Cloudflare MCP vs Cloudflare API for AI Agents (2026)


TL;DR
- Cloudflare exposes two MCP surfaces: the Code Mode API server at mcp.cloudflare.com (two tools, search() and execute(), covering the full v4 API of 2,500+ endpoints) and 16 product-specific servers. Coverage is broad; the real gaps are in the data plane, not in endpoint count.
- Cloudflare MCP is not OAuth-only. It accepts interactive OAuth and a Cloudflare API token passed as a bearer for headless or CI/CD use. The "MCP can't run without a user present" constraint that defines other vendors does not apply to Cloudflare.
- Cloudflare auth is API-token based, not per-user SaaS OAuth delegation. User tokens inherit a subset of a user's permissions; account tokens are durable service principals; the legacy Global API Key carries full permissions and is not recommended.
- The genuine MCP vs API tradeoff is determinism and data-plane reach. Code Mode runs model-written JavaScript in a sandbox; the direct API gives you pinned, schema-stable calls plus the S3-compatible R2 data plane that the MCP surface cannot reach.
- For multi-engineer or multi-tenant agents, both paths leave you N scoped tokens to store, rotate, and revoke. Scalekit's Cloudflare connector vaults the per-engineer API key, scopes every call, and logs it, so the MCP vs API choice does not change your auth infrastructure.
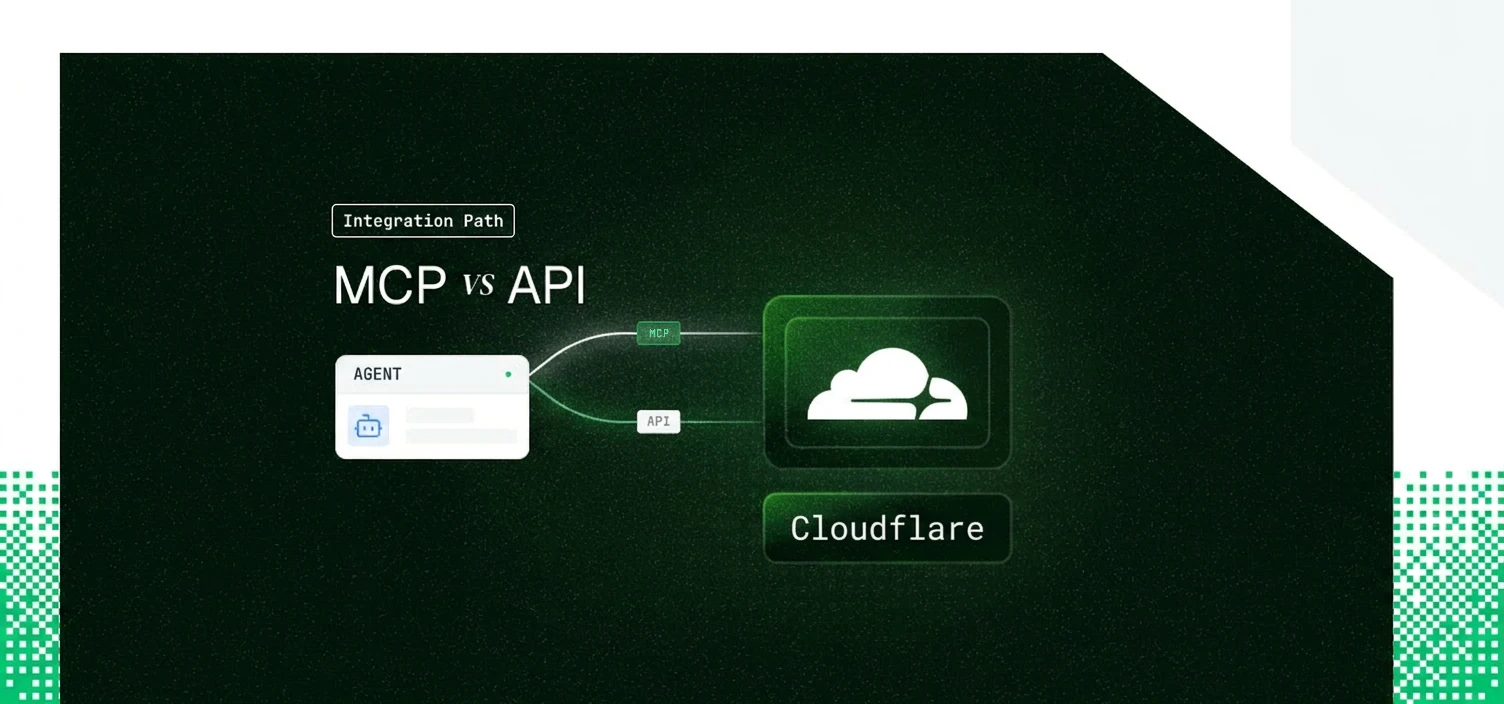
Your infrastructure agent needs to drive Cloudflare: deploy a Worker, edit a DNS record, purge a cache route, read observability logs. Cloudflare ships both a catalog of managed remote MCP servers and a REST API spanning over 2,500 endpoints. They are not the same object, and the choice is not obvious. The twist specific to Cloudflare: the usual "MCP is interactive-only, the API is for headless" split does not hold here. Here's how to actually pick.
What Cloudflare MCP and Cloudflare API actually are
Cloudflare MCP
Cloudflare runs a catalog of managed remote MCP servers you can connect to from clients like Claude, Cursor, Windsurf, or any SDK that speaks MCP. They support the streamable-http transport at /mcp and the deprecated sse transport at /sse.
The headline server is the Cloudflare API MCP server at https://mcp.cloudflare.com/mcp. It exposes the entire Cloudflare API through two tools, search() and execute(), using a technique Cloudflare calls Code Mode: the model writes JavaScript against a typed representation of the OpenAPI spec, and that code runs in an isolated Dynamic Worker sandbox. Alongside it, Cloudflare ships product-specific servers for areas like Observability, Radar, Workers Bindings, Browser Rendering, and more.
Authentication is OAuth for interactive clients, or a Cloudflare API token passed as a bearer header for automation. Official reference: the Cloudflare MCP servers page.
Cloudflare API
The Cloudflare API is a versioned REST surface at https://api.cloudflare.com/client/v4/, with a GraphQL analytics endpoint and several data-plane APIs alongside it. It exposes the full platform: DNS, Workers, R2, KV, Zero Trust, Stream, and every other product.
Authentication uses the RFC-compliant Authorization: Bearer header with API tokens, or the legacy Global API Key with X-Auth-Email and X-Auth-Key headers. Official reference: the Cloudflare API documentation.
Comparing them where it matters for agents
What your agent can actually do
For most vendors in this series, the MCP server is a curated subset of the API. Cloudflare breaks that pattern. The Code Mode server reaches the entire v4 surface, so the comparison is less about endpoint count and more about determinism and which data planes each path can touch.
Tools, sourced from official docs
This inventory comes only from Cloudflare's official documentation and its open-source server repository, so you can see precisely what each path reaches.
The Code Mode API server exposes exactly two tools. search() queries the OpenAPI spec to find the right endpoint, path, and schema. execute() runs a JavaScript function that calls the Cloudflare API client. Cloudflare's own published figures make the design rationale concrete.
The product-specific servers
In addition to the Code Mode server, Cloudflare publishes product-specific servers, each scoped to one domain: Documentation, Workers Bindings, Workers Builds, Observability, Radar, Container, Browser Rendering, Logpush, AI Gateway, AI Search, Audit Logs, DNS Analytics, Digital Experience Monitoring, Cloudflare One CASB, GraphQL, and Agents SDK Documentation. Use these when the agent works inside a single area and you want curated, typed tools rather than model-written code.
What the API reaches that MCP does not
Two gaps are structural, not temporary. The first is the R2 object data plane: object reads and writes go through the S3-compatible API on a separate endpoint with its own access keys, which the management-API-based Code Mode server does not wrap. The second is live log tailing: a streamed tail session runs over a WebSocket, which is not a request-and-response pattern Code Mode can drive. For these, the direct API is the path.
The auth path each one puts you on
This is where Cloudflare diverges most sharply from the rest of the series, so read it carefully before reusing assumptions from a Slack or Salesforce agent.
MCP accepts OAuth and API tokens
Interactive MCP clients authorize through a browser-based OAuth flow and select the permissions to grant. For CI/CD or automation, Cloudflare's documentation is explicit: you create a Cloudflare API token with the permissions you need and pass it as a bearer token in the Authorization header. Both user tokens and account tokens are supported. A headless agent can authenticate to the MCP server without a user present.
The API uses tokens and a legacy key
The REST API authenticates with API tokens or the legacy Global API Key. There are two token shapes worth distinguishing. User tokens act on behalf of a particular user and inherit a subset of that user's permissions; they go inactive if the user is removed from the account. Account tokens are durable service principals with their own permission set, ideal for integrations that must keep working after the person who configured them has left. The Global API Key carries the user's full permissions, is limited to one per user, and is not recommended for new builds.
What this means for multi-tenant agents
Because both paths support API tokens, the headless question does not pick a winner here. The credential question still does. A multi-tenant agent acting across many customer Cloudflare accounts holds one scoped token per account or per engineer. MCP's OAuth flow gives you a token per user; the API path gives you a token per user or per account. In neither case does the path itself store, rotate, or revoke those tokens. That remains an infrastructure problem regardless of which path you choose.
What you own in production
Code execution versus deterministic calls
The Code Mode server has the model write JavaScript on each run. That is flexible and token-efficient, and the code is sandboxed, but the generation is non-deterministic by nature. The direct API gives you pinned, schema-stable calls you control. For a nightly pipeline where an unexpected change is an incident, the deterministic path is the more predictable dependency.
Schema drift and versioning
Managed MCP tools and schemas can change when Cloudflare updates the hosted servers; you consume a contract whose cadence you do not control. The REST API is pinned to v4, and you migrate on your own schedule. That distinction matters most for deterministic production pipelines.
The rate-limit budget is shared
Cloudflare enforces a global limit of 1,200 requests per five minutes per user, counted cumulatively across the dashboard, API keys, and API tokens. MCP tool calls hit the same underlying API and count against the same budget. An agentic workflow issues multiple sequential calls per user action, so a shared credential burns the budget fast. Per-engineer or per-account tokens distribute it. Monitor usage from day one; neither path exempts you from the limit.
When to use MCP, when to use the API
Use Cloudflare MCP when
- Your agent is an interactive infrastructure assistant in Claude Code, Cursor, or a similar context, and you want broad account access through search() and execute() without writing API client code
- The agent works inside one product area and a curated server (Observability, Radar, Bindings, Browser Rendering) gives it exactly the typed tools it needs
- You want token-efficient access to the full Cloudflare surface and are comfortable with model-written code running in a sandbox
- You are validating an infrastructure agent concept quickly and want a managed endpoint rather than your own integration layer
Use the Cloudflare API when
- Your agent needs the R2 object data plane, live log tailing, or any surface that lives outside the v4 management API
- You are running a deterministic pipeline where pinned schemas and a fixed API version matter more than automatic tool updates
- You need account-token service principals that survive an engineer's departure, configured and versioned by you
- You are building high-volume automation and want direct control over pagination, retries, and the shared rate-limit budget
The credential problem that exists on both paths
Both paths hand you tokens, not a vault
Whether you connect through MCP or call the API directly, every engineer or every customer account in your system has its own Cloudflare credential. Fifty engineers means fifty scoped tokens; a B2B agent across forty customer accounts means forty. Neither path gives you a vault, rotation logic, or a revocation flow. That infrastructure has to be built separately.
The token type differs; the problem does not
The MCP OAuth flow gives you a token per user. The API path gives you a user token or an account token. In every case the credential needs to live encrypted at rest, isolated per tenant, and revocable when an engineer leaves or a customer churns. A token left valid on a laptop or in a config file after offboarding does not decide to stop working; an agent on a schedule just keeps using it.
Where Scalekit fits
Scalekit's Cloudflare connector handles the credential lifecycle for both paths. It vaults the per-engineer Cloudflare API key, resolves it server-side on every call, scopes the call to that engineer's permissions, and logs it. The MCP vs API decision does not change what you need at the credential layer.
Building a Cloudflare agent with Scalekit
The value proposition for an infrastructure agent
A shared Cloudflare token looks correct in a demo and breaks in production. Every Workers deploy and DNS change then shows up as a service account, attribution is lost, and one leaked credential exposes every account it can reach. Scalekit resolves the real engineer credential on each tool call, so attribution, scope, and audit stay accurate. This is the multi-tenant principle stated plainly: what the user can't do, the agent can't do. Scope is a function of identity, not connector configuration.
Token Vault: credentials never touch the agent
The Cloudflare API key lives in Scalekit's vault, encrypted at rest and namespaced per tenant. Scalekit resolves it at request time, server-side, before each call. The credential never appears in the prompt, the LLM context, or your application logs. The agent calls a tool, gets a result, and never sees a token.
Discovery, scope, then execution
The agent first retrieves the tools the current engineer's connected account is authorized to call, using list_scoped_tools. This is not a flat connector catalog; it is the scoped, deterministic surface for this user. The Cloudflare connector exposes a search tool and an execute tool that mirror the Code Mode model. After discovery, the agent runs a tool with execute_tool, and Scalekit resolves the credential and performs the authenticated call.
A note before any code runs: the connection_name you pass must match the connection name configured in your Scalekit dashboard exactly. This is the single most common integration error. The examples below use cloudflaremcp; confirm the exact connection and tool names in your dashboard before shipping.
Node SDK
Python SDK
Claude (Anthropic)
The agent loop is shown in full: discovery, the model call with the scoped tools, the stop_reason check, the execute_tool call, the tool result construction, and the message append.
LangChain
Wiring it into your coding agent
For an interactive setup, Scalekit's Cloudflare endpoint is available at https://mcp.scalekit.com/cloudflaremcp. In Cursor, add it to ~/.cursor/mcp.json:
In Claude Code, install the AgentKit plugin:
Why this matters downstream for multi-tool, multi-tenant agents
Scoped surfaces, not a flat catalog
A single infrastructure agent often spans Cloudflare, GitHub, and PagerDuty in one workflow: deploy a Worker from a commit, open an incident if the deploy fails. With Scalekit, each connector resolves under the same engineer identity with its own vaulted credential, and list_scoped_tools returns only the surface that engineer is authorized to call. Scope is derived from identity, so the same agent serves a second engineer or a second tenant without new auth code.
One endpoint, per-user isolation
Scalekit's connector gives the agent a scoped, user-specific MCP endpoint. One server definition serves all engineers; before each run, a short-lived token is minted scoped to that engineer's connected account. There is no MCP server for you to deploy, host, or maintain, and no credential sharing between users.
Agent auth logs for observability
Every Cloudflare tool call is logged with who triggered it, which operation ran, and what came back, with 90 days of history tied to the engineer who authorized it and exportable to your SIEM. For a multi-tenant agent making active changes to production infrastructure, that audit trail is the difference between answering an auditor's question and opening a three-week investigation.
When you need a surface that isn't covered yet
If your agent needs a Cloudflare capability the connector does not expose yet, a product-specific server or a data-plane surface, request it. Reach the team in the Scalekit community Slack, through Talk to us, or by booking time with Scalekit's engineers.
Which one to build against
If your agent is an interactive infrastructure assistant and its job is broad account access, deploying Workers, editing DNS, reading observability, the Cloudflare MCP path is the faster route, and Code Mode gives it the full surface through two tools. If your agent needs the R2 object data plane or live log tailing, runs a deterministic pipeline on a pinned API version, or relies on account-token service principals you control, build against the Cloudflare API directly. Most production setups will use both: the assistant on MCP, the pipeline on the API. Either way, the credential management problem is identical, and that is what needs production-grade infrastructure.
Browse the Scalekit Cloudflare connector: scalekit.com/connectors/cloudflaremcp
Read the connector docs: docs.scalekit.com/agentkit/connectors/cloudfaremcp



.webp)