_authorization_link(connection_name, identifier) to generate a new hosted authorization URL for the specific user.
- The user completes the OAuth consent screen for the updated scope set.
- Scalekit updates the connected_account with the new token set; the account returns to ACTIVE status.
- The agent resumes the pending invocation.
This is not a silent background token exchange. It requires an explicit user action. The user sees exactly which connection is requesting updated access. That consent event is the audit record that satisfies "a human authorized this scope extension at this timestamp."
Tradeoff: This creates a blocking user interaction mid-workflow. For background agents running without a live user session, scope escalation is not possible; the agent must fail with a clear error rather than attempting to acquire scopes silently. Design your initial scope set to cover the full range of operations a background agent will execute. Reserve Pattern C for interactive, user-present workflows.
The Credential Lifecycle Problem During the Pause Window
This is the section that most approval-gate implementations skip. It is where production systems actually break: not at design time; at 11:47pm when an approval that was requested at 10:15am finally comes in.
Scalekit models each user's authorization state as a connected_account with explicit status: PENDING, ACTIVE, EXPIRED, REVOKED, or ERROR. Three specific failure scenarios map directly to these states.
Scenario 1: Account transitions to EXPIRED during the approval window
The user's OAuth token expires while the approval request is pending. Scalekit automatically refreshes access tokens using the refresh token; but if the refresh token itself has expired, or if the provider requires re-consent, the account transitions to EXPIRED. The agent resumes and attempts to call execute_tool(). Scalekit returns an error because the account is no longer ACTIVE.
The correct handling is to check connected_account.status before executing, not after receiving an error:
Scenario 2: Account transitions to REVOKED during the approval window
The user revokes the agent's OAuth grant from the provider's connected apps page while the approval request is pending. Scalekit's Agent Webhooks feature delivers connected account lifecycle events and auth signals in real time. When your system subscribes to these events, it can cancel the pending approval request immediately when the underlying credential state changes, rather than waiting for the resume path to discover the revoked state.
This is the correct production architecture: Agent Webhooks are your real-time signal; the get_connected_account() status check on resume is your safety net. Relying only on the status check at resume time means the approval request stays pending (and occupies space in your queue) for the full duration until someone approves or the TTL expires.
Scenario 3: Scope set changes during the approval window
A Scalekit connection's configured scopes are updated between the approval request and resume (for example, an admin narrows the scope set in AgentKit > Connections > Edit). Scalekit will issue a re-authorization event. The correct handling on resume: check connected_account.status first. If the account is not ACTIVE because the scope change forced a re-consent, escalate to Pattern C rather than attempting to execute with the stale authorization. A status check caught before execution produces a clear, actionable signal; a 403 from the downstream API does not.
The Queue-Then-Execute Model: Full Architecture
The three patterns describe what to check. This section assembles the infrastructure that holds everything together across the pause window.
AGENT reaches write tool call →
YOUR APPROVAL QUEUE (application layer)
AGENT RUNTIME resumes →
The state machine for any pending invocation:
terminal_credential_inactive is the state most implementations do not handle. They either loop on retry or silently drop the execution. Both are wrong: retrying a REVOKED account does not recover it (the user must explicitly re-authorize); silently dropping leaves an approved-but-unexecuted action in the audit trail with no resolution event. Every terminal state must emit a resolution_event. The audit trail must be closed even for failures.
Why this is not "just add a confirmation dialog"
The queue decouples approval latency from agent execution latency. Approvals that take hours do not block the agent runtime thread or hold checkpoint memory. Multiple pending approvals can be batched, prioritized, and routed to different reviewers independently. Scalekit's vault decouples credential freshness from approval timing: the agent carries connection_name and identifier across the pause window, not a raw token, so token rotation during the pause is invisible to the approval flow.
Scalekit Addresses All 3 — Vault, Per User Auth State, Observability
The queue-then-execute model has three infrastructure requirements on the credential side: a vault that manages tokens outside agent code, a model that tracks per-user authorization state explicitly, and credential lifecycle handling that surfaces state changes in real time rather than surfacing them as opaque API errors.
Scalekit's AgentKit addresses all three.
- The vault. OAuth credentials are encrypted and stored in a centralized vault, AES-256, per-tenant isolated. Agents call
execute_tool()with aconnection_nameand useridentifier; Scalekit resolves the credential, validates its state, refreshes if needed, scope-checks per connector, and executes the authenticated API call. The agent never holds a raw token. Raw credentials never appear in agent code, logs, or LLM context. - Per-user authorization state. Every user's authorization is modeled as a
connected_accountwith explicit status (PENDING,ACTIVE,EXPIRED,REVOKED,ERROR). The resume path calls get_connected_account(connection_name, identifier) before executing; the response includes connected_account.status, giving the application layer a clean gate on the credential state before any tool call is dispatched. - Real-time state signals. Agent Webhooks delivers connected account lifecycle events, auth signals, and token activity in real time. Subscribing to these events lets your approval queue cancel or escalate pending requests immediately when the underlying credential state changes, rather than discovering the problem only when the agent resumes.
- Scope updates. When Pattern C triggers, get_authorization_link(connection_name, identifier) generates a hosted re-authorization URL scoped to the specific user and connection. Scalekit's hosted page adapts to the connector's auth type automatically (OAuth consent screen for OAuth connectors; credential form for API key or basic auth connectors). After the user completes re-consent, Scalekit updates the
connected_accountwith the new token set. No custom re-authorization UI required.
What Scalekit does not provide: the approval queue itself. Routing logic, reviewer assignment, approval event storage, TTL enforcement, and the resume trigger are your application layer. Scalekit handles the credential infrastructure on either side of the queue. What happens inside the queue is yours to build and own.
FAQs
Can the same correlation_id span multiple approval gates in one workflow?
Yes, and this is the expected pattern for complex agent workflows. Each write that escalates gets its own approval_id, but all share the same correlation_id from the originating workflow run. This lets an auditor reconstruct the full decision sequence: which writes were auto-allowed by policy, which were escalated, which were approved, which were rejected, and in what order.
What happens if the LangGraph checkpointer is lost between approval request and resume?
The approval queue holds the serialized invocation payload independently of the agent's checkpoint store. If the checkpoint is lost or corrupted, the approval event can still be matched to the pending invocation in the queue via correlation_id. The correct behavior: surface this to the user as an execution failure with the payload preserved, not a silent discard. The queue must be the source of truth for pending invocations, separate from the framework's checkpoint store.
Should Pattern B policy evaluation happen inside the agent graph or at the tool execution layer?
At the tool execution layer, not inside the agent's reasoning loop. Policy evaluated inside the LLM's context is visible to the model and can lead to prompt-level attempts to re-route around the policy. Evaluated at the tool execution layer before the call is dispatched, a blocked invocation simply never happens from the agent's perspective. No reasoning context is polluted.
How do approval gates interact with multi-agent workflows where a sub-agent calls tools on behalf of an orchestrating agent?
The pending invocation payload must carry the full delegation chain, not just the immediate calling agent's identity. The approver needs to see who delegated authority to whom, tracing back to the original triggering user. An approval that surfaces only the sub-agent's identity and not the delegation chain produces an audit record that cannot satisfy SOC 2 or HIPAA trail requirements for action attribution.
Does Scalekit notify the agent if a connected account is revoked while an approval is pending?
Yes, via Agent Webhooks. The feature delivers connected account lifecycle events (including account disconnection) in real time. Subscribe to these events in your approval queue logic to cancel pending approvals proactively, rather than relying solely on the get_connected_account() status check at resume time. The webhook is the real-time signal; the status check on resume is the safety net.