.webp)


Provisioning and deprovisioning users is a baseline requirement for SaaS platforms integrating with enterprise identity providers. Standards like SCIM 2.0 are expected by default when selling to companies using Okta, Azure AD, or Google Workspace for user identity and access management. SCIM enables identity providers to automatically create, update, and disable users without manual effort.
The protocol seems simple at first — just a few REST endpoints and a JSON schema — but real-world implementations quickly get complex. PATCH handling, strict filter syntax, schema mapping, multi-tenancy, and IDP-specific quirks all introduce subtle but critical challenges.
SCIM appears lightweight, but identity providers expect full compliance with RFC 7643 and RFC 7644. Misinterpreted PATCH payloads, missing metadata, or inconsistent filtering logic are common causes of failed integrations, and most of them don’t surface until after deployment.
This guide covers how to build a SCIM 2.0-compliant API from scratch, including edge cases, validation, and testing, as well as when it makes more sense to use a production-ready SCIM connector like Scalekit.
SCIM stands for System for Cross-domain Identity Management. It’s a standard that defines how identity providers (IdPs) like Okta or Azure AD communicate user and group information to external SaaS applications.
The protocol is defined across two key RFCs:
At its core, SCIM is a CRUD-style API that operates on standardized resource types, most commonly User and Group. All SCIM requests and responses use the media type application/scim+json, enabling consistent provisioning of users across systems.
To support SCIM 2.0, an app must implement a minimal set of endpoints:
GET /Users → List users with optional filtering/pagination
POST /Users → Create a new user
GET /Users/{id} → Retrieve a specific user
PATCH /Users/{id} → Partially update user attributes
DELETE /Users/{id} → Deactivate or delete a user
The protocol includes specific expectations for:
SCIM is not just about exposing CRUD operations — it enforces strict schema and behavior contracts, and identity providers will reject or fail to sync if those aren't followed exactly.
A SCIM server is just an HTTP API that conforms to RFC 7644, exposing API endpoints for automatic provisioning and lifecycle management of user accounts.
Choose a backend framework that gives you control over routing, JSON handling, and middleware. Popular choices include Express (Node.js), Flask or FastAPI (Python), and Go’s standard net/http.
At minimum, your server needs to expose critical Users endpoints under a versioned path like /scim/v2:
Authentication is required for all SCIM endpoints. Identity providers support:
Use a secure mechanism to verify these credentials on every request, and reject unauthenticated access with a 401 Unauthorized status.
For multi-tenant applications, route requests to the correct organization context based on a shared secret, subdomain, or token-based mapping. Identity providers don’t pass tenant info explicitly, so you’ll need to infer it from the request headers or credentials.
The SCIM User object is defined in RFC 7643 and includes a fixed set of common attributes that must be returned in every user response. Your API responses must match this structure exactly, or identity providers will reject the payload.
A minimal SCIM-compliant user object includes fields like:
Your internal user model may not have all these fields. You’ll need to:
For extensibility, SCIM supports extension schemas via the schemas array, allowing enterprise-specific fields and additional custom attributes. These are typically used for tenant-specific attributes, like department codes or external system IDs.
SCIM’s CRUD operations follow a REST-style interface, but the behavior expected by identity providers is strict and predictable. Your implementation must fully conform to the SCIM 2.0 spec, or provisioning may silently fail.
The GET /Users API should list collections of users based on filter query parameters, supporting both pagination and sorting.
List users with support for:
Example response structure:
Create a new user in your system using the SCIM-compliant request body. The userName field is required and must be unique. You must return the full user object, including metadata and the generated id. A POST /Users sample request must conform exactly to the SCIM common user schema expectations and return a fully-formed response body.
Return status: 201 Created
The response should match the structure of GET /Users/{id}, including metadata.
Deletion can be interpreted in two ways:
Most identity providers tolerate either approach, but your implementation should be consistent. If you soft-delete, update the active attribute, and respond with 200 OK.
If the user doesn’t exist, return 404 Not Found.
Real-world SCIM integrations often break at this layer due to incorrect pagination, missing metadata, or inconsistent field mapping. It’s critical to validate every response against the spec.
PATCH is the most complex part of the SCIM protocol. Unlike a full PUT, SCIM's PATCH allows partial updates using a structured array of operations, and every identity provider constructs these requests a bit differently.
Each SCIM PATCH request includes:
🚨Be careful when handling replace operations, many IDPs send the entire resource object even for small changes to specific fields.
SCIM clients rely on query parameters like filter, sortBy, and count to fetch subsets or sort collections of users during synchronization. Your API must interpret these parameters precisely, or risk failed or incomplete provisioning.
SCIM defines a restricted query language for filters:
You must parse the filter query parameter from the URL and apply it to your internal user store.
Example:
GET /Users?filter=userName eq "alice@example.com"
Always validate the filter query parameter and restrict it to known SCIM fields to avoid injection risks.
Support the sortBy and sortOrder parameters:
GET /Users?sortBy=userName&sortOrder=descending
Invalid or unsupported query parameters should return a proper SCIM error response with 400 Bad Request.
Support startIndex (1-based) and count:
GET /Users?startIndex=1&count=100
Response must include:
Example:
SCIM endpoints manage account creation and deletion, meaning they sit at a sensitive point in your infrastructure. Exposing them without proper security is a serious risk.
All SCIM traffic must be served over HTTPS. Identity providers like Okta and Azure AD reject non-TLS endpoints and may not attempt provisioning if the server is not HTTPS-secured.
Most identity providers support:
For basic auth, validate the credentials against your internal tenant mapping. For bearer tokens, verify:
Reject unauthorized requests with a 401 Unauthorized. Do not expose implementation details in error messages.
To prevent abuse or accidental overload:
Use IP whitelisting if required by your IDP or internal policy.
Log:
Do not log:
🚨When returning errors, limit exposure; your response body should include only the SCIM-defined fields like detail and status, never stack traces or internal exceptions.
Harden input handling:
Use short-lived Bearer tokens to limit exposure and enforce strict validation on fields like filter and sortBy. Only allow expected attribute names and sanitize all inputs to prevent injection or misuse.
SCIM integrations often break not because of missing features, but because of subtle spec mismatches. Testing your SCIM server as if you were Okta or Azure AD is the only reliable way to catch these issues before production. Testing SCIM servers with real-world sample requests helps surface protocol mismatches before identity providers begin automatic provisioning in production.
Simulate these operations in order:
Use tools like:
Okta and Azure AD both use specific PATCH payload structures that may include:
Test these real-world cases against your server and log exactly what’s received and returned. Validate real-world Okta and Azure AD flows, including PATCH structures that replace current attributes or add new attribute values.
Return appropriate status codes for these scenarios:
Ensure error responses include the SCIM error schema:
SCIM integrations are rarely one-off. Once you onboard one enterprise customer, others will follow, each with their own identity provider, provisioning rules, and expectations. Your SCIM server must be built for repeatable, tenant-aware provisioning. For multi-tenant environments, you must map incoming SCIM calls to the correct enterprise organization based on auth credentials or subdomains.
Identity providers don’t send explicit tenant IDs. You must infer the target organization by:
Ensure all operations are scoped correctly. A PATCH request from Okta Org A should never modify users from Org B. Your SCIM server must support tenant-specific logic, enforcing role mappings, domain restrictions, and validation of access levels assigned to user accounts.
Enterprise customers often need tenant-specific mappings, like default roles, restricted email domains, or required custom attributes. Your SCIM server must allow for flexible configuration per tenant to meet these demands.
Track request metrics (method, status, latency) and expose KPIs like provisioning success rate and patch error rate per org to detect issues early.
Building a SCIM 2.0 endpoint gives full control but adds long-term costs: spec compliance, IDP-specific testing, edge case debugging, and protocol maintenance.
A SCIM connector abstracts away the need to build and maintain your own SCIM-compliant Client, while providing reliable cross-IDP support at a predictable flat rate. It provides a prebuilt implementation of the SCIM protocol that your app can plug into, often with multi-IDP support and built-in tenant routing.
Here’s how in-house builds compare with Scalekit’s SCIM connector:
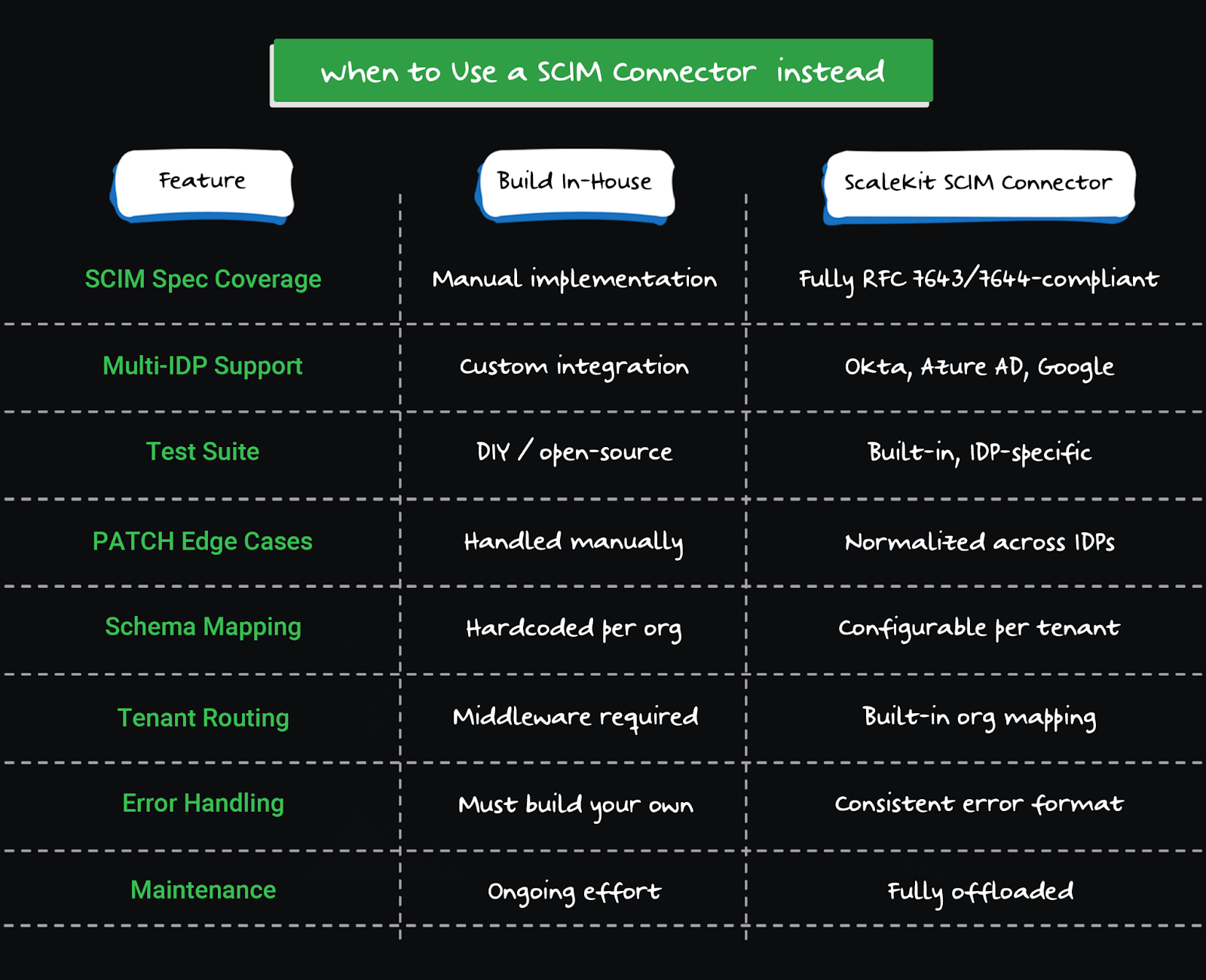
⚡ Want to skip protocol debugging and get SCIM working in hours? Explore Scalekit’s SCIM Connector, production-ready out of the box.
SCIM integrations don’t fail because teams can’t build APIs — they fail because edge cases never end, the spec is strict, and each identity provider behaves slightly differently. Supporting SCIM 2.0 means more than returning JSON. It means speaking a common language of standardized schemas, filters, and API behavior that scales across Okta, Azure AD, and Google Workspace — without breaking sync or delaying onboarding.
This guide outlined how to build a SCIM endpoint from scratch: compliant routes, schema mapping, PATCH logic, security, and multi-tenant routing. If you’re building in-house, this is your blueprint. But if you’re tight on time or tired of integration bugs, you don’t have to go it alone.
Scalekit’s SCIM Connector is production-ready, tested across major IDPs, and built to normalize tenant behavior. Start provisioning users in hours, and stay focused on your product while Scalekit handles the protocol.
SCIM (System for Cross-domain Identity Management) enables identity providers like Okta or Azure AD to automatically provision, update, and deprovision users in SaaS applications. It removes the need for manual account management and ensures users have the right access at the right time.
SCIM PATCH operations use an array-based syntax with support for add, remove, and replace, often targeting nested or multi-valued attributes. Each IDP structures these requests slightly differently, and handling all cases correctly requires a deep understanding of both the SCIM spec and real-world IDP behavior.
Technically yes, but most identity providers expect full support for at least GET, POST, PATCH, and DELETE on the /Users resource. Partial implementations may pass initial validation but often break in production sync flows.
SCIM doesn’t include a tenant ID in requests. You need to infer the tenant context based on the authentication method (e.g., Basic Auth credentials, Bearer token claims) and route each request to the appropriate org. This is critical to avoid cross-tenant data leakage.
Yes. You can use tools like Postman, curl, SCIM test harnesses, or simulate real-world identity provider requests using Okta’s SCIM connector builder. Scalekit also provides a built-in test suite for validating SCIM behavior before going live.
Building a SCIM endpoint is deceptively complex—PATCH handling, strict RFC compliance and multi‑tenant routing can derail integrations . Skip the spec‑wrangling by signing up for a free Scalekit account; our production‑ready SCIM connector handles tenant isolation, compliant CRUD operations and patch normalization across Okta, Azure AD and Google Workspace . Want help designing or rolling out SCIM provisioning? Book time with our experts to get it right the first time.






