

You have 50 REST endpoints. Now what?
You’re staring at a REST API with over 50 endpoints. It powers an internal productivity platform used by multiple teams, with features like projects, tasks, comments, user roles, notifications, and access control. The API was built incrementally over time, and now it’s your job to expose this entire system as a clean, composable set of MCP tools.
Not just wrap it, restructure it. You need to turn these endpoints into schema-driven, agent-compatible tools that can be composed, reasoned about, and reused across automations, no-code interfaces, or AI agents. That means mapping inputs and outputs cleanly, handling edge cases like batch updates and file uploads, and preserving auth and error behavior, all while keeping the tool layer maintainable over time.
This guide walks through that process end-to-end. You’ll learn how to analyze an existing REST API, map endpoints into MCP tools, reshape schemas, handle real-world edge cases, and implement the full tool layer with testable, maintainable code. We’ve built a realistic sample project, a minimal productivity tool API, designed to reflect common DevEx patterns like user management, task flows, and permissions. Every pattern and implementation shown here is grounded in this working example, not toy snippets.
You have an internal REST API that evolved over time, spanning users, tasks, roles, comments, and access control. Over time, it has expanded into over 50 REST endpoints that are now embedded into internal tooling and workflows. The task now is to expose this API as a structured layer of MCP tools, not just as wrappers, but as clean, composable, schema-driven capabilities that agents and orchestrators can safely use.
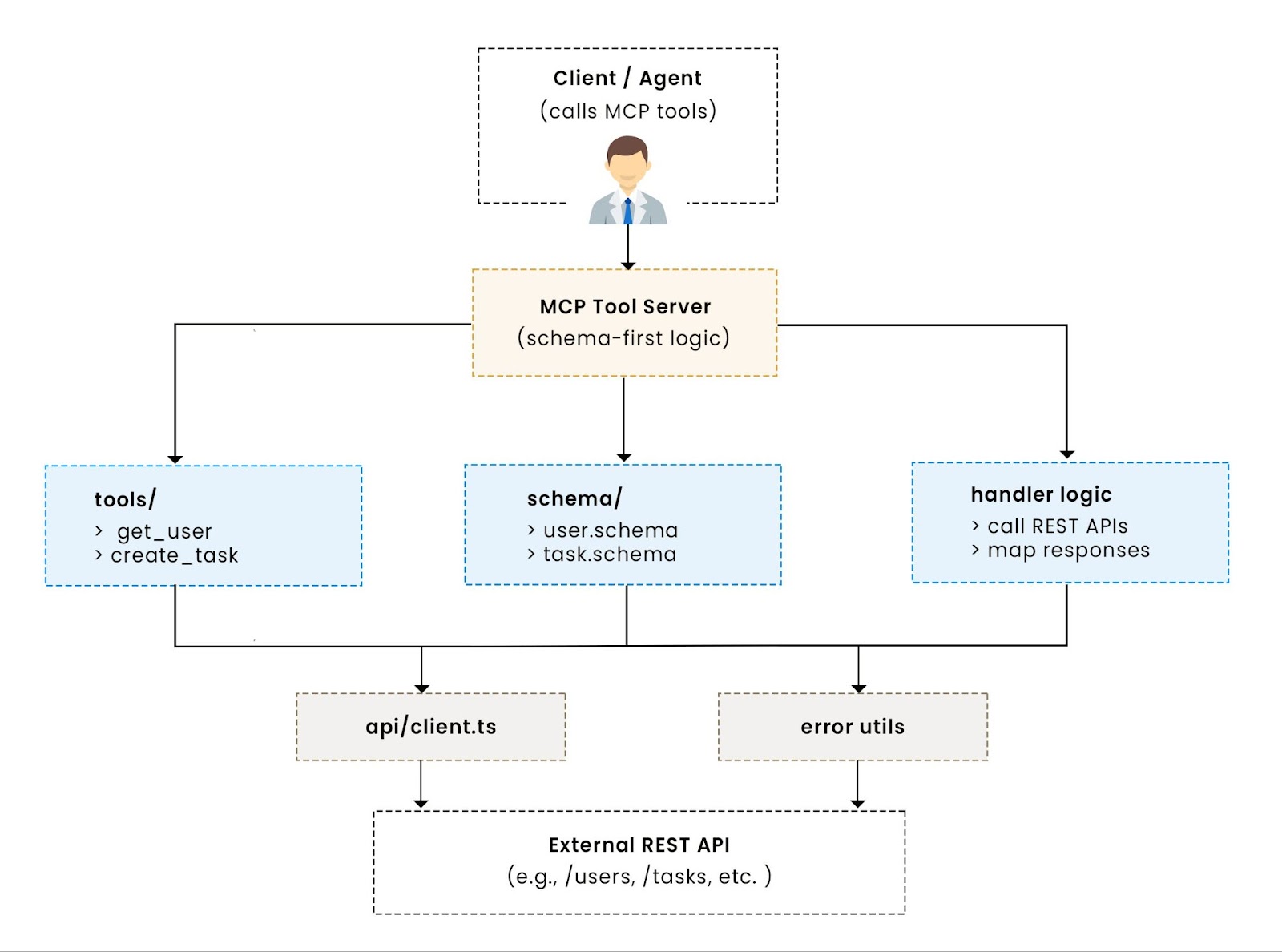
This transformation isn’t mechanical. REST endpoints organize behavior around HTTP verbs and paths. MCP tools organize around named actions with structured inputs and predictable outputs. This shift turns low-level HTTP behavior into agent-compatible, schema-defined actions. If you’re layering MCP on top of an existing service, see wrap MCP around an existing API for design patterns before you start mapping.
Start by categorizing the API into logical domains such as users, tasks, comments, roles, and projects. Then, for each domain, identify the kinds of operations exposed: fetching individual records, listing collections, creating new entities, updating fields, or deleting records.
For example:
This early classification sets the foundation for tool naming (e.g., get_user, list_projects) and reveals shared object types (e.g., User, ProjectSummary) that can be extracted into common schemas. It also helps flag atypical endpoints early, such as file uploads, batch operations, or nested workflows that will need special treatment in later stages.
Every MCP tool corresponds to a single, self-contained capability. It does not directly mirror an HTTP method or route. Instead, each tool expresses its purpose in code and metadata, allowing it to be discovered, composed, and executed independently.
Each tool definition includes:
Tools may be grouped internally by resource, for example, user-tools.ts or task-tools.ts; however, this grouping is for maintainability purposes and is not part of the MCP runtime. The interface exposed to agents is flat and action-oriented.
Most teams begin with an OpenAPI specification. This is a solid foundation, but to create MCP tools, you’ll need to transform that spec into agent-friendly schemas.
Here’s a typical example:
From OpenAPI:
Becomes MCP tool:
During this transformation:
This step ensures that each tool’s inputs and outputs are self-documenting and ready for chaining or reuse in automated flows.
The most powerful tool layers aren’t those that expose every endpoint; they’re the ones that developers and agents can predict without reading the docs. That means prioritizing consistency across the entire tool surface.
Follow these principles:
MCP tools are meant to be long-lived interfaces. They should feel predictable and interchangeable. If someone understands get_user, they should already have a good idea of what get_project or get_task will look like.
Once your API is grouped by resource, the next step is to convert each endpoint into a single-purpose MCP tool. This isn’t a renaming exercise. Each tool should model a meaningful capability that can be reused across agents, automation flows, and developer UIs.
In this section, we’ll cover the common patterns:
We’ll focus on the cases where tool structure meaningfully differs. For similar patterns, we’ll show one and describe the rest.
Most internal APIs expose standard Create, Read, Update, and Delete (CRUD) operations across resources, such as users, tasks, or projects. Each operation is mapped directly to a single tool, following a predictable structure.
This is the foundational pattern. A path parameter becomes an input field. The response body becomes the output schema. Once your definitions are in place, follow tool calling to wire the request and response flow and return typed results.
The same pattern applies to other entities, such as get_task, get_project, and get_comment, among others. Only the field names and output structure change.
List tools expose pagination and filters directly in the input schema. Avoid hardcoded defaults or undocumented query logic.
This structure is reusable for any resource collection, such as list_tasks, list_projects, etc.
Create tools that use request body fields as input and return either the created object or its ID.
Other tools like create_task or create_project follow the same structure, with different fields and validations.
Update tools follow the same pattern as create tools, but all fields are optional. The target ID is passed explicitly.
This pattern applies to any partial update, such as update_task or update_project_settings.
Deletion tools are similar to read-by-ID tools but may include additional flags. For example, if both soft and hard deletes are supported:
This avoids surprises and gives agents full control over deletion behavior.
Internal developer tools often involve more complex workflows, such as filtering across fields, handling multiple objects simultaneously, or processing binary data. These patterns still map cleanly into tools with the right schema structure.
If filtering logic is more complex than simple lists, model filters as first-class input fields.
Tools like search_comments or search_projects can follow this format with adjusted fields.
Bulk tools require array inputs and must define how partial errors are handled, either by rejecting the entire batch or returning results for each item.
This pattern also applies to bulk updates or deletes; just adapt the item shape and handler behavior.
Because tools can't transmit binary data directly, the standard pattern is to return a signed upload or download URL.
Upload:
Download:
This decouples binary transfer from core logic and works well with cloud storage integrations.
Login and token refresh are stateless tools. They take credentials as input and return tokens, refresh tokens, and expiry timestamps in the output schema.
Most internal APIs come with OpenAPI specs, a helpful starting point. But OpenAPI is designed around HTTP routes, not schema-driven capabilities. MCP tools require tighter specifications: flattened inputs, explicit types, consistent output structures, and error behavior that’s machine-readable. If you are defining your first tool, start with the tools overview to see how names, parameters, and results are structured.
This section guides you through reshaping OpenAPI specs into fully defined MCP schemas, without leaking HTTP concepts or relying on implicit assumptions.
Let’s start with a basic OpenAPI operation:
This becomes a tool like:
Notice the key changes:
This flattening step makes tools easier to compose, test, and validate, both by humans and agents.
OpenAPI uses JSON Schema internally, but often omits critical details. For MCP tools, those gaps must be closed explicitly.
Optional fields: Make field optionality explicit. Use optional: true flags or required arrays to avoid ambiguity.
Enums: Preserve enums directly. They help agents and UIs expose valid values predictably.
For nested structures, such as a list of tasks in a project, define full schemas that include required fields, array constraints, and nested validations. Avoid loosely typed object blobs.
Tool outputs should be direct objects, not nested under response codes. Just define the outputSchema as a flat object with typed fields like projectId or createdAt.
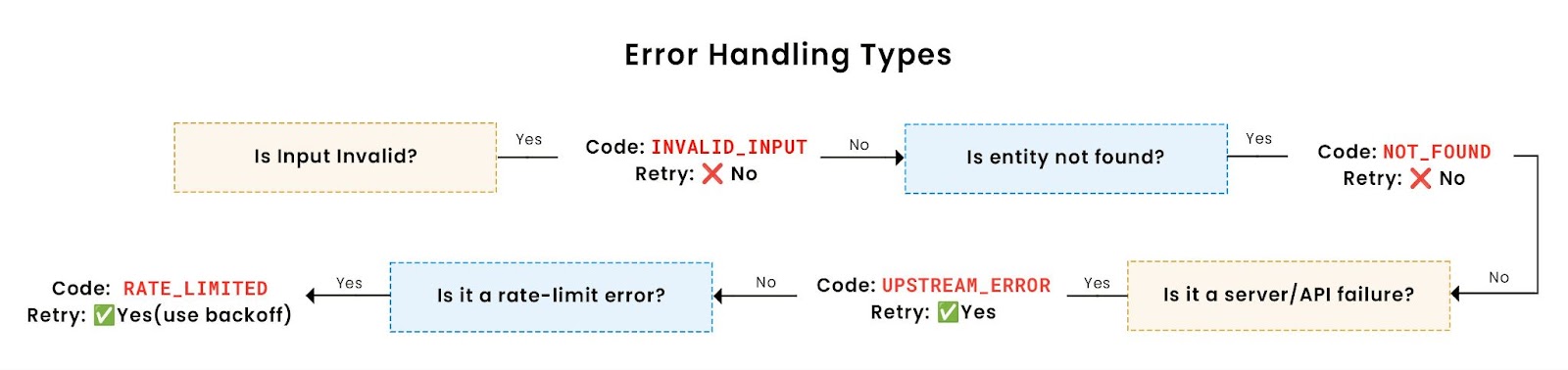
Errors should be structured: include a code, message, and optionally a retryable flag. Avoid leaking raw exceptions or HTTP codes. Common error codes include: NOT_FOUND, INVALID_INPUT, UNAUTHORIZED, RATE_LIMITED. Here’s a standardized breakdown of common error types and how to handle them:
Declare pagination fields directly in tool schemas. Use offset/limit or nextCursor depending on the model your API supports. Always expose the pagination structure in both input and output.
Only include metadata fields like version or modifiedAt when they affect how downstream systems process the response. Don’t expose low-level HTTP headers unless they’re meaningful to tool consumers.
Each tool should now have the following.
This structure makes tools consistent, testable, and composable, and avoids surprises when used in workflows, no-code apps, or AI agents.
In an internal developer platform, many operations span multiple steps. Creating a task might involve validating user permissions, checking project membership, and notifying assignees. Assigning a role could trigger multiple policy updates. These aren’t edge cases, they’re the norm in real systems.
This section covers how to represent multi-step workflows, stateful sessions, authentication, and external constraints, such as rate limits, using MCP tools. You’ll see how to model these patterns cleanly while keeping tools stateless, predictable, and easy to test.
Learn more - Wrap MCP Around Existing API
There are two ways to handle operations that require multiple API calls.
For session-based APIs, accept tokens in the inputSchema and validate them explicitly. Stateless design means no assumptions about prior calls.
Treat authentication as just another tool authenticate_user and refresh_session_token. They return tokens and expiry values, and all other tools should accept these tokens explicitly. All other tools that require auth should accept the token as input. Never rely on global state or headers.
Raise a structured RATE_LIMITED error when hit by 429s, optionally including retryAfterMs for callers to handle gracefully.
For safe, idempotent tools, you can add backoff-and-retry logic in the handler. Avoid retries for tools that mutate state unless your backend supports deduplication.
Queue-backed tools should return an exportId and status like queued. Pair them with a status-checking tool like get_export_status.
Apply access control at the tool level. Validate roles explicitly using the provided token, and raise FORBIDDEN errors for unauthorized actions. Do not assume upstream access control will always catch this. Tool boundaries are the last guardrail, and the most visible to the consumer.
By handling sessions, retries, flows, and auth explicitly, your tools become robust under real-world usage, not just in ideal test cases. These patterns also make tools easier to monitor and extend later, which we’ll cover next in the implementation and deployment walkthrough.
You’ve now mapped your internal API into a clean set of MCP tools. But schema design is only half the picture. You still need a reliable, testable codebase that actually implements those tools. This section walks through a real project built around an internal developer platform, using real tools like get_user, create_project, and list_tasks, to show how to structure, register, and execute MCP tools cleanly. You can try out the full project at mcp-api-demo.
Project uses modular structure with shared schemas and mock backend: The codebase follows a simple modular layout to keep schemas, logic, and mocks separated:
This structure mirrors your API domain (users, tasks, projects) while keeping tool handlers decoupled and composable.
Each tool defines a single action, using inputSchema, outputSchema, and a stateless handler. Here’s a real example from your project:
The get_user tool looks like this:
The create_user tool is defined similarly:
Validation uses shared Zod schemas from schemas/shared.ts.
The server.ts file simply imports all defined tools and logs them for confirmation:
This keeps tools modular; add new tools without changing infra.
Your project uses mockDB, an in-memory object store, to simulate users, tasks, and projects:
Because all tool handlers are stateless and side-effect free, this backend makes it easy to test behavior without depending on external systems.
Rather than redefining every field inline, shared schemas handle validation and normalization:
For example, both create_project and create_user derive inputs from these schemas using .pick() or .omit().
Tool handlers are pure functions, with no state and no side effects, making them easy to test and run anywhere.
Even tools like create_project, which perform validation and aggregation, follow this pattern:
Errors are consistent, data is deterministic, and the output can be trusted. This project powers every example in this guide, from auth to error handling. In the next section, we’ll test these tools for correctness and reliability.
A well-defined MCP tool is only reliable if its implementation is thoroughly tested. Since tools expose structured interfaces, with defined schemas, error codes, and deterministic behavior, they lend themselves naturally to unit and integration testing.
Tests are written using Vitest, with full coverage for logic, schemas, and error behavior.
Each tool has an associated unit test that verifies:
For example, here’s your test for get_user:
These tests confirm not only that the handler works, but that the error behavior is structured and machine-readable.
Schema validation is enforced via Zod. For example, create_user throws on duplicate emails:
This ensures invalid data doesn’t leak into the system, even if the caller uses the tool incorrectly.
Tests reset the in-memory mock database before each run:
This ensures a clean slate for every test case, eliminating the need to mock network calls or spin up external services. It also enables fast and deterministic test execution.
Each case ensures the tool is safe under invalid input and edge scenarios, a requirement if agents or non-developers will consume the tool.
Your handler-level tests can be extended to simulate full workflows. For example:
This kind of flow testing ensures schema compatibility and flow correctness across tools.
Regression tests prevent schema drift, field renames, error changes, or structural mismatches. Snapshotting outputs or linting schemas can catch changes early in CI pipelines.
MCP tools are contracts. Testing their behavior under all conditions keeps your system reliable and safe to evolve. In the next section, we’ll cover how to move these tools into production with confidence, including deployment models, scaling, and observability.
Your MCP tool layer is schema-driven, stateless, and testable, which means deployment doesn’t need to be complex. But it does need to be reliable.
This section demonstrates how to deploy your tools using lightweight patterns (such as containers or serverless functions), configure environments cleanly, and monitor tool health in production. You’ll also see how to catch errors, spot performance issues, and keep tools behaving consistently over time.
You can deploy tools using three main patterns:
Separate environments may require:
Use .env files to inject API base URLs, secrets, or feature flags into runtime. Tools should never hardcode environment-specific logic.
Wrap each tool execution with logs for start, success, and error. Log arguments, results, and duration using a structured logger like Pino or Winston.
This provides:
You can also enrich logs with:
Use a structured logger like Pino, Winston, or Bunyan for log aggregation.
Whether humans, agents, or systems use tools, they need to be observable. Key metrics to collect include:
Set up basic alerts to catch production issues quickly:
You can also log unrecognized error shapes or retryable failures to catch regressions early.
For tools that involve multiple steps or upstream API calls, add distributed tracing with OpenTelemetry or Datadog. Wrap handler internals with spans like validate_user, lookup_tasks, or persist_project to diagnose latency or failures.
Use CI to test handlers, validate schemas, lint tool names, and ensure no tool is missing a schema or description before deployment. With these patterns in place, your tools are safe to deploy, monitor, and evolve whether powering workflows, UIs, or autonomous agents.
In the final section, we’ll examine how to evolve tools safely over time, including versioning schemas, migrating changes, and maintaining stable long-term interfaces.
Once deployed, MCP tools become part of larger systems, internal orchestrators, automation flows, or agent toolchains. This means you can't safely rename inputs, change outputs, or remove fields without careful planning. Even a small schema tweak can silently break downstream consumers.
The diagram below summarizes the full lifecycle of a typical MCP tool from initial release to eventual deprecation or removal:

This section explains how to evolve your tool layer without introducing regressions. It covers versioning, schema strategy, safe deprecation, and performance optimizations, all drawn from how internal developer APIs typically evolve in production.
Tool schemas are contracts. Even adding an optional field can impact behavior for agents, tests, and downstream tooling. Adopt semantic versioning to communicate the risk and scope of changes.
For breaking changes, prefer defining a new tool (create_user_v2) instead of modifying the original. This protects consumers who depend on stable behavior.
A schema that evolves well does not assume too much up front.
These habits make it easier to grow your tool layer without major rewrites.
When a tool becomes obsolete, for example, if create_user is replaced by a more robust version, don’t remove it immediately. Instead:
Many systems may still depend on older tools. Removing them too quickly can break orchestrations and lead to runtime failures. If you do plan to remove a deprecated tool, communicate clearly and version your tool server accordingly.
Even when inputs and outputs don’t change, the tool’s internals can evolve to improve performance. Do so cautiously, ensuring behavior remains consistent.
Common optimizations:
Always measure tool performance before and after the change to ensure the desired result. Keep schema outputs and error behavior identical to avoid unintentional regressions.
MCP tools are designed to be reusable and context-independent. Avoid introducing hidden state or memory leaks.
This ensures tools behave predictably when reused by different agents, workflows, or automation layers.
In this guide, we walked through how to turn an existing REST API into a maintainable MCP tool layer. You saw how to group endpoints by intent, reshape OpenAPI schemas into clean inputs and outputs, and model common patterns like batching, filtering, auth, and error handling, all grounded in working code.
This structure isn’t just about naming or abstraction. MCP tools act as a long-term contract between your backend and anything built on top, agents, orchestrators, no-code platforms, or custom UIs. A clean tool layer makes those systems safer, faster, and easier to extend.
If you already have a Node project with tool definitions, the next step is to expose them to MCP Hosts. That means either deploying your tool registry as an HTTP server or bundling it into a runtime that the MCP ecosystem can call. You can use the example project in this guide as a starting point, fork it, extend it, and adapt it to your needs.
Shared validation logic (like email format, date ranges, or user ID checks) should be encapsulated in reusable schema definitions or helper functions. Use a schema library like Zod or Joi to define common objects (User, Project, TaskInput), and import these into each tool’s inputSchema or outputSchema. This ensures consistency across tools and reduces the risk of divergence as your API evolves.
Avoid global auth middleware. Instead, make authentication explicit in each tool by accepting tokens or user context in the inputSchema. Inside the handler, verify the token and enforce permission checks locally. This ensures tools remain stateless, testable, and secure even when reused in different contexts (e.g., agent runtime, no-code flow, backend orchestration).
Before optimizing any tool handler, write regression tests that validate outputs under known inputs. Use benchmarking to measure execution time before and after changes. If you introduce caching, lazy loading, or batching, make sure that outputs and error behavior remain identical. Also, consider instrumenting each tool with timing logs or Prometheus metrics to detect regressions early in CI or staging.
Use a layered testing strategy:
Mock any external dependencies (DB, APIs) to keep tests fast and deterministic. Reset state between tests to ensure independence.
Wrap external calls with retry logic and circuit breakers where safe (e.g., for idempotent GETs). Structure errors using a predictable format include a code, message, and optionally retryable or retryAfterMs. Avoid leaking raw HTTP or exception traces. If an upstream service is down, tools should fail gracefully and return actionable error messages so orchestrators or agents can respond intelligently.
Ready to turn your REST APIs into composable, agent-friendly tools? Sign up for a Free Forever account with Scalekit and start exposing your endpoints as MCP tools with full auth, error handling and schema flattening. Want help designing tool schemas or mapping complex APIs? Book time with our auth experts.




