Single source of identity: Scalekit proves identity (OTP/magic link). Firebase trusts that proof via custom tokens; no duplicate auth.
Server-minted trust: Backend mints admin.auth().createCustomToken(uid, claims) and the client uses signInWithCustomToken for Firestore/Functions.
Tight data plane: Firestore stores only app data (uid, email, roles, lastLogin). Security rules gate per-user access and admin surfaces via claims.
Automated glue: Cloud Functions upsert users, enrich profiles, and emit analytics on login, keeping handlers small and idempotent.
Production posture: Analytics, rate limits, CSRF/origin checks, and cost levers (client TTL, composite indexes, lean Functions) keep it fast and cheap.
A startup struggling with login complexity
Developers often set up Firebase projects quickly during a proof-of-concept, only to regret the shortcuts when the app goes live. A Firestore instance ends up in test mode, rules are left permissive, and authentication is enabled twice, once in Firebase, once in a custom service. Later, when they try to add passwordless login through a provider like Scalekit, everything collides: overlapping auth flows, mismatched user IDs, and a messy migration path.
The real challenge isn’t that Firebase can’t support secure apps; it’s that the default setup encourages mixing identity and data when they should remain separate. Firebase Authentication is opinionated about providers, but passwordless-first projects need flexibility. Without planning, you end up fighting Firebase instead of leveraging its strengths.
The fix is to treat Firebase as the data and enforcement layer while Scalekit becomes the identity layer. Scalekit verifies users with OTPs or magic links, and your backend issues Firebase custom tokens that Firestore, Functions, and Analytics trust. In this section, you’ll see how to set up Firebase with the proper defaults: a new project configured for Firestore, Functions, and Analytics, no redundant auth, and service accounts ready for secure token minting.
Firebase setup checklist for Scalekit integration
Before integrating Scalekit, your Firebase project should be configured to act purely as the data and enforcement layer. The goal is to prepare Firestore, Functions, and Analytics while leaving identity verification to Scalekit.
Create a Firebase project + web app: In the Firebase Console, create a new project and register your frontend app. Copy the generated client config; you’ll need it later to initialize Firebase on the client.
Enable only the required service: Turn on Firestore, Cloud Functions, and Analytics. Keep Firebase Authentication methods (Email/Password, Email Link) disabled, Scalekit will own identity verification, and Firebase will only trust custom tokens.
Create a Service Account for backend trust: From the Console, generate a Service Account key with Editor or Auth Admin privileges. Download the JSON credentials and point your backend to them using the GOOGLE_APPLICATION_CREDENTIALS environment variable.
Initialize the Firebase admin SDK once
To avoid memory leaks and cold-start penalties, initialize the Admin SDK as a singleton:
import admin from 'firebase-admin';
if (!admin.apps.length) {
admin.initializeApp({
credential: admin.credential.applicationDefault(),
});
}
export { admin };
Set environment variables for Scalekit + Firebase glue
These should be stored in .env or your deployment platform’s secret manager:
SCALEKIT_ENV_URL
SCALEKIT_CLIENT_ID
SCALEKIT_CLIENT_SECRET
SESSION_SECRET
With this foundation, Firebase is ready to accept custom tokens generated after Scalekit verifies identity. This separation keeps the trust boundary clean: Scalekit proves identity, Firebase enforces access.
End-to-end trust: Scalekit handles verification, backend mints a token, and Firebase establishes the session.
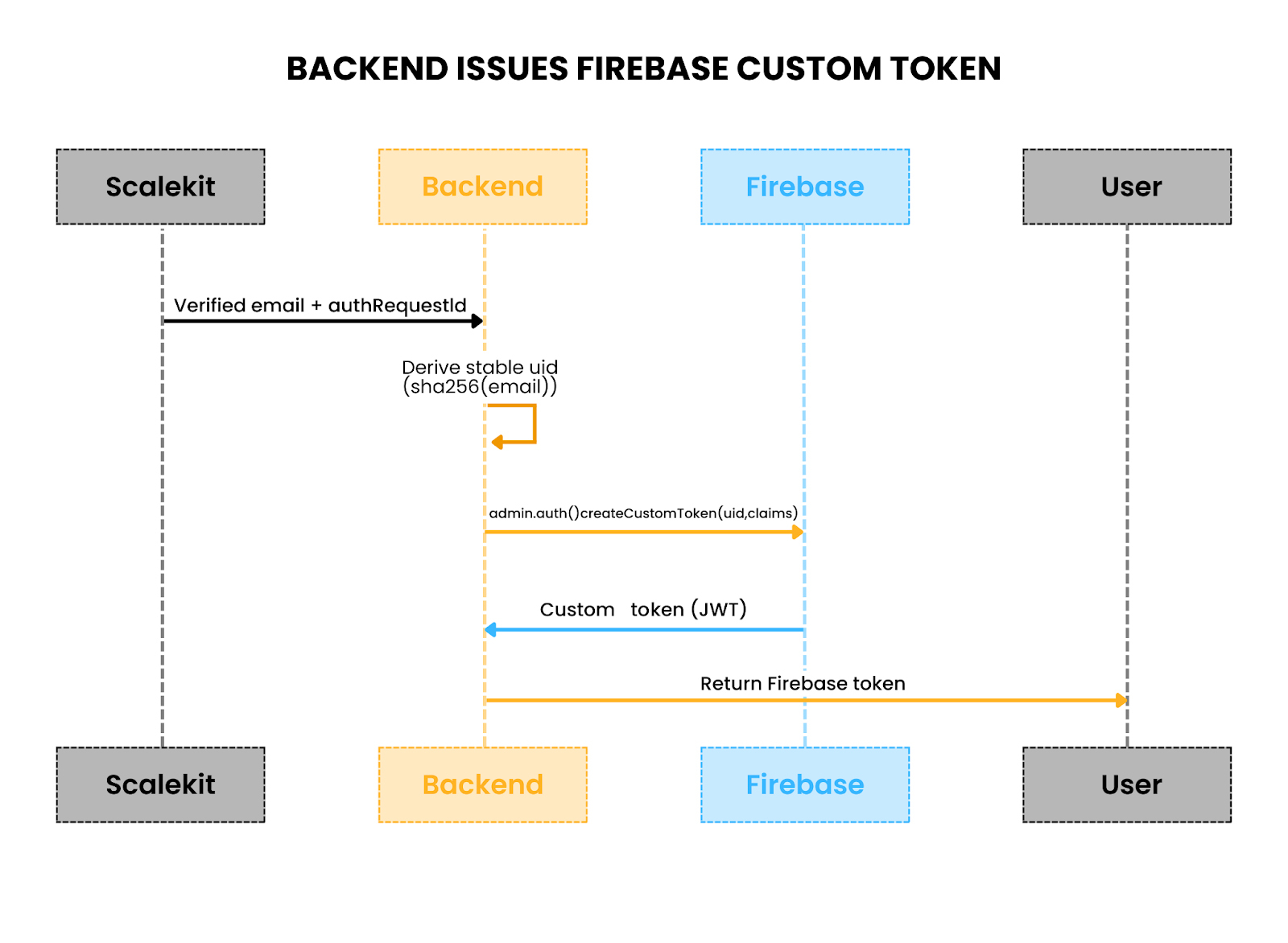
Custom token generation for Scalekit-verified users in Firebase
When Scalekit verifies a user through an OTP or magic link, you get back proof of identity: typically the user’s email, request ID, and verification metadata. That by itself isn’t enough for Firebase. Firestore, Functions, and Storage all rely on Firebase sessions, and those sessions are only established if the client signs in with a recognized credential. Pushing Scalekit’s user IDs straight into Firestore won’t trigger Firebase Security Rules, because Firebase doesn’t know how to trust them.
The way to bridge this gap is with Firebase custom tokens. These are short-lived JWTs that your backend mints with the Firebase Admin SDK. They act as a signed statement: “I, the server holding valid Firebase credentials, confirm this uid is trusted.” Once the frontend exchanges the token using signInWithCustomToken, Firebase creates a full session. From that point on, every request to Firestore or Functions carries an authenticated request.auth object.
Deriving a stable uid
Every Firebase user must have a stable identifier. If you simply use raw emails, you risk collisions if the user changes their email address. A safer approach is to generate a deterministic uid, such as:
import crypto from 'crypto';
function stableUidFromEmail(email: string) {
return crypto.createHash('sha256').update(email.toLowerCase()).digest('hex');
}
This guarantees that the same user always maps to the same Firebase uid, and it’s collision-resistant.
Minting the token server-side
Once you’ve verified the user with Scalekit, mint the custom token:
claims: optional extra data, such as roles: ['admin'] or tenant: 'acme'. Keep claims coarse-grained, fast-changing flags should live in Firestore, not in tokens.
The frontend uses Firebase Auth to complete the login:
import { getAuth, signInWithCustomToken } from 'firebase/auth';
async function completeLogin(firebaseToken: string) {
const auth = getAuth();
const cred = await signInWithCustomToken(auth, firebaseToken);
console.log('Signed in as:', cred.user.uid);
}
After this, any call to Firestore or Functions automatically includes the session, so your Security Rules apply as if the user had signed in through Firebase directly.
Why this pattern matters
No duplicate identity: Scalekit proves identity, Firebase enforces it, no separate auth tables.
Rules apply everywhere: Firestore rules, Storage rules, and Functions all trust the session.
Extensible: Claims let you gate admin-only routes or tenant access without extra DB lookups.
This token generation step is what makes Scalekit and Firebase work together as a clean, single pipeline: Scalekit owns verification, Firebase owns enforcement.
Cloud functions integration for automated post-login workflows
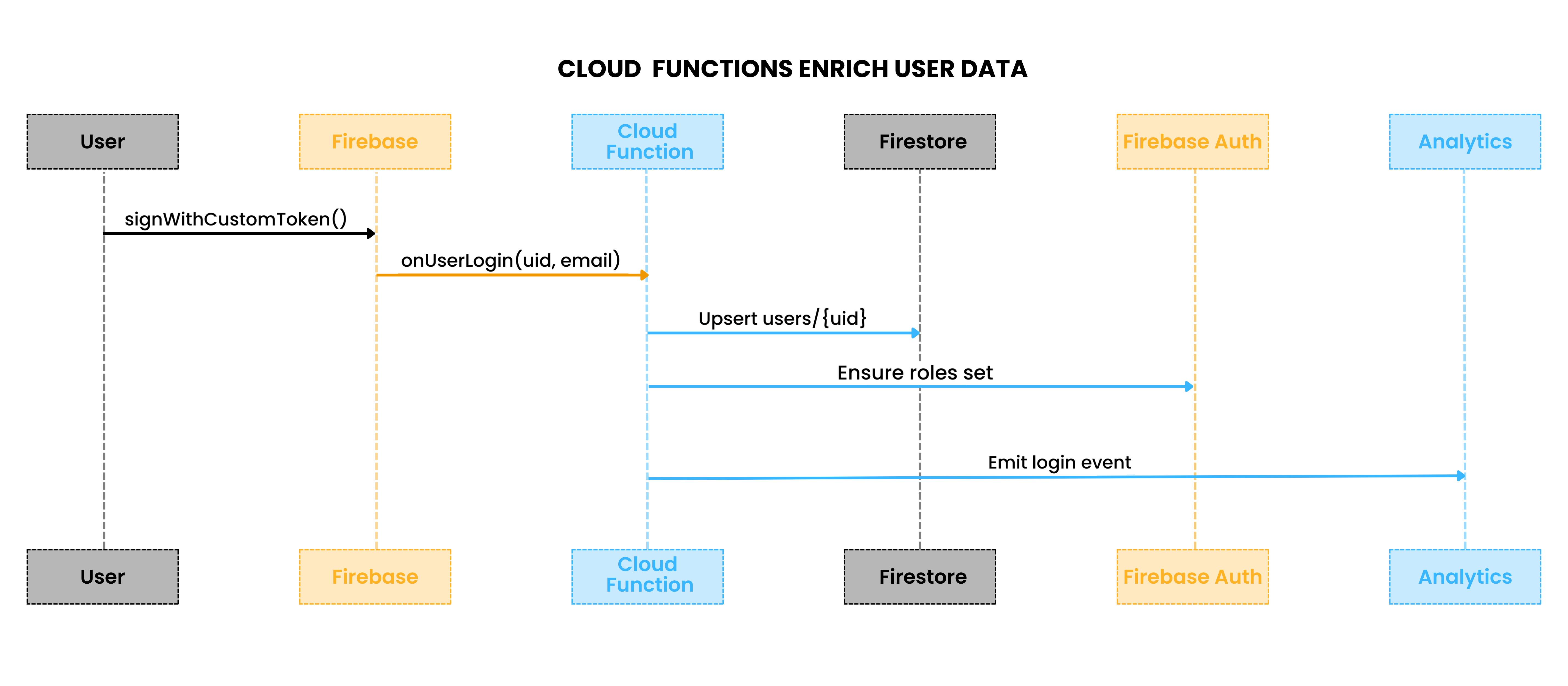
Once Scalekit verifies identity and Firebase accepts it through a custom token, the user has a valid Firebase session. But that only solves the authentication problem. Most applications also need post-login workflows: updating lastLogin, creating default profile records, syncing analytics, or notifying downstream systems. If you cram all of that into your /verify endpoint, you end up with a fragile monolith that grows harder to maintain.
Firebase Cloud Functions are the natural place to handle this logic. They’re event-driven, scale on demand, and have first-class access to Firestore, Authentication, and Analytics. By moving post-login automation into Functions, you keep your authentication path thin and idempotent while still delivering the side effects your app requires.
Triggering post-login logic
The simplest pattern is a callable function that your backend or frontend invokes immediately after a successful Scalekit verification and token mint. For example:
// functions/src/onUserLogin.ts
import * as admin from 'firebase-admin';
import * as functions from 'firebase-functions';
export const onUserLogin = functions.https.onCall(async ({ uid, email }) => {
const now = admin.firestore.FieldValue.serverTimestamp();
// Idempotent upsert , safe on retries
await admin.firestore().doc(`users/${uid}`).set(
{ email, lastLogin: now },
{ merge: true }
);
// Example: attach default roles if missing
const user = await admin.auth().getUser(uid);
if (!user.customClaims?.roles) {
await admin.auth().setCustomUserClaims(uid, { roles: ['basic'] });
}
return { ok: true };
});
This function ensures every login updates Firestore consistently, assigns baseline roles, and stays safe under retries.
Handling heavier workflows
For tasks that don’t need to block login, you can:
Write a Firestore event handler: e.g., functions.firestore.document('users/{uid}').onWrite(...) to trigger downstream sync.
Queue async work: publish to Pub/Sub or enqueue into a task queue for slow operations like billing sync.
Run regional Functions: deploy close to your users to reduce latency on hot paths like login.
Keeping Functions safe and cost-efficient
Idempotency: Always use merge: true Firestore writes and deterministic IDs so retries don’t create duplicates.
Reuse Admin SDK: Initialize once per function instance to avoid memory leaks.
Cold starts: For login-critical functions, set minimum instances to 1 in production.
Monitoring: Export invocation counts and error rates to Cloud Monitoring to catch regressions.
Cloud Functions handle post-login side effects like user upserts, roles, and analytics.
Why this pattern works
Auth stays clean: /verify only verifies identity and issues a token, no business logic mixed in.
Automation is modular: Each Function has one responsibility, making it easier to debug and extend.
Scales with load: When login spikes (e.g., at product launch) occur, functions scale automatically without overloading your backend.
By shifting post-login workflows into Cloud Functions, you avoid brittle, overloaded auth handlers and gain a scalable, observable pipeline that grows with your app. Scalekit handles verification, custom tokens create trust, and Functions ensure your app’s business logic runs reliably after each login.
Firestore user management with Scalekit and Firebase
With Scalekit handling identity verification and Firebase issuing sessions through custom tokens, the next step is managing user data inside Firestore. This is where many teams overcomplicate things: some mirror Scalekit’s entire identity payload, others try to store credentials or verification artifacts directly in Firestore. Both approaches are unnecessary and risky.
The clean model is simple: Firestore should store application state, not authentication proof. Authentication is already handled by Scalekit and enforced by Firebase sessions. Firestore only needs to track the data your app requires to function: profiles, preferences, roles, and metadata like last login.
Returning users update only the fields you care about (e.g., lastLogin).
Roles and preferences aren’t lost during login.
Structuring multi-tenant data
If your app supports multiple organizations, avoid mixing tenant data at the top level. Instead, scope users under tenants:
tenants/{tenantId}/users/{uid}
Your backend should mint custom tokens with a tenantId claim, and Firestore Security Rules should enforce that the uid can only access documents under their tenant.
Best practices for Firestore user management
Normalize emails: Always lowercase before hashing or storing.
Avoid sensitive fields: Never store OTPs, magic links, or Scalekit request IDs.
Version schemas: Use profileVersion to handle migrations without downtime.
Cache wisely: On the client, cache users/{uid} with a TTL (e.g., 10s) + background refresh to minimize Firestore reads.
Partition hot paths: If you log lots of events, store them in subcollections (users/{uid}/events/{eventId}) to avoid bloating the root user doc.
Why this pattern works
Firestore becomes the source of truth for application data, while Scalekit + Firebase handles authentication and enforcement. The schema stays minimal, predictable, and easy to extend. Developers avoid the trap of mixing authentication artifacts into Firestore and can rely on Firebase sessions to protect access.
By treating Firestore as an application state store rather than an identity store, you keep your authentication pipeline clean and your data model future-proof.
Security rules for passwordless authentication with Scalekit and Firebase
At this point, Scalekit verifies the user’s identity, a Firebase custom token establishes trust, and Firestore stores user data. The final layer of defense is Firestore Security Rules. Without strong rules, everything upstream can be bypassed, and an attacker could read or write arbitrary documents just by holding a valid session.
The goal is simple: users should only access their own documents unless explicitly granted more authority. Scalekit ensures the email is real; Firebase sessions provide uid and optional claims; Security Rules enforce least privilege directly at the data layer.
Per-user isolation
The most fundamental pattern is restricting access to a user’s own document:
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userId} {
allow read, write: if request.auth != null && request.auth.uid == userId;
}
}
}
Here:
request.auth.uid is populated automatically when the client signs in with the custom token.
A user can only read and write their own document.
This rule eliminates cross-user data leaks, which are one of the most common Firestore mistakes.
Using custom claims for roles
Sometimes users need elevated privileges, for example, an admin dashboard. Instead of baking this into Firestore documents, assign custom claims when minting the token:
Security Rules gate every Firestore request based on uid and claims, not app code.
Best practices for scalable rules
Keep rules simple: Fewer conditions = less evaluation cost.
Push business logic up: Only enforce identity, roles, and tenant boundaries in rules; do complex checks in Functions.
Avoid over-fetching: Rules run per document read, query only what you need.
Audit frequently: Run rules-unit-testing in CI to prevent regressions.
Why this matters
With these rules in place, Scalekit’s verification and Firebase’s tokens aren’t just authentication; they become authorization gates at the data layer. Even if an attacker steals a session, they can’t escalate across users or tenants. This enforces true least privilege and makes the passwordless flow production-grade.
Optional hardening:
Add Storage rules if you store user assets:
service firebase.storage {
match /b/{bucket}/o {
match /users/{uid}/{file=**} {
allow read, write: if request.auth != null && request.auth.uid == uid;
}
}
}
Analytics integration: Measuring the passwordless funnel end-to-end
Passwordless isn’t “done” when the user signs in; you need visibility across send → verify → session to catch friction and prove impact. With Scalekit + Firebase, instrument both product analytics (user funnel) and operational telemetry (latency, error spikes). Keep personally identifiable info (PII) minimal and consistent.
auth_request_id (ok to log), email hash (not raw email)
Client instrumentation (Firebase Analytics)
Emit product events at user-visible milestones. Never block UX on analytics network calls.
// web/analytics.ts
import { getAnalytics, logEvent } from 'firebase/analytics';
export function logAuthSendStarted(type: 'OTP'|'LINK'|'LINK_OTP') {
logEvent(getAnalytics(), 'auth_send_started', { method: 'scalekit_passwordless', type });
}
export function logAuthVerifySuccess(type: 'OTP'|'LINK'|'LINK_OTP') {
logEvent(getAnalytics(), 'auth_verify_success', { method: 'scalekit_passwordless', type });
}
export function logSigninCompleted(type: 'OTP'|'LINK'|'LINK_OTP') {
logEvent(getAnalytics(), 'signin_completed', { method: 'scalekit_passwordless', type });
}
Where to call:
After /passwordless/email/send returns → auth_send_started
After /passwordless/email/verify returns success → auth_verify_success
After signInWithCustomToken resolves → signin_completed
Server telemetry (structured logs → Cloud Logging/BigQuery)
Capture latency + outcomes for Scalekit verify and token mint; do not log raw emails.
// server/log.ts
import crypto from 'crypto';
function emailHash(email: string) {
return crypto.createHash('sha256').update(email.toLowerCase()).digest('hex');
}
export function logAuthEvent(kind: string, data: Record(<string, unknown>) {
// console.log works with Cloud Run/Functions and is shipped to Cloud Logging.
console.log(JSON.stringify({ ts: Date.now(), kind, ...data }));
}
Logging raw emails or link tokens (PII/security risk).
Mixing product analytics with operational logs in the same schema (hard to query).
Blocking UI on analytics calls.
Outcome: You get a provable, auditable auth funnel. Product sees where users drop, ops spot deliverability or latency regressions, and security keeps PII minimized. This makes the passwordless flow measurable and improvable, without compromising trust.
Migration strategy: Moving existing users to Scalekit + Firebase passwordless
Rolling out a new authentication system is rarely greenfield. Most apps already have a mix of Firebase email/password users, social logins, or even external identity providers. The challenge is adopting Scalekit + Firebase custom tokens without breaking existing accounts, losing historical data, or forcing users to re-register.
The key to a successful migration is to separate identity proof from user records. Scalekit becomes the source of truth for verification, Firebase enforces sessions and rules, and Firestore holds only application data. With that model in place, migration becomes a matter of linking old users to new flows instead of duplicating them.
Step 1: Choose a stable uid mapping
Decide how to map existing users to new Scalekit-verified sessions. Options:
Deterministic hash of email: sha256(lowercase(email)). Works if email is the primary identifier.
Preserve legacy UID: If your Firebase Auth or other system already has UIDs, reuse them. This avoids breaking Firestore references.
Tenant-scoped IDs: For multi-tenant apps, prefix the tenantId: tenant123_userhash.
This mapping must stay consistent across old and new flows.
Step 2: Backfill Firestore user documents
Before enabling Scalekit, seed users/{uid} for every existing user. Example script:
import { admin } from './firebase-admin';
import { readFileSync } from 'fs';
const users = JSON.parse(readFileSync('./legacy-users.json', 'utf8'));
for (const u of users) {
const uid = stableUidFromEmail(u.email);
await admin.firestore().doc(`users/${uid}`).set({
email: u.email,
roles: u.roles ?? ['basic'],
migratedAt: admin.firestore.FieldValue.serverTimestamp()
}, { merge: true });
}
This ensures that the first Scalekit login feels seamless, and the user’s record already exists.
Step 3: Enable dual login temporarily
For a short window, allow both old auth (e.g., Firebase email/password) and Scalekit passwordless. On successful Scalekit login, link the identities by writing to the same Firestore document and minting tokens for the same uid.
This guarantees continuity; users logging in through the old method and the new method see the same data.
Dual-run ensures old and new logins map to the same Firestore records during migration.
Step 4: Cut over to Scalekit
Once confidence is high (low error rates, successful logins across tenants), disable the old provider. In Firebase Console:
Turn off Email/Password, Google, or other unused methods.
Keep only “Custom” (for Scalekit integration).
At this point, Scalekit + Firebase is the single source of truth.
Step 5: Handle edge cases cleanly
Email changes: Use an alias array in Firestore (aliases: [oldEmail]) so old addresses can still map to the same uid until migration completes.
Inactive accounts: Consider forcing re-verification through Scalekit before granting access, cleaning out unused users.
Enterprise tenants: If you support corporate SSO, keep it side-by-side with Scalekit passwordless, but issue Firebase tokens through the same minting path.
Best practices for migration
Communicate clearly: tell users that login is moving to passwordless and why (security, simplicity).
Measure adoption: log how many users sign in via Scalekit vs legacy each week.
Set a sunset date: don’t leave dual login open indefinitely, it doubles complexity.
Back up before cutover: export users and Firestore data to GCS/BigQuery in case rollback is needed.
Why this works
This approach ensures that:
Users transition without losing data.
Firestore references remain intact.
The team gains passwordless benefits without a disruptive “Everyone must sign up again” moment.
Migration becomes an incremental, reversible process, Scalekit takes over identity proof, Firebase continues to enforce trust, and the app evolves without breaking its history.
Cost optimization: Running Scalekit+Firebase passwordless at Scale without bill shock
Authentication flows are sensitive to latency, but they also touch multiple Firebase services: Firestore, Functions, and Analytics. If left unchecked, costs can spiral quickly as logins scale. The goal is to keep the passwordless experience fast for users while ensuring your infrastructure bill remains predictable.
Optimize Firestore usage
Firestore bills by reads/writes. The login flow typically touches:
users/{uid} doc upsert (1 write per login).
Client fetch of users/{uid} (1 read per session).
Occasional queries for tenant dashboards.
Levers to reduce cost:
Cache “who am I” calls: Add a 10s TTL cache client-side with SWR (stale-while-revalidate). Don’t hit Firestore on every render.
Write selectively: Update lastLogin only on successful verifications; skip extra writes during resends or failed attempts.
Aggregate for dashboards: Instead of querying hundreds of users/{uid} docs, maintain a summary doc (tenantStats/{tid}) updated by Cloud Functions.
Tune Cloud Functions
Functions can become the most expensive part of the stack if misconfigured.
Reuse Admin SDK: Initialize admin.initializeApp() once per instance, not per invocation.
Cold starts: For latency-critical auth Functions, set a min instance = 1 in production. It costs a few dollars a month but removes cold-start spikes.
Right-size memory: Don’t default to 512MB/1GB; most login handlers fit in 128–256MB. Lower memory = lower cost.
Batch side effects: If you need to log login events, batch them into a collection and write once per user session instead of once per verification attempt.
Manage indexes wisely
Every Firestore query with inequality or order requires an index. Over time, unused indexes add cost.
Run index audits: Delete unused composite indexes in the Firebase Console.
Prefer flat structures: Query users/{uid} directly instead of deep nested collections where possible.
Limit hot writes: If you log every login event, use partitioning (e.g., shard by day: login_events/{YYYYMMDD}/entries) to spread write load.
Control Analytics overhead
Firebase Analytics is “free” in GA4, but downstream BigQuery exports can get expensive.
Sample logs: For high-volume apps, log 1 in N successful login events to BigQuery.
Keep events minimal: Only capture what’s needed for funnel tracking (send, verify, signin_completed). Don’t log redundant fields.
Use hashed identifiers: Hash emails before sending to analytics to avoid storing PII, which also reduces compliance risk.
Enforce rate limits early
Each failed or spammed attempt consumes Scalekit API calls, Firestore writes, and Function invocations.
Redis sliding window (Or Firestore counter as fallback) on /send and /resend.
UI debounce: Disable “resend” button for 10–15s to avoid duplicate requests.
Align with Scalekit quotas: Scalekit enforces OTP attempt limits; mirror these in UI and logging to prevent runaway costs.
Cost-aware defaults checklist
Cache users/{uid} with TTL to avoid repeat reads.
Write lastLogin only on successful verification.
Use min instances (1–2) only for critical auth Functions.
Audit and prune Firestore indexes quarterly.
Sample analytics exports when scaling beyond thousands of logins/day.
Implement rate limits and resend throttling to control API costs.
Why this matters
Cost optimization isn’t about cutting corners; it’s about making sure your passwordless login scales with users, not with runaway bills. By caching aggressively, trimming writes, right-sizing Functions, and controlling analytics exports, you keep Firebase lean while still delivering a secure, frictionless authentication flow. Scalekit handles verification, Firebase enforces security, and your ops team keeps the budget in check.
Conclusion: Modern authentication without the bloat
Passwordless authentication doesn’t have to mean reinventing your stack. With Scalekit handling identity proof and Firebase enforcing trust, you get the best of both worlds: seamless OTPs and magic links for users, and predictable Security Rules, Functions, and Analytics for developers. Each piece plays its part:
Scalekit → verifies identity with secure, short-lived credentials.
Custom tokens → bridge Scalekit to Firebase sessions.
Firestore + Rules → store only essential user data with least-privilege access.
Functions → automate post-login workflows and enrich user records.
Analytics → measure the funnel, track adoption, and debug failures.
Migration + cost strategies → ensure you can roll this out at scale without breaking users or budgets.
The result is a clean, production-grade architecture: no duplicated identity stores, no brittle hacks, and no flashing sensitive data unauthenticated. Just a modern auth flow that developers can trust and users actually enjoy.
Ready to modernize your login flow?
Start by setting up your Firebase project with Firestore, Functions, and Analytics configured for Scalekit integration. Then layer in Scalekit’s passwordless APIs, mint Firebase custom tokens, and let Security Rules do the heavy lifting.
You’ll eliminate password resets, reduce support overhead, and ship a login experience that scales with your app. Check out Scalekit’s documentation and start building your passwordless Firebase integration today.
FAQ
1. How does Scalekit handle OTP and magic link security to prevent replay or phishing attacks?
Scalekit generates short-lived, single-use tokens tied to an auth_request_id. OTPs expire after a fixed window, and magic links can be configured with same-origin enforcement so they only verify from the intended app domain. This prevents token replay across environments and reduces phishing risk.
2. Can Scalekit passwordless authentication coexist with enterprise SSO in the same Firebase project?
Yes. Scalekit can handle OTP/magic link flows for end-users while enterprise tenants authenticate via SAML or OIDC. Both ultimately mint Firebase custom tokens, ensuring Firestore Security Rules and Cloud Functions see a unified uid + claims model regardless of identity source.
3. How do Firebase custom tokens impact Firestore Security Rules performance at scale?
Custom tokens don’t slow down queries directly; once exchanged, Firebase sessions behave like native logins. However, attaching too many claims (large JWTs) can increase rule evaluation cost. Keep claims coarse-grained (roles, tenantId) and push fine-grained checks into Firestore documents.
4. What’s the best way to migrate Firebase email/password users to passwordless without losing their Firestore references?
Use deterministic UID mapping. For example, preserve existing Firebase Auth UIDs as the primary key, then map Scalekit logins to those UIDs during token minting. This ensures Firestore document paths (users/{uid}) remain unchanged, avoiding data duplication or broken references.
5. How can Cloud Functions be optimized for authentication workflows to reduce cold start latency?
Deploy critical auth functions (e.g., post-login upserts) with a small minInstances setting to keep at least one container warm. Combine that with lightweight memory tiers (128–256MB) and shared Admin SDK initialization. This balances low latency with controlled runtime costs.
Want to add secure passwordless login to your Firebase app? Sign up for a free Scalekit account to verify users with OTPs or magic links and mint custom tokens your Firebase project trusts . Have questions? Book a call with our auth experts.