

If you’ve ever built a two-agent workflow, say one that researches a topic and another that writes a summary, you already know the pain points. Context gets lost mid-handoff, retries spiral, and your writer agent ends up paraphrasing half-baked results while the researcher is still fetching sources. What should be a simple “researcher-writer” flow becomes a debugging marathon of missing memory, token bloat, and ungoverned LLM chatter.
That’s where frameworks like LangChain and CrewAI come in. Both promise structured collaboration between multiple agents, but they approach the problem from opposite ends. LangChain gives you composable agent graphs that are flexible and fine-grained, but require explicit orchestration. CrewAI treats agents as autonomous teammates with defined roles and built-in task coordination. On paper, both can solve the same use case. In practice, their ergonomics and control boundaries make all the difference.
This post walks through a real apples-to-apples comparison: we’ll rebuild the same “researcher-writer” pipeline in both LangChain and CrewAI, using identical tools, identical prompts, and identical inputs. Along the way, you’ll see how each framework handles state handoff, per-agent permissions, retries, timeouts, and failure recovery, all the things that separate a clever demo from a reliable production workflow.
Before choosing between LangChain and CrewAI, it’s essential to understand the shared foundation both sit on. Our “researcher-writer” pipeline isn’t about frameworks, it’s about how information flows. Each layer in the stack has one clear responsibility, and together they form a reproducible structure that can be wired up under either framework.
In our story, the researcher agent explores the web, gathering insights, while the writer agent shapes that data into a clean, publishable draft. When this system fails, it’s rarely because of a single bug; it’s because the data, summarization, and orchestration layers aren’t speaking the same language. Let’s make those layers explicit.
The full reference implementation, including both LangChain and CrewAI builds, is available on GitHub so you can clone it, run it locally, and follow the workflow end-to-end.
Each layer handles one part of the chaos we described in the introduction.
To see how both frameworks approach the same problem, visualize their architectures side by side.
Both systems achieve the same goal; the difference lies in how they define task boundaries and transfer state.
LangChain wires these through explicit graph nodes and message passing; CrewAI relies on structured task coordination and implicit context sharing.
In our opening story, this is exactly where things break down: the researcher finishes too early or floods the writer with unfiltered data. The architecture above fixes that by introducing a consistent orchestration model, no matter which framework you pick.
Setting up the environment
Both builds share a single configuration baseline. From your requirements.txt:
And the minimal .env file (shared between LangChain and CrewAI):
This ensures both frameworks use identical tools, APIs, and LLMs, keeping the comparison fair and reproducible.
This shared foundation is the real secret behind reliable multi-agent systems.
Before even touching framework code, defining clear data boundaries, roles, and orchestration rules prevents half the debugging pain that usually follows.
In the next section, we’ll build this exact same workflow inside LangChain, where orchestration is explicit, granular, and powerful, but also verbose and easy to mismanage.
Before your researcher agent can perform a web search, you’ll need to generate a SerpAPI key. SerpAPI provides a Google Search API used by the web_search_tool in this workflow.
You can obtain your key from the SerpAPI dashboard. Once you sign up (a free plan is available), the dashboard shows your unique API key and a sample usage snippet.
The researcher agent reads this value via:
This configuration enables your agent to perform live web research, fetching relevant results and structured metadata directly from Google.
LangChain provides you with full control over reasoning and tool usage. It’s not an “auto-magic” framework; you write the orchestration yourself, message by message. This explicitness is what makes it ideal for testing structured multi-step workflows like our researcher-writer pipeline.
In our scenario, the researcher agent queries the web, fetches the most relevant pages, and synthesizes a factual summary. The writer agent then rewrites those findings into a publishable brief.
From a single call to multi-step reasoning
Your implementation in langchain_mcp.py doesn’t use LangGraph or chain graphs. Instead, it builds an async loop that mimics multi-agent reasoning using ChatOpenAI.bind_tools(), the cleanest possible way to expose structured tools to the model.
This loop serves as the LangChain agent runtime in miniature, orchestrating the full reasoning cycle end to end.
It manages message passing between the LLM and tools, interprets structured tool calls, executes them, captures the results, and feeds the outputs back into the conversation context.
Essentially, it’s the “brains” behind autonomous behavior: the LLM decides what to do next, the runtime executes that decision safely, and the loop continues until a final answer is reached, all under explicit developer control.
Your researcher begins by conducting a structured Google search using SerpAPI, then retrieves and parses the top results.
This pattern avoids relying on long-context models unnecessarily; it passes only essential context downstream.
Once the researcher has raw text, the model synthesizes structured notes directly, no summarizer tool needed.
Your implementation simply prompts the model with system context and content:
By not binding any tools here, you guarantee that the model cannot re-search or fetch again; it’s confined to reasoning within the provided context.
Next, the writer agent reformats the synthesized notes into a clear, publishable Markdown draft.
This keeps reasoning separate from formatting. You’re using the same model instance but re-prompting it with a different persona, achieving modularity without managing agent memory.
The orchestration in your main entry point runs everything end-to-end with simple async coordination and a timeout:
Every step in the LangChain workflow prints clear progress markers (🔍 for research, ✍️ for writing) directly to the terminal, giving developers instant feedback during testing and debugging. The setup stays intentionally lightweight; nothing hides behind abstractions or background orchestration.
Each tool call, response, and retry happens in plain sight, letting developers control exactly how the model reasons and reacts. Every agent runs inside its own reasoning loop, making the flow easy to debug, extend, or cancel mid-run without breaking the rest of the system.
This transparency delivers the control developers often seek in early-stage multi-agent experiments. The trade-off is verbosity explicit orchestration means more code, but it builds reliability and trust. Later, when this workflow transitions to CrewAI, the orchestration becomes cleaner and more declarative, trading a bit of hands-on control for simplicity and speed.
CrewAI emphasizes clarity over control. Instead of managing message loops or tool invocations yourself, you define agents and tasks, and the framework handles the orchestration. For the researcher-writer pipeline, this feels like assembling a small team, one expert gathers information, another crafts it into something readable, with CrewAI acting as the project coordinator.
This approach allows the team to focus on logic and outcomes rather than orchestration details. Where LangChain required manual loops and explicit state handling, CrewAI turns the same collaboration into a declarative, human-readable workflow.
Agents and tasks define the collaboration
In your implementation, each agent is assigned a role, goal, and backstory, effectively mirroring job descriptions. Tasks are tied to these agents, defining their objectives and expected outputs.
This declarative style significantly reduces boilerplate code. CrewAI ensures that tasks always execute in the correct sequence, with the researcher running first and the writer following afterward. This prevents common ordering errors that can occur in manual orchestration loops, such as the writer triggering before the data is ready.
Both agents share the same LLM instance, which is configured once through environment variables. The Crew object encapsulates the agents and their tasks, and a single .kickoff() runs the entire workflow.
This orchestration reads more like a workflow specification than traditional code, making it easier to extend and debug. For development teams, it reduces the number of moving parts to maintain while preserving the same two-stage research pipeline.
Tool integration through structured adapters
You also prepared CrewAI-compatible versions of your shared tools (web_search, fetch_url, and summarize_research) using structured_tool.from_function. This design makes every tool usable both in LangChain and CrewAI with no duplicate logic.
Right now, the agents operate without tools, relying solely on model reasoning. However, these adapters make it effortless to add retrieval and grounding later. When the researcher requires citations or source validation, the tools can be attached directly to the agent definitions without changing the rest of the workflow.
Execution flow matches natural collaboration
When crew.kickoff() runs:
The entire flow mirrors real-world teamwork: it is sequential, explainable, and ready for asynchronous execution, yet it maintains the structure and discipline of a machine-managed run.
CrewAI’s biggest advantage is its simplicity and semantic clarity. While you give up some of the fine-grained state control and visibility that LangChain offers, you gain speed in prototyping and reduce mental overhead. For small, well-scoped multi-agent workflows, CrewAI’s declarative structure often delivers faster iteration and easier debugging.
In this setup, teams can move from experimentation to deployment with minimal friction. The orchestration model ensures predictable execution order and clean agent handoffs, allowing developers to focus on outcome quality instead of coordination mechanics. If later you need advanced features like timeouts, cancellation, or partial retries, the same flow can be extended without major refactoring.
No matter which orchestration layer you prefer, LangChain or CrewAI, both depend on the same foundation of shared, deterministic tools. These tools handle external operations like search, content fetching, and summarization, keeping reasoning cleanly separated from retrieval. This shared layer makes the pipeline modular and framework-agnostic.
In practice, this mirrors how most engineering teams build resilient systems: standardize the logic for I/O operations, then plug it into different orchestration engines or runtimes as needed. The orchestration framework may change, but the intelligence layer, which defines what the workflow actually does, stays consistent.
Web search: structured discovery via SerpAPI
The web_search_tool provides a consistent entry point for external information. It uses SerpAPI to query Google Search and returns a structured list of {title, link, snippet} objects, making it ideal for feeding into an LLM.
Because it’s wrapped with the @tool decorator, it works natively in both LangChain and CrewAI via their respective tool-binding methods.
The design is lightweight and stateless, with built-in error handling for network or key issues. This ensures that both frameworks or any future orchestration system can reuse the same search logic without extra dependencies or hidden state.
URL fetching: readable text extraction
Once URLs are retrieved, the fetch_url_tool extracts readable content from each page using readability-lxml. It filters out boilerplate markup, giving the model only the core article text.
By standardizing this layer, both LangChain’s run_langchain_mcp() and CrewAI’s researcher task can rely on the same deterministic content extraction logic. The capped text length helps maintain performance while avoiding prompt bloat during downstream synthesis.
It’s simple but practical when the workflow runs in a sandboxed environment or during unit testing; this summarizer can replace model-dependent synthesis while preserving predictable behavior.
Decoupling the tool layer from the orchestration framework gives the system:
Separating tools for capability and frameworks for orchestration follows sound engineering principles. When orchestration changes, you only adjust how agents use those tools, not the intelligence behind them.
LangChain and CrewAI both solve the same problem: coordinating specialized agents that share tools and state. However, they differ sharply in how much control they expose. Understanding that difference helps you choose the right framework for the kind of workflow you’re building.
When you look at both side-by-side, the contrast becomes clear: LangChain prioritizes control; CrewAI prioritizes structure.
LangChain: Explicit orchestration for precision
LangChain provides developers with complete control over how agents interact with tools, messages, and one another. In your implementation (run_with_tools), every iteration is handled manually, from when the model invokes a tool to how the response is appended and when the loop terminates.
This fine-grained control makes LangChain a strong choice for teams that value transparency and determinism in multi-agent logic. You decide exactly when and how tools are called, how results are processed, and how retries or fallbacks are handled. It’s ideal for production environments where reliability, debugging, and explicit governance matter as much as outcome accuracy.
Every iteration is fully observable: you can log messages, throttle API calls, add guardrails, or inject safety checks. This is the same approach you’d take when managing non-LLM integrations or when debugging distributed state transitions.
However, this precision comes with overhead. LangChain demands more boilerplate, more code ownership, and a deeper understanding of async control flows. For smaller teams or simpler pipelines, this can feel verbose, but for workflows that must be explainable and fail-safe, that explicitness becomes an asset rather than a burden.
CrewAI approaches orchestration from the opposite direction. Instead of manually wiring message loops and state handling, you describe what should happen, the roles, the goals, and the order of execution, and the framework handles the how.
In your setup, the researcher and writer agents are defined once with their objectives and backstories, while the tasks describe the expected outcomes. The Crew.kickoff() call then orchestrates the flow automatically, assigning the right task to the right agent in sequence. There is no need to manage prompts, retries, or iteration loops directly.
This declarative style fits perfectly for teams that value clarity over control. It turns orchestration into a readable workflow specification rather than a block of procedural logic. Developers can focus on defining responsibilities instead of managing the underlying message flow or state transitions.
The trade-off is visibility. CrewAI abstracts much of what LangChain makes explicit, such as intermediate message states and per-step retries. Yet that abstraction simplifies experimentation and scaling. For quick prototypes or internal research pipelines, it offers a clean, maintainable foundation that still supports deeper customization when needed.
Both frameworks are complementary. Many teams start with CrewAI to explore an idea, then migrate to LangChain when they need deeper control or performance optimization. Because both share the same tool layer, switching doesn’t mean rebuilding, just re-orchestrating.
In a typical multi-agent setup, you’ll often start small: a “researcher-writer” pair. CrewAI lets you model that quickly. But as the workflow matures, maybe you add a “reviewer” or “fact-checker” agent, or start streaming intermediate results, LangChain’s explicit loop becomes more valuable.
That’s where this side-by-side comparison matters: it’s not LangChain vs CrewAI, but LangChain after CrewAI. One’s for prototyping; the other’s for scaling.
As multi-agent frameworks mature, interoperability becomes more important than orchestration speed. Each framework, LangChain and CrewAI, has its own way of defining context and tools. That’s convenient for experimentation, but painful when you want agents to share data or migrate between systems.
The Model Context Protocol (MCP) addresses that problem by introducing a unified way for agents, LLMs, and tools to communicate. Instead of being tied to one SDK’s message format, developers can define tools and contexts once and reuse them across runtimes. It acts like a “standard transport layer” for agent ecosystems, ensuring consistency in how context, memory, and external tool outputs are exchanged.
Even in a small “researcher-writer” setup, three friction points quickly emerge:
MCP solves all three by standardizing how context and tools are declared and invoked. It lets you say, “This is a tool,” once, and any compliant framework knows how to call it.
MCP can be introduced incrementally without restructuring your existing LangChain loop.
Instead of invoking the ChatOpenAI model directly, you initialize an MCP client that manages both model access and contextual state.
Here’s how integration typically looks:
You don’t need to replace your LangChain orchestration immediately; MCP can wrap the LLM call or run parallel to it. This hybrid approach lets you gradually shift state and tool management into a protocol layer without rewriting your research or summarization logic.
CrewAI’s declarative structure makes MCP adoption even simpler. Each agent can be initialized with its own MCP-managed context, allowing for clean state sharing across tasks.
This setup allows both agents to persist and exchange information transparently. For example, research notes stored in the “research-session” context can automatically become visible to the writer agent without manual file passing or dependency on in-memory state.
MCP effectively upgrades your system from a local workflow to a protocol-based architecture, where any compliant agent or model can plug into your ecosystem.
In the current “researcher-writer” pipeline, context is just an in-memory variable. With MCP, that context becomes a shared and inspectable workspace structured, versioned, and accessible across frameworks.
When the researcher synthesizes findings, the writer agent doesn’t just receive text; it inherits context. That means reproducibility, security, and traceability are built in from the start, not bolted on later.
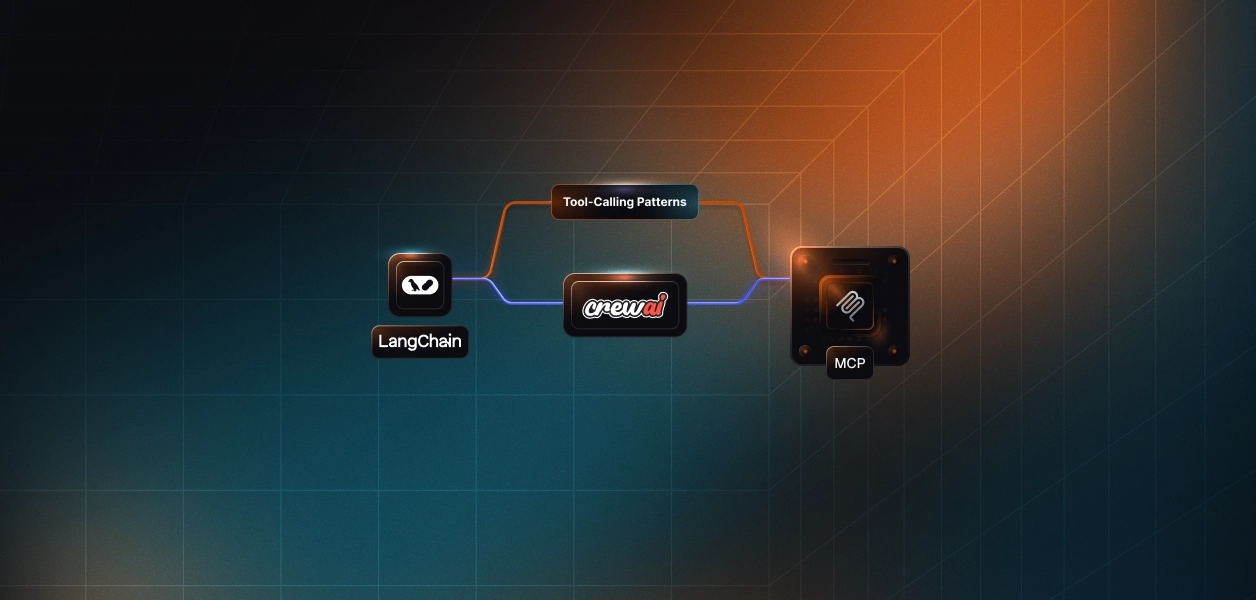
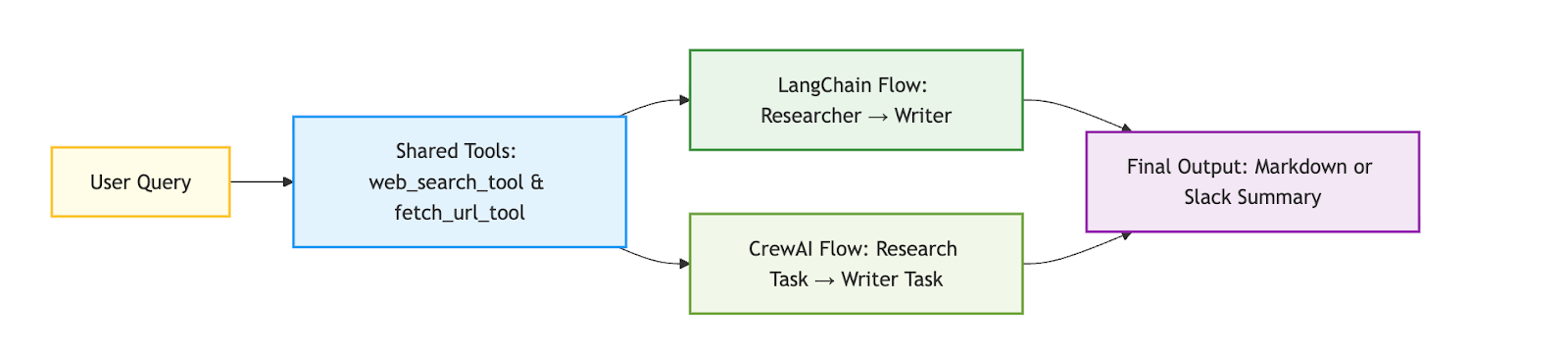
LangChain and CrewAI handle the same “researcher-writer” workflow, showing exactly where shared tools operate, where orchestration differs, and how MCP bridges context between them.
Understanding the control flow is essential when comparing multi-agent frameworks. Both LangChain and CrewAI convert a user’s query into structured insights, but their orchestration philosophies differ: LangChain favors explicit loops and message passing, while CrewAI uses declarative task-based flows.
MCP, when introduced, creates a shared workspace for context, memory, and tool interoperability, standardizing communication between agents and frameworks.
With that overview in mind, here’s how the full process unfolds visually across LangChain, CrewAI, and MCP.
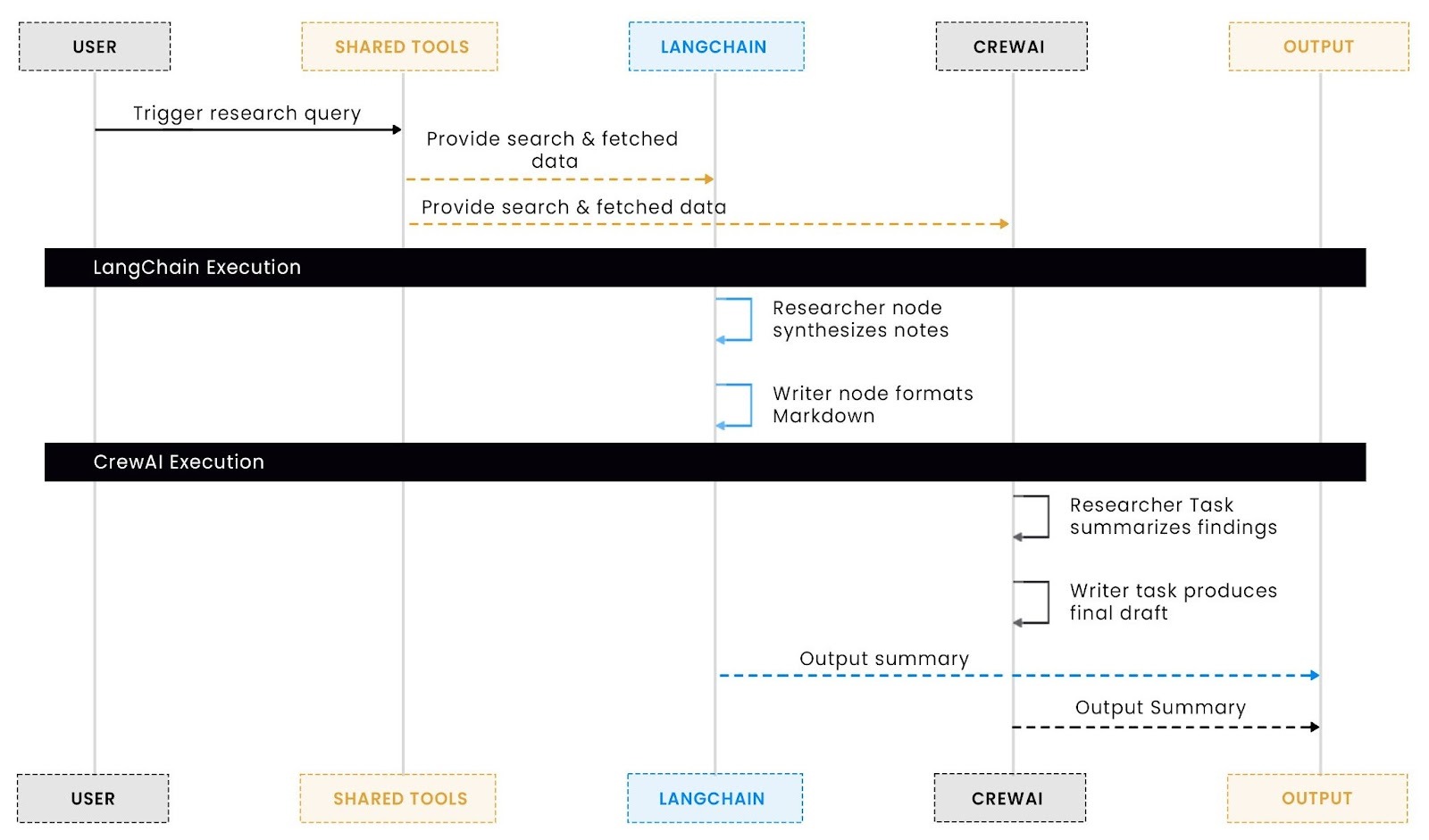
This visualization highlights how both LangChain and CrewAI share the same core tools for research and summarization, yet differ in how they orchestrate them. LangChain offers explicit, step-by-step control that makes debugging and tracing easy, while CrewAI provides a cleaner, declarative workflow that reduces setup complexity. Together, they show that tools remain constant while orchestration evolves, giving developers the freedom to extend workflows, add new agents, or change coordination layers without rewriting the underlying logic.
Now that the full pipeline is mapped, we can meaningfully compare LangChain and CrewAI not as competing tools, but as two orchestration philosophies applied to the same foundation of shared tools and (optionally) MCP.
Both systems successfully run the “researcher-writer” pipeline. The difference lies in how they do it, how predictable they are under load, how easy they are to extend, and what kind of developer experience they provide during iteration and debugging.
LangChain gives you low-level control of execution every loop, tool call, and retry can be inspected or instrumented. In your run_with_tools() function, each tool call is explicit:
This makes it easy to optimize or cache specific calls (for example, caching web_search_tool.invoke() results during retries), but it also means you carry the orchestration cost yourself.
LangChain performs best when the number of steps is small and predictable, ideal for pipelines where logic transparency outweighs automation overhead.
CrewAI, on the other hand, treats orchestration as declarative. You define agents and tasks once, and the engine coordinates dependencies for you:
This abstraction is lightweight for simple two-agent chains but can scale across multiple agents without manual coordination logic. CrewAI handles the sequencing internally, so performance consistency improves when tasks scale horizontally (e.g., adding “fact-checker” or “reviewer” agents).
In short:
LangChain: More granular control, slightly higher orchestration overhead.
CrewAI: Less manual control, but optimized for smooth scaling across tasks.
Both pipelines ultimately achieve the same goal, turning a query into a polished research summary, but the way they operate at runtime differs significantly.
LangChain executes each phase sequentially inside an explicit async loop, giving you direct control over message flow, retries, and tool execution. This design ensures full transparency and granular debugging, but it introduces more I/O overhead since each step waits for completion before proceeding.
CrewAI, in contrast, abstracts orchestration into a single managed runtime. Agents run as independent tasks coordinated by the Crew, which schedules and manages their handoffs automatically. This makes the workflow faster to initialize and easier to parallelize, especially when extending to more agents or larger research scopes.
In short, LangChain optimizes for controlled precision, while CrewAI emphasizes runtime smoothness and throughput, two distinct but complementary strengths depending on your deployment context.
LangChain: Ideal for developers who prefer transparency and want to see inside every loop iteration. Its run_with_tools() loop acts like a controllable sandbox, great for debugging tool calls, retries, and partial failures.
CrewAI: Designed for rapid prototyping. Defining tasks declaratively reduces boilerplate and keeps the workflow visually clean. However, less visibility means more reliance on structured logging or the framework’s introspection tools.
Both LangChain and CrewAI solve the same problem, just at different layers of abstraction.
LangChain is like writing your own orchestration loop in Python; CrewAI feels like defining a YAML pipeline that just runs.
With MCP as a shared bridge, you can even run both side-by-side LangChain for precision-critical stages and CrewAI for flexible task management. In essence, your tools stay fixed, your orchestration becomes modular, and your development workflow remains fluid.
We began with a simple goal: converting a single research query into a structured, publishable summary. Through this process, we saw how LangChain and CrewAI approach the same objective with different philosophies. LangChain offers explicit, fine-grained control suited for deterministic orchestration, while CrewAI emphasizes speed and readability through declarative task coordination. Together, they highlight the spectrum between control and simplicity that defines modern multi-agent systems.
Build on shared tools to stay framework-agnostic
Designing your tool layer independently of any orchestration engine ensures long-term flexibility. In our example, both LangChain and CrewAI reused the same web_search_tool and fetch_url_tool without modification. This architecture allows developers to iterate locally, test consistently, and deploy seamlessly across frameworks without rewriting logic or revalidating APIs.
Use orchestration only when it adds real value
Not every workflow requires multiple agents or complex coordination. For predictable, single-output tasks, a straightforward LLM call or lightweight summarizer can be faster and easier to maintain. Introduce orchestration only when you need parallel reasoning, state handoffs, or structured role specialization. This approach avoids unnecessary complexity and keeps your pipelines efficient.
Optimize for developer velocity, not just abstraction
CrewAI’s declarative model simplifies setup and speeds up experimentation, while LangChain’s transparent loops make debugging and iteration more controlled. The most effective development flow combines both prototypes in CrewAI to validate concepts quickly, then moves to LangChain when you need production-grade observability, retry logic, and explicit state control.
Treat orchestration as a replaceable layer, not a fixed foundation
Frameworks will evolve, but your agents and tools should remain reusable across them. By keeping orchestration logic modular and isolated, you can transition from LangChain to CrewAI (or future frameworks) without major rewrites. Think of orchestration as the delivery mechanism, not the source of intelligence, allowing you to experiment freely without breaking your workflow’s core functionality.
Maintain clean separation of concerns for scalability
Each part of your system should have a distinct responsibility: tools perform actions, agents make reasoning decisions, and frameworks manage coordination. Preserving these boundaries keeps your architecture flexible and reduces coupling between layers. As your system grows, this separation ensures that scaling, debugging, and future integrations remain smooth and predictable.
The “researcher-writer” pipeline showed how two frameworks can solve the same multi-agent problem through different philosophies.
LangChain offers precision; every message, loop, and tool call is visible, giving developers full control over orchestration. CrewAI, on the other hand, prioritizes simplicity and speed. Agents and tasks are declared once, and the system handles sequencing and context.
By layering shared tools (for search, fetching, and summarization) on top of either framework, you get consistency without lock-in. The result is a composable architecture where agents can reason, collaborate, and hand off work predictably with or without an orchestration engine watching over them.
This workflow doesn’t just automate research and writing; it turns a human process into a transparent, inspectable system that’s easy to debug, scale, and extend. With this structure, developers move from manual experimentation to repeatable, production-ready pipelines that still feel understandable.
How does Scalekit simplify integration across frameworks like LangChain and CrewAI?
Scalekit provides a unified schema layer for tools and agents. It ensures consistent authentication, logging, and validation so that the same tool function can be reused across multiple orchestration frameworks. You write once, and it runs anywhere locally, in CrewAI, or under LangChain without changing your logic or configuration.
Can this multi-agent setup scale to more complex workflows?
Yes. Both LangChain and CrewAI are modular. You can add new agents such as reviewers, planners, or reporters. Since tools remain stateless and framework-agnostic, each addition requires only minimal orchestration changes.
When should a team choose LangChain over CrewAI?
If you need fine-grained visibility controlling every iteration, tool call, and state transition, LangChain is ideal. It gives you hands-on orchestration suitable for debugging and deterministic execution. CrewAI, in contrast, suits teams that want clean task definitions and faster experimentation without managing message loops.
How do shared tools improve consistency between frameworks?
Shared tools built with structured adapters allow both LangChain and CrewAI to call the same underlying functions for search, fetch, and summarization. This eliminates duplication and ensures that your research output remains identical regardless of the orchestration engine.
How can developers extend this base workflow?
You can plug in additional agents, switch orchestration frameworks, or move to event-driven execution (such as Slack-triggered runs). Because the intelligence layer (tools and logic) is framework-independent, the workflow can evolve without breaking.